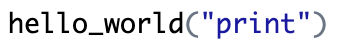[This article was first published on R – TomazTsql, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
You know the feeling after long vacation and finally sitting in front of your favourite UI and even forgot how to write simplest “hello world” or “foo bar” function? Well, we got you covered! The reverse Hello world function is for all the people returning to the office after rather long vacation.
Create the function:
# reverse Hello World
hello_world <- function(print){
if (print == "print"){
print("Hello World")
} else {
cat("rWell ...")
}
}
And be confused for a split second, when you want to use this function correctly
Welcome back!
As always, the complete code is available on GitHub in Useless_R_function repository. The sample file in this repository is here (filename: reverse_hello_world.R). Check the repository for future updates.
Happy R-coding and stay healthy!
To leave a comment for the author, please follow the link and comment on their blog: R – TomazTsql.
Getting back into Coding with Reverse Hello World Function
If you have been away from coding for a while, getting back into the nitty-gritty of programming can often seem daunting. A useful tool for those returning to the office after a long vacation is a simple script known as the “Reverse Hello World” function.
Importance of Ease-in Tools
The Reverse Hello World function exemplifies the importance of tools and functions that ease programmers back into coding. Prolonged breaks can often result in even the most seasoned coders forgetting the basics, like writing a “Hello World” or “foo bar” function. However, with easily accessible and straightforward functions like the reverse Hello World function, the process of acclimating back to complex coding environments becomes smoother.
Implications of the Reverse Hello World Function
In the long term, these script snippets might have significant implications. They are not solely convenience tools but can also be seen as educational resources. In addition to serving individual programmers, they could potentially be incorporated into learning materials for coding boot camps or online courses.
Let’s Check the Function
# reverse Hello World
hello_world <- function(print){
if (print == "print"){
print("Hello World")
} else {
cat("rWell ...")
}
}
Note how it prints “Hello World” when the given value matches “print”. As a neat little trick, it’s a simple but effective way to make you think about fundamental coding structures and logic again.
Plausible Future Developments
With the proliferation of online coding platforms and the continuous growth of remote working practices, we can expect to see more practices and functions like the Reverse Hello World. Future versions could include more complex series of commands and algorithms to help seasoned programmers get back into the swing of things after substantial breaks.
Actionable Advice
Keep Practicing: Even during periods of breaks from work, try to keep your coding skills sharp by practicing some simple functions occasionally.
Share Your Functions: If you create any easy-to-follow yet effective function like this, consider sharing it with the broader programming community. It helps not only you but also others in the same boat.
Explore Resources: Make use of coding repositories like GitHub for interesting and creative functions. Be sure to check the Useless R function repository for more such functions.
In conclusion, a mind-boggling tool to jog your memory after a vacation isn’t some high-tech app or game – something as simple as a Reverse Hello World function is enough.
Learn data science in 2024 for FREE with these online courses.
The Future of Learning Data Science – 2024 and Beyond
The digital age has brought an influx of data and, consequently, a robust demand for data science professionals. With free offerings of comprehensive online courses, learning data science is more accessible than ever. As we look towards the year 2024, this trend is bound to continue. But what are the implications, and how do we prepare for the changes and advancements to come?
Long-term Implications
As data continues to grow in prevalence and importance, understanding and interpreting this data becomes increasingly crucial. Hence, the demand for data science professionals is projected to grow. With free online resources becoming more prevalent, the barrier to entry reduces significantly. This could lead to a substantial increase in the number of skilled professionals in the field. But what could this mean?
Firstly, the job market could become more competitive. More professionals mean more competition for both entry-level and seasoned roles. However, on the bright side, companies could have a broader pool of skilled professionals from which they could hire talent. Secondly, a potential risk is that the discipline could become diluted if these courses do not maintain quality and currency with the growing demand and rapid advancement in technologies.
Possible Future Developments
Technologies such as Machine Learning, AI, and Big Data Analytics are continuously evolving. The curriculum of these courses will need to be regularly updated and improved to match these changes.
The use of interactive and immersive methods, such as gamified learning and VR/AR technologies, could become more mainstream. These methods can enhance understanding and make learning more enjoyable and engaging.
Actionable Advice
Keeping updated: With rapid advancements in technology, it is crucial to stay updated. Regularly check reliable online platforms for news about advancements in data science and related fields.
Continuous Learning: The learning process does not end once a course is completed. Engage in continuous learning by taking additional courses, attending webinars, participating in data science forums, and so on.
