by jsendak | Apr 29, 2024 | DS Articles
Ready for a change in industry, title or an increased salary?
Analysis of the fundamental takeaways
The original text raises primary points about change in industry or title, and potentially better compensation. This is inherently a topic concerned with personal career advancement and evolving market scenarios. The long-term implications of these considerations are significant, particularly keeping in mind the volatile job market conditions aroused by global factors like digital revolution, automation, pandemic impact, and continuous disruption in traditional industries.
Potential future trends and developments
Faster-than-ever changes in technology, workforce dynamics and industry landscapes suggest that career shifts may become more common in the future. The rise of remote work is eliminating geographical barriers, promoting cross-industry movement and enabling people to explore positions outside of their traditional sectors. The combination of these elements means that an individual’s ability to adapt and continuously learn new skills will likely be detrimental in aiding their career progression and maintaining job security.
Advice for future opportunities in changing industries or roles
Embrace lifelong learning
As jobs become more complex and interconnected, knowledge and skills need continuous renovation. With online courses and resources widely available, there’s no reason to stop learning. Always stay current with the latest developments in your field.
Network strategically
Your network can provide opportunities, advice, and information. Maintain an active presence in industry associations, online forums, and social media platforms related to your targeted industries.
Adaptability
The rate of business and industrial change is going to accelerate. The more adaptable you are, the more attractive you will be to potential employers. Adaptability can showcase that you’re able to handle uncertainties in the market, evolving technological trends, and shifts in job duties.
Demonstrate transferable skills
Look past job titles and consider the skills you have that are applicable across industries. Skills like project management, leadership, communication, and problem-solving are universal and can be mentioned prominently on your resume.
Note: Your personal value proposition needs to constantly evolve. Understand your strengths, acknowledge your weaknesses, and prepare for the market’s future needs.
With the correct mindset and the appropriate strategy, change in industry or title can be a promising step toward realizing your career goals, including an increased salary. While change is always challenging, the opportunities it brings are enormous.
Read the original article
by jsendak | Apr 29, 2024 | DS Articles

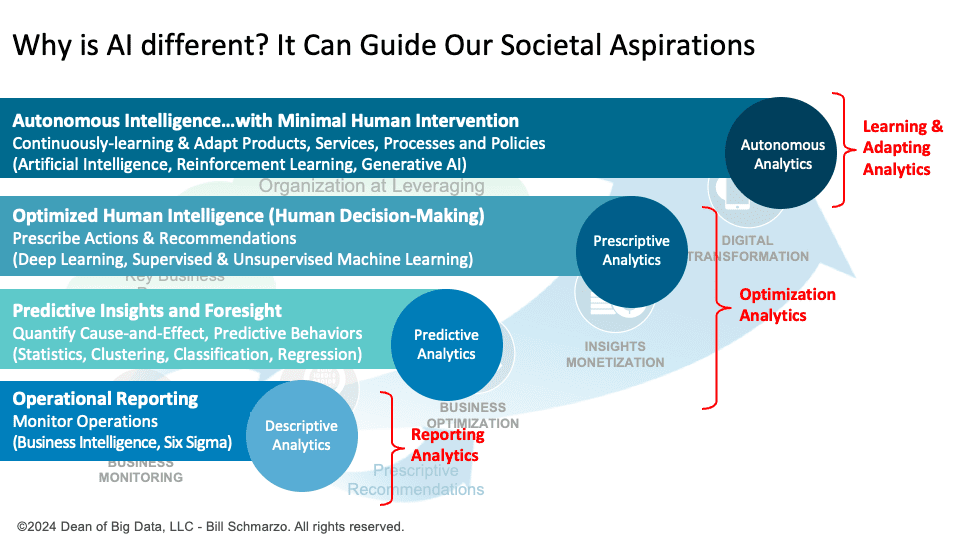
Traditional analytics optimize based on existing data, reflecting past realities, limitations, and biases. In contrast, AI focuses on future aspirations, identifying the learning needed to achieve aspirational outcomes and guiding your evolution toward these outcomes. When I talk to my students, the question I keep getting is, “Is AI really different from traditional analytics?” My… Read More »Why is AI different? It Can Guide Our Societal Aspirations
Understanding the Differences Between Traditional Analytics and Artificial Intelligence
Traditional analytics and Artificial Intelligence (AI) may seem similar on surface, both leveraging data to generate insights. However, these technologies differ in fundamental ways that drive significant outcomes for business strategies, societal advancements, and individual aspirations.
