Art has always been a powerful medium for expressing social and political commentary. In recent years, the intersection of art and immigration has become increasingly prevalent in the public discourse. The recent stunts by performance artist Marina Abramović and anonymous artist Banksy at the Glastonbury music festival in the UK are indicative of the potential future trends in this field.
The Power of Silence
Marina Abramović’s performance, where she led the crowd in seven minutes of silence, demonstrated the potential of silence as a medium for communicating a message. In a world saturated with noise and constant stimulation, silence has the power to create a profound impact. This type of performance can be seen as a reflection of the growing need for contemplation and reflection in today’s fast-paced world.
Mimicking Migrant Experiences
Banksy’s stunt of sending an inflatable raft into the crowd during a performance by the band Idles drew attention to the issue of immigration. The use of an inflatable raft and dummies resembling migrants highlights the perilous journeys many migrants undertake in search of a better life. This thought-provoking artwork serves as a reminder of the challenges faced by migrants and encourages empathy and understanding.
Art as a Platform for Political Commentary
Banksy’s previous artwork depicting immigration and his latest stunt at Glastonbury emphasize the role of art as a platform for political commentary. Artists are increasingly using their work to raise awareness and spark conversations about important social and political issues. As governments around the world face scrutiny over their immigration policies, we can expect to see more artists tackling this subject to encourage dialogue and inspire change.
Artist Anonymity and Authenticity
Banksy, known for his elusive identity, has not officially claimed authorship of the stunt at Glastonbury. This raises questions about the role of artist anonymity and authenticity in the art world. Banksy’s refusal to conform to traditional standards of artist recognition adds a layer of intrigue to his work and allows it to speak for itself. This trend of anonymous artists challenging established norms and expectations is likely to continue in the future, as artists seek alternative ways to engage with their audience and challenge the status quo.
Predictions and Recommendations
Based on these recent events and trends, several predictions and recommendations can be made for the art and immigration industry:
Increased Use of Non-Traditional Art Forms: Artists will continue to explore non-traditional mediums to convey their messages and engage with their audience. This may include performances, installations, and interactive experiences that evoke emotions and encourage reflection.
Collaboration Between Artists and Activists: We can expect to see more collaborations between artists and activists working towards social and political change. By combining artistic expression with activism, these partnerships have the potential to amplify the impact of both.
Emphasis on Authenticity: The demand for authentic and genuine artistic expression will continue to grow. Audiences are increasingly drawn to artists who are unafraid to tackle controversial issues and express their unique perspectives, even if it means challenging established norms.
Art as Catalyst for Dialogue: Art has the power to transcend boundaries and provoke conversations. We can anticipate a rise in art exhibitions, performances, and events that encourage dialogue and understanding among people from diverse backgrounds.
Support for Emerging Artists: As the art world evolves, there will be a greater need to support emerging artists who bring fresh perspectives and innovative approaches. Organizations and institutions should prioritize funding and mentorship programs to nurture the next generation of artists.
Overall, the potential future trends in art and immigration point to a greater emphasis on using art as a tool for social and political change. As artists continue to push boundaries and challenge established norms, it is crucial for society to embrace and engage with their work. By actively participating in these conversations and supporting artists, we can foster a more inclusive and empathetic society.
“Every artist dips his brush in his own soul, and paints his own nature into his pictures.” – Henry Ward Beecher
can’t help but feel a sense of nostalgia and wonder. The familiar scent of old books and the vibrant colors of handmade paintings transport me to a different time and place. It is a world where craftsmanship and creativity reign supreme, where every object tells a story and every piece of art is a window into the soul of its creator.
Walking through the Treasure House Fair, I am reminded of the rich history of human creativity. From the exquisite tapestries of the Renaissance to the avant-garde sculptures of the modern era, art has always been a mirror to society, reflecting its values, aspirations, and struggles. As I examine the intricate details of a centuries-old painting or the bold brushstrokes of a contemporary masterpiece, I can’t help but notice the echoes of our collective human experience.
But amidst the beauty and allure of the Treasure House Fair, there is a deeper question that lingers in the back of my mind. Is art merely an escape from the world’s problems, or does it have the power to ignite change and provoke thought? In times of turmoil and uncertainty, can art serve as a catalyst for social transformation?
History has shown us that art has always played a pivotal role in shaping society. The iconic paintings of the French Revolution inspired a nation to rise against oppression, while the rebellious poetry of the Beat Generation challenged the conformity of post-war America. Art has the power to provoke, to challenge norms, and to push boundaries. It can be a voice for the marginalized and a weapon against injustice.
In the contemporary world, art continues to evolve and adapt to the changing sociopolitical landscape. From street art that critiques consumerism and mass surveillance to performance pieces that question gender norms and identity, artists are using their platforms to engage with pressing issues and spark conversations that matter. In an age of digital overload and short attention spans, art’s ability to capture our imagination and make us pause is more important than ever.