Practical Experience: Gaining real-world experience by working on actual data sets, participating in data science competitions, or volunteering for projects can provide invaluable experience.
“The only thing that is constant is change.” – Heraclitus, Greek philosopher
In conclusion, as the field of data science continues to grow and evolve, so too must the individuals within it. It is not merely about taking a course and obtaining a certificate. It’s about adapting to new technologies, staying curious, and continuously learning.
Explore the crucial role of technology in transforming unstructured data into actionable business insights.
The Role of Technology in Unstructured Data
For businesses, unstructured data – information that isn’t organized in a pre-defined manner or doesn’t have a pre-defined model – presents a vast ocean of opportunities and challenges alike. Thanks to the advancements in technology, this vast, unstructured bulk of data can now be transformed into actionable business insights. The role technology plays in this transformation process is beyond critical; it’s indispensable.
Long Term Implications
The ability to harness the potential of unstructured data opens up avenues for predictive analytics, more personalized customer experiences, informed decision-making, and improved problem-solving capabilities. The long-term implications of this technological capacity are profound, leading not just to improved business processes but also to entirely new business models.
For instance, businesses that successfully leverage these insights could potentially evolve existing operational procedures, predict future consumer behaviors, and respond proactively to market changes. Consequently, an enterprise’s performance is bound to improve, leading to enhanced competitiveness in the marketplace.
Possible Future Developments
Looking into the future, technology’s role in transforming unstructured data is likely to expand, evolve and become increasingly integral to business operations. Implementation of AI and machine learning algorithms in the data analysis process is anticipated, which could facilitate automation of the usually complex conversion processes and data interpretation.
Furthermore, with the continuous growth of data generated, the technology employed to utilise such data might require constant enhancement and sophistication. A significant focus should be dedicated to data security, privacy, and ethical concerns around its use as well.
Actionable Advice
To keep up with the rapid pace of technology, businesses should:
Invest in Technology: Significantly invest in technology and tools that facilitate analysis and interpretation of unstructured data. This includes AI, machine learning, and big data analytics tools.
Focus on Data Security: As data grows, so do the threats associated with it. It is crucial for organisations to ensure the implementation of strong data security protocols.
Train the Team: Ensure that your team is adequately trained. Understanding and interpreting data requires skills and knowledge in areas like data science, analytics, machine learning and AI.
Audit Regularly: Regular audit of your data practices can help in maintaining data integrity and prevent potential data breaches.
In conclusion, the transformation of unstructured data presents an opportunity for businesses to attain a competitive advantage. Adapting to this changing landscape and investing in the appropriate technology can result in valuable business insights, leading to improved decision-making, predictive capabilities, and overall improved business performance.
Domain generalization (DG) based Face Anti-Spoofing (FAS) aims to improve the model’s performance on unseen domains. Existing methods either rely on domain labels to align domain-invariant feature…
In the realm of Face Anti-Spoofing (FAS), a cutting-edge technique called Domain Generalization (DG) has emerged to enhance the performance of models when faced with unseen domains. This article explores the limitations of current methods that rely on domain labels to align domain-invariant features and presents a novel approach to address this challenge. By delving into the core themes of DG-based FAS, readers will gain a comprehensive understanding of how this technique can revolutionize the fight against face spoofing attacks.
Exploring the Boundaries of Face Anti-Spoofing with Domain Generalization
Face Anti-Spoofing (FAS) is a critical task in computer vision that aims to distinguish between genuine facial images and spoofed images created using various attack methods such as printed masks, replay attacks, or Deepfake technologies. While significant progress has been made in developing FAS models, their performance on unseen domains or real-world scenarios remains a challenge. This is where Domain Generalization (DG) techniques step in, offering innovative solutions to enhance FAS models’ performance on previously unseen domains.
The Challenge of Unseen Domains
The performance of FAS models heavily relies on the training data distribution. Traditional methods tend to overfit to specific domain characteristics during training, leading to limited generalization capability when exposed to unseen domains. This lack of robustness poses a severe threat, as attackers constantly adapt their techniques to develop new spoofing methods. The need for FAS models capable of detecting unseen attacks is crucial to ensure the security and reliability of face recognition systems.
Domain Generalization for Improved FAS
Domain Generalization techniques offer a promising approach to enhance the robustness of FAS models against unseen domains. Instead of relying solely on labeled domain data, DG techniques aim to learn domain-invariant representations from labeled source domains to be applied on unseen target domains. By explicitly disentangling the domain-specific and domain-invariant features during training, DG-based FAS models acquire the ability to generalize well to previously unseen domains.