Traditional analytics optimize based on existing data, reflecting past realities, limitations, and biases. In contrast, AI focuses on future aspirations, identifying the learning needed to achieve aspirational outcomes and guiding your evolution toward these outcomes.
Long-term Implications
The capabilities of AI far exceed those of traditional analytics, with potential implications spanning multiple sectors and influencing societal aspirations. The shift from a past-reflecting perspective to a forward-looking one has transformative potential. In the long term, AI could guide more than just business decision-making; it could steer societal evolution in domains such as medicine, education, and environmental sustainability.
Future Developments in AI
As AI matures, we could start seeing its wider implementation, not just in industrial applications, but also in personal and societal aspects. AI-guided learning could become more prevalent in education, and AI could also offer personalized health recommendations based on individual’s data. In environmental front often marked by uncertainties, AI could help predict outcomes based on various climate models and interventions.
Actionable Advice
With AI’s vast potential, key actions can be taken to ensure we are positioning ourselves to maximize its benefits and mitigate potential challenges.
- Embrace Lifelong Learning: Given AI’s rapidly evolving nature, it’s vital to embrace a mindset of lifelong learning to keep pace with its advancements.
- Apply Ethically: As AI comes with huge potential, it’s equally critical to consider the ethical implications of its applications. This means ensuring fairness, transparency, and accountability in AI deployment.
- Invest Wisely: Organizations should invest in AI technologies that align with their strategic objectives and that they have the capabilities to implement successfully.
- Optimize Data Management: Data is the lifeblood of AI. Businesses ought to optimize data management practices to harness the full potential of AI.
In conclusion, the future of AI offers endless possibilities. It’s upon us to harness its potential responsibly and effectively as a means of shaping aspirational outcomes not just for our businesses, but for the wider society as well.
Read the original article
by jsendak | Apr 29, 2024 | AI
arXiv:2404.16845v1 Announce Type: new Abstract: Internet image collections containing photos captured by crowds of photographers show promise for enabling digital exploration of large-scale tourist landmarks. However, prior works focus primarily on geometric reconstruction and visualization, neglecting the key role of language in providing a semantic interface for navigation and fine-grained understanding. In constrained 3D domains, recent methods have leveraged vision-and-language models as a strong prior of 2D visual semantics. While these models display an excellent understanding of broad visual semantics, they struggle with unconstrained photo collections depicting such tourist landmarks, as they lack expert knowledge of the architectural domain. In this work, we present a localization system that connects neural representations of scenes depicting large-scale landmarks with text describing a semantic region within the scene, by harnessing the power of SOTA vision-and-language models with adaptations for understanding landmark scene semantics. To bolster such models with fine-grained knowledge, we leverage large-scale Internet data containing images of similar landmarks along with weakly-related textual information. Our approach is built upon the premise that images physically grounded in space can provide a powerful supervision signal for localizing new concepts, whose semantics may be unlocked from Internet textual metadata with large language models. We use correspondences between views of scenes to bootstrap spatial understanding of these semantics, providing guidance for 3D-compatible segmentation that ultimately lifts to a volumetric scene representation. Our results show that HaLo-NeRF can accurately localize a variety of semantic concepts related to architectural landmarks, surpassing the results of other 3D models as well as strong 2D segmentation baselines. Our project page is at https://tau-vailab.github.io/HaLo-NeRF/.
The article “Internet image collections and the role of language in exploring tourist landmarks” explores the potential of internet image collections in enabling digital exploration of large-scale tourist landmarks. While previous works have focused on geometric reconstruction and visualization, this article highlights the importance of language in providing a semantic interface for navigation and understanding. The authors present a localization system that connects neural representations of scenes with text describing specific semantic regions within the scene. By leveraging large-scale internet data and vision-and-language models, the authors aim to enhance the understanding of architectural landmarks. The results of their approach, called HaLo-NeRF, demonstrate its ability to accurately localize various semantic concepts related to architectural landmarks, surpassing other 3D models and strong 2D segmentation baselines.