As I wander through the Treasure House Fair, I am reminded of the delicate balance between art as escapism and art as a catalyst for change. It is a reminder that while art can provide solace and respite from the world’s problems, it also has the potential to inspire us to action. It is up to us, as observers and appreciators of art, to embrace its transformative power and use it as a force for positive change in our own lives and in the world at large.
So, let us immerse ourselves in the beauty and enchantment of the Treasure House Fair, but let us also remember that art has the power to move mountains, to challenge the status quo, and to make the world a better place. Let us explore the works before us with curious minds and open hearts, and let us be inspired to create a future where art and activism go hand in hand.
The Treasure House Fair is an enjoyable chance to escape the world’s problems. Or is it? Strolling round the 70 stands of art, design and curiosity, I
arXiv:2406.18593v1 Announce Type: new Abstract: We propose a material appearance modeling neural network for visualizing plausible, spatially-varying materials under diverse view and lighting conditions, utilizing only a single photograph of a material under co-located light and view as input for appearance estimation. Our neural architecture is composed of two network stages: a network that infers learned per-pixel neural parameters of a material from a single input photograph, and a network that renders the material utilizing these neural parameters, similar to a BRDF. We train our model on a set of 312,165 synthetic spatially-varying exemplars. Since our method infers learned neural parameters rather than analytical BRDF parameters, our method is capable of encoding anisotropic and global illumination (inter-pixel interaction) information into individual pixel parameters. We demonstrate our model’s performance compared to prior work and demonstrate the feasibility of the render network as a BRDF by implementing it into the Mitsuba3 rendering engine. Finally, we briefly discuss the capability of neural parameters to encode global illumination information.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Within only a few years, SHAP (Shapley additive explanations) has emerged as the number 1 way to investigate black-box models. The basic idea is to decompose model predictions into additive contributions of the features in a fair way. Studying decompositions of many predictions allows to derive global properties of the model.
What happens if we apply SHAP algorithms to additive models? Why would this ever make sense?
In the spirit of our “Lost In Translation” series, we provide both high-quality Python and R code.
The models
Let’s build the models using a dataset with three highly correlated covariates and a (deterministic) response.
import numpy as np
import lightgbm as lgb
import shap
from sklearn.preprocessing import PolynomialFeatures
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
#===================================================================
# Make small data
#===================================================================
def make_data(n=100):
x1 = np.linspace(0.01, 1, n)
x2 = np.log(x1)
x3 = x1 > 0.7
X = np.column_stack((x1, x2, x3))
y = 1 + 0.2 * x1 + 0.5 * x2 + x3 + np.sin(2 * np.pi * x1)
return X, y
X, y = make_data()
#===================================================================
# Additive linear model and additive boosted trees
#===================================================================
# Linear model with polynomial terms
poly = PolynomialFeatures(degree=3, include_bias=False)
preprocessor = ColumnTransformer(
transformers=[
("poly0", poly, [0]),
("poly1", poly, [1]),
("other", "passthrough", [2]),
]
)
model_lm = Pipeline(
steps=[
("preprocessor", preprocessor),
("lm", LinearRegression()),
]
)
_ = model_lm.fit(X, y)
# Boosted trees with single-split trees
params = dict(
learning_rate=0.05,
objective="mse",
max_depth=1,
colsample_bynode=0.7,
)
model_lgb = lgb.train(
params=params,
train_set=lgb.Dataset(X, label=y),
num_boost_round=300,
)
SHAP
For both models, we use exact permutation SHAP and exact Kernel SHAP. Furthermore, the linear model is analyzed with “additive SHAP”, and the tree-based model with TreeSHAP.
Do the algorithms provide the same?