Challenges and Existing Solutions
Existing DG-based FAS methods face several challenges in achieving robustness on unseen domains. One primary challenge is the reliance on domain labels. Traditional DG techniques require extensive domain annotations, making it impractical and time-consuming to label vast amounts of data. Moreover, domain labels might not fully represent the diverse characteristics of unseen domains.
To overcome these challenges, innovative solutions are being proposed. One approach is to use unsupervised domain adaptation to learn domain-invariant representations without relying on extensive labeled domains. By leveraging the intrinsic similarity between source and target domains, unsupervised methods aim to bridge the domain discrepancy effectively. Another solution is to introduce an adversarial network to align the domain-invariant features across different domains. This adversarial alignment helps the model generalize better to unseen domains.
Future Directions and Implications
The exploration of domain generalization techniques in the context of Face Anti-Spoofing opens up exciting possibilities for enhancing the security and reliability of face recognition systems. It not only allows FAS models to detect novel and emerging spoofing attacks but also promotes the development of more robust and adaptable models. Additionally, the adoption of unsupervised domain adaptation methods and adversarial training can significantly reduce the reliance on extensive domain labels, making the training process more flexible and scalable.
As the field progresses, future research should focus on developing more comprehensive benchmark datasets that encompass a wider range of unseen domains and attack scenarios to evaluate the effectiveness of DG-based FAS models. Furthermore, exploring the combination of DG techniques with other state-of-the-art computer vision approaches, such as deep neural networks and attention mechanisms, can unlock new avenues for improving FAS models’ performance.
Conclusion: Domain Generalization offers a promising pathway to address the limitations of existing FAS models in handling unseen domains. By leveraging domain-invariant features and disentangling domain-specific characteristics, DG-based FAS models acquire the ability to generalize well to previously unseen domains. Innovative solutions such as unsupervised domain adaptation and adversarial training pave the way for more robust and adaptable FAS models. Future research should explore more comprehensive datasets and combine DG techniques with other state-of-the-art approaches to further enhance FAS models’ performance.
representations or exploit adversarial training to minimize the domain discrepancy. However, these approaches have their limitations and may not fully address the challenges of domain generalization in face anti-spoofing.
One potential limitation of relying on domain labels is the requirement for labeled data from multiple domains, which can be time-consuming and expensive to obtain. Moreover, obtaining a representative and diverse set of domain labels can be challenging, as it may not always be feasible to cover all possible unseen domains. This limitation restricts the scalability and practicality of domain generalization methods that rely on domain labels.
On the other hand, adversarial training has shown promise in minimizing domain discrepancy by training a domain classifier to distinguish between real and spoofed faces. The idea is to force the model to learn domain-invariant features that cannot be easily distinguished by the classifier. While this approach can be effective, it is not foolproof and may not fully capture the underlying variations in unseen domains. Adversarial training can also be sensitive to hyperparameters and prone to convergence issues, making it less stable and reliable in practice.
To overcome these limitations, future research in domain generalization for face anti-spoofing could explore alternative approaches. One potential direction is to leverage unsupervised learning techniques, such as self-supervised learning or contrastive learning, to learn robust representations that are less dependent on domain labels. These techniques can exploit the inherent structure and patterns in the data to learn meaningful representations without the need for explicit domain alignment.
Another avenue for improvement is to investigate meta-learning or few-shot learning approaches in the context of domain generalization. These techniques aim to learn from limited labeled data by leveraging prior knowledge or experience gained from similar tasks or domains. By incorporating meta-learning into domain generalization for face anti-spoofing, models could potentially adapt and generalize better to unseen domains by effectively leveraging the knowledge gained from previously encountered domains.
Furthermore, incorporating domain adaptation techniques, such as domain adversarial neural networks or domain-invariant feature learning, could also enhance the performance of domain generalization methods. These techniques explicitly aim to reduce the domain shift by aligning the distributions of different domains, thus improving the model’s ability to generalize to unseen domains.
In conclusion, while domain generalization-based face anti-spoofing methods have shown promising results, there are still challenges to overcome. By exploring alternative approaches like unsupervised learning, meta-learning, and domain adaptation, researchers can push the boundaries of domain generalization and improve the robustness and effectiveness of face anti-spoofing models in real-world scenarios. Read the original article