An Innovative Approach to Enhancing Semantic Understanding of Large-Scale Landmarks
Exploring large-scale tourist landmarks through internet image collections has the potential to revolutionize digital navigation and understanding. However, existing research has mainly focused on geometric reconstruction and visualization, overlooking the crucial role of language in providing a semantic interface for navigation and in-depth comprehension.
In recent years, vision-and-language models have emerged as powerful tools in constrained 3D domains, offering a strong grasp of visual semantics. However, these models often struggle with unconstrained photo collections of tourist landmarks due to their lack of expert knowledge in the architectural domain.
Addressing this limitation, we present a localization system that combines neural representations of scenes depicting large-scale landmarks with text descriptions of semantic regions within the scenes. By harnessing state-of-the-art vision-and-language models, customized for understanding landmark scene semantics, our system bridges the gap between visual and linguistic information.
To enhance the knowledge base of these models, we leverage a vast amount of internet data consisting of images of similar landmarks accompanied by loosely related textual information. We believe that images physically grounded in space can serve as a powerful supervision signal for localizing new concepts. By unlocking the semantics from internet textual metadata using sophisticated language models, our system achieves a more comprehensive understanding.
To achieve this, we utilize correspondences between different views of scenes to bootstrap spatial understanding and guide 3D-compatible segmentation. This process ultimately leads to the creation of a volumetric representation of the landmark scene, providing highly accurate localization of various semantic concepts.
Through comprehensive testing, our approach, known as HaLo-NeRF, has demonstrated superior localization abilities compared to other 3D models and strong 2D segmentation baselines. By combining the power of vision-and-language models with fine-grained architectural knowledge, HaLo-NeRF opens up new possibilities for digital exploration and understanding of large-scale landmarks.
To learn more about our exciting project and explore our results, please visit our project page at https://tau-vailab.github.io/HaLo-NeRF/.
The paper titled “HaLo-NeRF: Harnessing Large-scale Internet Data for Semantic Localization of Architectural Landmarks” addresses the limitations of existing methods that focus on geometric reconstruction and visualization in internet image collections. These collections contain photos taken by crowds of photographers and offer potential for digital exploration of tourist landmarks. However, these prior works neglect the crucial role of language in providing a semantic interface for navigation and fine-grained understanding.
The authors propose a localization system that connects neural representations of scenes depicting large-scale landmarks with text describing a specific semantic region within the scene. They achieve this by leveraging state-of-the-art vision-and-language models and adapting them to understand landmark scene semantics. To enhance these models with fine-grained knowledge, they utilize large-scale internet data containing images of similar landmarks along with weakly-related textual information.
The approach is based on the idea that physically grounded images can provide a supervision signal for localizing new concepts, which can be extracted from textual metadata using large language models. By establishing correspondences between different views of scenes, the authors bootstrap spatial understanding of these semantics, providing guidance for 3D-compatible segmentation that ultimately leads to a volumetric scene representation.
The results of their experiments, presented under the name HaLo-NeRF, demonstrate the system’s ability to accurately localize various semantic concepts related to architectural landmarks. It outperforms other 3D models and strong 2D segmentation baselines in terms of accuracy.
This research is significant as it bridges the gap between visual and linguistic understanding of large-scale tourist landmarks. By incorporating both visual and textual information, the proposed system offers a more comprehensive and semantic approach to exploring and navigating these landmarks. The ability to accurately localize semantic concepts within images can greatly enhance the user experience in virtual tours, cultural preservation, and architectural research.
Moving forward, it would be interesting to see how this approach could be applied to other domains beyond architectural landmarks. Additionally, further research could explore the scalability of the system to handle even larger internet image collections and investigate the potential of incorporating other sources of textual information, such as social media posts or historical texts, to expand the system’s knowledge and understanding.