R
Python
system.time({ # 1s
shap_lm <- list(
add = shapviz(additive_shap(fit_lm, df)),
kern = kernelshap(fit_lm, X = df[xvars], bg_X = df),
perm = permshap(fit_lm, X = df[xvars], bg_X = df)
)
shap_lgb <- list(
tree = shapviz(fit_lgb, X),
kern = kernelshap(fit_lgb, X = X, bg_X = X),
perm = permshap(fit_lgb, X = X, bg_X = X)
)
})
# Consistent SHAP values for linear regression
all.equal(shap_lm$add$S, shap_lm$perm$S)
all.equal(shap_lm$kern$S, shap_lm$perm$S)
# Consistent SHAP values for boosted trees
all.equal(shap_lgb$lgb_tree$S, shap_lgb$lgb_perm$S)
all.equal(shap_lgb$lgb_kern$S, shap_lgb$lgb_perm$S)
# Linear coefficient of x3 equals slope of SHAP values
tail(coef(fit_lm), 1) # 0.682815
diff(range(shap_lm$kern$S[, "x3"])) # 0.682815
sv_dependence(shap_lm$add, xvars)sv_dependence(shap_lm$add, xvars, color_var = NULL)
shap_lm = {
"add": shap.Explainer(model_lm.predict, masker=X, algorithm="additive")(X),
"perm": shap.Explainer(model_lm.predict, masker=X, algorithm="exact")(X),
"kern": shap.KernelExplainer(model_lm.predict, data=X).shap_values(X),
}
shap_lgb = {
"tree": shap.Explainer(model_lgb)(X),
"perm": shap.Explainer(model_lgb.predict, masker=X, algorithm="exact")(X),
"kern": shap.KernelExplainer(model_lgb.predict, data=X).shap_values(X),
}
# Consistency for additive linear regression
eps = 1e-12
assert np.abs(shap_lm["add"].values - shap_lm["perm"].values).max() < eps
assert np.abs(shap_lm["perm"].values - shap_lm["kern"]).max() < eps
# Consistency for additive boosted trees
assert np.abs(shap_lgb["tree"].values - shap_lgb["perm"].values).max() < eps
assert np.abs(shap_lgb["perm"].values - shap_lgb["kern"]).max() < eps
# Linear effect of last feature in the fitted model
model_lm.named_steps["lm"].coef_[-1] # 1.112096
# Linear effect of last feature derived from SHAP values (ignore the sign)
shap_lm["perm"][:, 2].values.ptp() # 1.112096
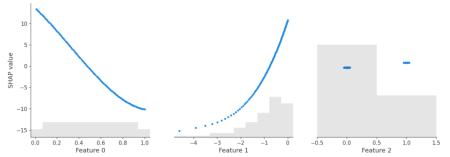
shap.plots.scatter(shap_lm["add"])
SHAP dependence plot of the additive linear model and the additive explainer (Python).
Yes – the three algorithms within model provide the same SHAP values. Furthermore, the SHAP values reconstruct the additive components of the features.
Didactically, this is very helpful when introducing SHAP as a method: Pick a white-box and a black-box model and compare their SHAP dependence plots. For the white-box model, you simply see the additive components, while the dependence plots of the black-box model show scatter due to interactions.
Remark: The exact equivalence between algorithms is lost, when
there are too many features for exact procedures (~10+ features), and/or when
the background data of Kernel/Permutation SHAP does not agree with the training data. This leads to slightly different estimates of the baseline value, which itself influences the calculation of SHAP values.
Final words
SHAP algorithms applied to additive models typically give identical results. Slight differences might occur because sampling versions of the algos are used, or a different baseline value is estimated.
The resulting SHAP values describe the additive components.
Didactically, it helps to see SHAP analyses of white-box and black-box models side by side.
Recent years have seen the rise of SHAP (Shapley Additive Explanations) as the preferred way to investigate black-box models. SHAP’s fundamental premise is to break down model predictions into additive contributions of features in a fair manner. The thorough break down of numerous predictions can uncover global properties of the model.
The application of SHAP to Additive Models
The article proceeds to consider the application of SHAP algorithms to additive models, a concept which, on the face of it, presents an interesting paradox. Analyses are carried out using both high-quality Python and R code, examining model builds using a dataset featuring three significantly correlated covariates and a deterministic response.
Models Built
The authors build additive linear models and additive boosted trees using both R and Python. For both the models, distinct SHAP algorithms have been utilized; Ensuring that the linear model is dissected with additive SHAP and the tree-based model with TreeSHAP.
Are the Results Consistent?
An intriguing question is whether these algorithms would provide similar SHAP values. The answer presented in the paper is a resounding yes. It was demonstrated that individual algorithms yielded the exact SHAP values for each model type. In addition, the SHAP values successfully replicated the additive components of the features.
However, authors noted that there might be a loss in the exact equivalence between the algorithms when there are too many features for exact procedures, or when the background data of Kernel/Permutation SHAP does not agree with the training data. These factors may result in slightly different estimates of the baseline value, which themselves influence the calculation of SHAP values.
Application of SHAP Algorithms to Additive Models: The Implications
For SHAP algorithms applied to additive models, the results are generally identical. Only slight differences might show up if sampling versions of the algorithms are used or if a different baseline value is estimated. These SHAP values describe the additive components, proving the intrinsic value of SHAP as a teaching method. Comparing SHAP analyses of white-box and black-box models side by side serves to facilitate better understanding of this concept.
Suggestions and Ideas
Further Research: Since SHAP has been identified as a potential candidate to study black-box models, it makes sense to conduct additional research in this field and explore its wider implications.
Improving the Algorithms: It is noted that exact equivalence may be lost between algorithms in certain circumstances. Research should focus on remedying these loopholes to attain more accurate results.