Read the original article
by jsendak | Apr 29, 2024 | Computer Science
arXiv:2404.17151v1 Announce Type: new
Abstract: Bottom-up text detection methods play an important role in arbitrary-shape scene text detection but there are two restrictions preventing them from achieving their great potential, i.e., 1) the accumulation of false text segment detections, which affects subsequent processing, and 2) the difficulty of building reliable connections between text segments. Targeting these two problems, we propose a novel approach, named “MorphText”, to capture the regularity of texts by embedding deep morphology for arbitrary-shape text detection. Towards this end, two deep morphological modules are designed to regularize text segments and determine the linkage between them. First, a Deep Morphological Opening (DMOP) module is constructed to remove false text segment detections generated in the feature extraction process. Then, a Deep Morphological Closing (DMCL) module is proposed to allow text instances of various shapes to stretch their morphology along their most significant orientation while deriving their connections. Extensive experiments conducted on four challenging benchmark datasets (CTW1500, Total-Text, MSRA-TD500 and ICDAR2017) demonstrate that our proposed MorphText outperforms both top-down and bottom-up state-of-the-art arbitrary-shape scene text detection approaches.
Analysis: Novel Approach for Arbitrary-Shape Text Detection
Text detection in images is a challenging task, especially when dealing with texts of arbitrary shapes. In this article, the authors present a novel approach called “MorphText” to address two major issues in bottom-up text detection methods: the accumulation of false text segment detections and the difficulty of building reliable connections between text segments.
The Role of Deep Morphology in Text Detection
MorphText tackles these problems by leveraging deep morphology. The authors propose two deep morphological modules: Deep Morphological Opening (DMOP) and Deep Morphological Closing (DMCL).
The DMOP module plays a crucial role in removing false text segment detections that occur during the feature extraction process. By applying deep morphology techniques, the module is able to identify and eliminate these false detections, thereby improving the accuracy of subsequent processing steps.
The DMCL module, on the other hand, is designed to establish reliable connections between text segments. It allows text instances of various shapes to stretch their morphology along their most significant orientation, ensuring that their connections are accurately derived. This is a key aspect of text detection, as it enables the detection of text in non-linear and curved shapes.
Evaluating Performance on Benchmark Datasets
To evaluate the performance of MorphText, the authors conducted extensive experiments on four challenging benchmark datasets: CTW1500, Total-Text, MSRA-TD500, and ICDAR2017. These datasets cover a wide variety of text scenarios, including texts of different shapes, sizes, orientations, and background clutter.
The results of the experiments demonstrate the effectiveness of MorphText in outperforming both top-down and bottom-up state-of-the-art arbitrary-shape scene text detection approaches. This highlights the potential of deep morphology in improving the accuracy and robustness of text detection algorithms.
Relation to Multimedia Information Systems and Virtual Realities
The concepts presented in this article have strong interdisciplinary connections to the fields of multimedia information systems and virtual realities. Text detection is a fundamental component of multimedia information systems, where the accurate extraction and understanding of text from images and videos are essential for effective content retrieval and indexing.
Furthermore, the ability to detect text in arbitrary shapes is particularly important in the context of virtual realities. In virtual reality environments, text may appear on curved surfaces, irregular objects, or within complex scenes. By incorporating deep morphology, as demonstrated in MorphText, virtual reality applications can improve the synthesis of text elements onto these diverse surfaces, enhancing the overall immersion and user experience.
Conclusion
The novel approach presented in this article, MorphText, showcases the potential of deep morphology in addressing the challenges of arbitrary-shape text detection. By leveraging the Deep Morphological Opening and Closing modules, MorphText successfully tackles the accumulation of false text segment detections and the establishment of reliable connections between text segments.
The promising results obtained from benchmark dataset evaluations reinforce the importance of this research in advancing the field of text detection. Furthermore, the interdisciplinary nature of these concepts highlights their relevance to multimedia information systems, animations, artificial reality, augmented reality, and virtual realities.
Read the original article
by jsendak | Apr 29, 2024 | AI
arXiv:2404.16957v1 Announce Type: new
Abstract: The pervasive integration of Artificial Intelligence (AI) has introduced complex challenges in the responsibility and accountability in the event of incidents involving AI-enabled systems. The interconnectivity of these systems, ethical concerns of AI-induced incidents, coupled with uncertainties in AI technology and the absence of corresponding regulations, have made traditional responsibility attribution challenging. To this end, this work proposes a Computational Reflective Equilibrium (CRE) approach to establish a coherent and ethically acceptable responsibility attribution framework for all stakeholders. The computational approach provides a structured analysis that overcomes the limitations of conceptual approaches in dealing with dynamic and multifaceted scenarios, showcasing the framework’s explainability, coherence, and adaptivity properties in the responsibility attribution process. We examine the pivotal role of the initial activation level associated with claims in equilibrium computation. Using an AI-assisted medical decision-support system as a case study, we illustrate how different initializations lead to diverse responsibility distributions. The framework offers valuable insights into accountability in AI-induced incidents, facilitating the development of a sustainable and resilient system through continuous monitoring, revision, and reflection.