Educational Applications: The study proves the didactic value of SHAP for understanding white-box and black-box models. This can form a crucial part of curriculum design in data science and viably be used as a teaching method.
Model Comparison: The paper suggests a direct comparison between the SHAP values of white-box and black-box models. This could be a crucial process in future model development and analyses, leading to more robust modelling methodologies.
Conclusion
The study of SHAP values in addictive models offers compelling insights into the investigation of black-box models. As researchers continue to explore this field, we can anticipate a wealth of advanced developments and improved capacities for analyzing complex data models.
Explore the world of modern databases that are fast, secure, and cost-efficient, designed to tackle large-scale and diverse data challenges.
Exploring the Future of Modern Databases
Our digital age has witnessed the rise of modern databases that are revolutionary in their speed, security, and cost-efficiency. These databases are intelligently designed to handle large-scale and diverse data challenges. But, what does the future hold for these digital storages and how might they evolve further?
Key Points in Modern Databases
Let’s begin by considering the fundamental features that define these modern databases:
Speed: Modern databases are incredibly fast, they are able to quickly store, update, and retrieve data.
Security: These databases have robust security measures in place to protect data from breaches and other potential threats.
Cost-Efficiency: With the capabilities to handle massive amounts of data, these databases provide a cost-effective solution for enterprises across various industry sectors.
Scalability: Modern databases are built to handle large-scale and diverse data challenges, being able to accommodate growth and diversity in data.
Future Developments and Long-Term Implications
The rapid advancements in technology suggest a promising future for modern databases. Some predicted trends include:
Further improvements in speed and efficiency as result of advancements in processing power and algorithms.
Incorporation of artificial intelligence to predict potential security breaches, thus further enhancing data safety.
More cost-efficient databases due to increased competition and innovations in the realm of data storage and management.
Greater scalability as tech companies continue to design databases that can handle an ever-increasing amount of data.
However, these developments also bring about many long-term implications. Enterprises and individuals will continue to generate more data, increasing the need for reliable and efficient databases. But with this data surge, issues such as data security and privacy will also become more prominent, necessitating ongoing development in protecting data.
Actionable Advice
To be effective in this evolving data landscape, businesses need to adapt their strategies to suit the ongoing and future changes in database technology. Here’s how:
Invest in Advanced Database Solutions: Consider transferring data to modern databases that offer speed, security, and cost-efficiency. Opposed to traditional databases, they are more equipped to deal with large-scale and diverse data challenges.
Stay Updated with Latest Trends: Keep up with the latest trends in database technology to prepare for future developments. This can help in making informed decisions revolving around data storage and management.
Focus on Data Protection: Prioritize data security and privacy measures given the increasing concerns about data breaches and misuse.
Plan for Scalability: With the exponential growth in data, it’s vital to choose a database that can accommodate the influx and diversity of data in the future.
In conclusion, the future of modern databases is promising, marked by significant advances and changes in line with technological progress. By harnessing these developments, businesses can not only cope with the current data landscape, but also prepare for a future powered by data.





 arXiv:2406.18593v1 Announce Type: new Abstract: We propose a material appearance modeling neural network for visualizing plausible, spatially-varying materials under diverse view and lighting conditions, utilizing only a single photograph of a material under co-located light and view as input for appearance estimation. Our neural architecture is composed of two network stages: a network that infers learned per-pixel neural parameters of a material from a single input photograph, and a network that renders the material utilizing these neural parameters, similar to a BRDF. We train our model on a set of 312,165 synthetic spatially-varying exemplars. Since our method infers learned neural parameters rather than analytical BRDF parameters, our method is capable of encoding anisotropic and global illumination (inter-pixel interaction) information into individual pixel parameters. We demonstrate our model’s performance compared to prior work and demonstrate the feasibility of the render network as a BRDF by implementing it into the Mitsuba3 rendering engine. Finally, we briefly discuss the capability of neural parameters to encode global illumination information.
arXiv:2406.18593v1 Announce Type: new Abstract: We propose a material appearance modeling neural network for visualizing plausible, spatially-varying materials under diverse view and lighting conditions, utilizing only a single photograph of a material under co-located light and view as input for appearance estimation. Our neural architecture is composed of two network stages: a network that infers learned per-pixel neural parameters of a material from a single input photograph, and a network that renders the material utilizing these neural parameters, similar to a BRDF. We train our model on a set of 312,165 synthetic spatially-varying exemplars. Since our method infers learned neural parameters rather than analytical BRDF parameters, our method is capable of encoding anisotropic and global illumination (inter-pixel interaction) information into individual pixel parameters. We demonstrate our model’s performance compared to prior work and demonstrate the feasibility of the render network as a BRDF by implementing it into the Mitsuba3 rendering engine. Finally, we briefly discuss the capability of neural parameters to encode global illumination information.