Analysis of the Content: Computational Reflective Equilibrium for Responsibility Attribution in AI-Enabled Systems
The rapid integration of Artificial Intelligence (AI) in various domains has brought about numerous challenges in terms of responsibility and accountability, especially in the event of incidents involving AI-enabled systems. This paper introduces a novel approach called Computational Reflective Equilibrium (CRE) to address these challenges and establish a coherent and ethically acceptable responsibility attribution framework for all stakeholders.
The article highlights the complexity of responsibility attribution in AI-induced incidents. Interconnectivity of these systems, coupled with ethical concerns and uncertainties surrounding AI technology, further complicate the task. It emphasizes the need for a computational approach that can analyze dynamic and multifaceted scenarios effectively, offering explainability, coherence, and adaptivity in the responsibility attribution process.
The proposed CRE framework offers valuable insights into accountability in AI-induced incidents by integrating a structured computational analysis. This multi-disciplinary approach takes into account various factors, including the initial activation level associated with claims in equilibrium computation. By considering different initializations, the framework demonstrates how responsibility distributions can vary in AI-assisted medical decision-support systems.
The significance of this research is its potential to address the lack of regulations and guidelines in determining responsibility in AI incidents. By providing a comprehensive and adaptable framework, it promotes the development of sustainable and resilient systems through continuous monitoring, revision, and reflection. This approach encourages stakeholders to collaborate and establish an ethically acceptable responsibility attribution process.
Interdisciplinary Nature of the Concepts
The concepts discussed in this article highlight the multi-disciplinary nature of responsibility attribution in AI-enabled systems. The integration of AI technology in various domains requires expertise from diverse fields, including computer science, ethics, law, and philosophy.
From a computer science perspective, the computational approach proposed in the CRE framework allows for efficient analysis of complex scenarios by leveraging AI algorithms and techniques. It provides a systematic way to evaluate the responsibility distribution and ensures transparency in decision-making processes.
Ethics plays a crucial role in determining the ethical acceptability of responsibility attribution frameworks. The ethical concerns associated with AI-induced incidents, such as algorithmic bias and privacy violations, need to be addressed to establish trust and accountability. The CRE framework emphasizes the importance of ethically acceptable responsibility attribution and offers a structured approach to align AI systems with ethical considerations.
The legal dimension of responsibility attribution is also essential in defining liability and accountability in AI incidents. The absence of corresponding regulations for AI technology creates challenges in determining legal responsibilities. The CRE framework can provide a foundation for developing future legal frameworks by offering a transparent and adaptable responsibility attribution process.
Lastly, philosophy contributes to the conceptual underpinnings of responsibility attribution. The CRE framework incorporates reflective equilibrium, a philosophical concept rooted in balancing conflicting claims and beliefs. This integration allows for a coherent and justifiable responsibility attribution process, considering various perspectives and values.
Future Directions
While the proposed CRE framework presents a pioneering approach to responsibility attribution in AI-enabled systems, there are several avenues for further research and development.
Firstly, the computational analysis of responsibility attribution could benefit from advancements in AI explainability. By enhancing the interpretability of AI systems, it becomes easier to understand the reasoning behind responsibility distributions and ensure fairness and transparency.
Secondly, extending the framework to include real-world case studies from different domains would enhance its applicability and practical value. Each domain may pose unique challenges and ethical considerations, and analyzing them within the CRE framework would provide domain-specific insights.
Additionally, exploring the integration of stakeholder perspectives and values in responsibility attribution can further enhance the ethical acceptability of the framework. Incorporating diverse viewpoints and allowing for stakeholder input can lead to fairer responsibility distributions.
In conclusion, the Computational Reflective Equilibrium (CRE) framework offers a novel and multi-disciplinary approach to responsibility attribution in AI-enabled systems. By addressing the complexities and uncertainties associated with AI-induced incidents, it promotes ethical acceptability and contributes to the development of sustainable and resilient AI systems.
Read the original article