by jsendak | Mar 11, 2024 | DS Articles
[This article was first published on
R-posts.com, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Shiny, without server
In previous article, I introduced method to share shiny application in static web page (github page)
At the core of this method is a technology called WASM, which is a way to load and utilize R and Shiny-related libraries and files that have been converted for use in a web browser. The main problem with wasm is that it is difficult to configure, even for R developers.
Of course, there was a way called shinylive, but unfortunately it was only available in python at the time.
Fortunately, after a few months, there is an R package that solves this configuration problem, and I will introduce how to use it to add a shiny application to a static page.
shinylive
shinylive is R package to utilize wasm above shiny. and now it has both Python and R version, and in this article will be based on the R version.
shinylive is responsible for generating HTML, Javascript, CSS, and other elements needed to create web pages, as well as wasm-related files for using shiny.
You can see examples created with shinylive at this link.

Install shinylive
While shinylive is available on CRAN, it is recommended to use the latest version from github as it may be updated from time to time, with the most recent release being 0.1.1. Additionally, pak is the recently recommended R package for installing R packages in posit, and can replace existing functions like install.packages() and remotes::install_github().
# install.packages("pak")
pak::pak("posit-dev/r-shinylive")
You can think of shinylive as adding a wasm to an existing shiny application, which means you need to create a shiny application first.
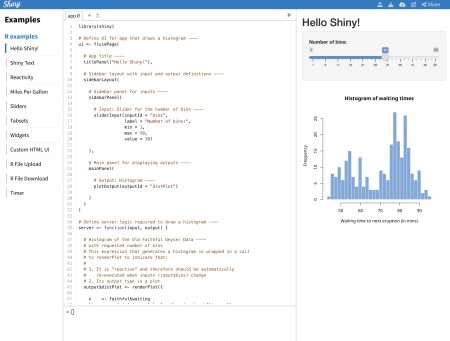
For the example, we’ll use the code provided by shiny package (which you can also see by typing shiny::runExample("01_hello") in the Rstudio console).
library(shiny)
ui <- fluidPage(
titlePanel("Hello Shiny!"),
sidebarLayout(
sidebarPanel(
sliderInput(
inputId = "bins",
label = "Number of bins:",
min = 1,
max = 50,
value = 30
)
),
mainPanel(
plotOutput(outputId = "distPlot")
)
)
)
server <- function(input, output) {
output$distPlot <- renderPlot({
x <- faithful$waiting
bins <- seq(min(x), max(x), length.out = input$bins + 1)
hist(x,
breaks = bins, col = "#75AADB", border = "white",
xlab = "Waiting time to next eruption (in mins)",
main = "Histogram of waiting times"
)
})
}
shinyApp(ui = ui, server = server)
This code creates a simple shiny application that creates a number of histograms in response to the user’s input, as shown below.
There are two ways to create a static page with this code using shinylive, one is to create it as a separate webpage (like previous article) and the other is to embed it as internal content on a quarto blog page .
First, here’s how to create a separate webpage.
shinylive via web page
To serve shiny on a separate static webpage, you’ll need to convert your app.R to a webpage using the shinylive package you installed earlier.
Based on creating a folder named shinylive in my Documents(~/Documents) and saving `app.R` inside it, here’s an example of how the export function would look like
shinylive::export('~/Documents/shinylive', '~/Documents/shinylive_out')
When you run this code, it will create a new folder called shinylive_out in the same location as shinylive, (i.e. in My Documents), and inside it, it will generate the converted wasm version of shiny code using the shinylive package.
If you check the contents of this shinylive_out folder, you can see that it contains the webr, service worker, etc. mentioned in the previous post.
More specifically, the export function is responsible for adding the files from the local PC’s shinylive package assets, i.e. the library files related to shiny, to the out directory on the local PC currently running R studio.
Now, if you create a github page or something based on the contents of this folder, you can serve a static webpage that provides shiny, and you can preview the result with the command below.
httpuv::runStaticServer("~/Documents/shinylive_out")
shinylive in quarto blog
To add a shiny application to a quarto blog, you need to use a separate extension. The quarto extension is a separate package that extends the functionality of quarto, similar to using R packages to add functionality to basic R.
First, we need to add the quarto extension by running the following code in the terminal (not a console) of Rstudio.
quarto add quarto-ext/shinylive
You don’t need to create a separate file to plant shiny in your quarto blog, you can use a code block called {shinylive-r}. Additionally, you need to set shinylive in the yaml of your index.qmd.
filters:
- shinylive
Then, in the {shinylive-r} block, write the contents of the app.R we created earlier.
#| standalone: true
#| viewerHeight: 800
library(shiny)
ui <- fluidPage(
titlePanel("Hello Shiny!"),
sidebarLayout(
sidebarPanel(
sliderInput(
inputId = "bins",
label = "Number of bins:",
min = 1,
max = 50,
value = 30
)
),
mainPanel(
plotOutput(outputId = "distPlot")
)
)
)
server <- function(input, output) {
output$distPlot <- renderPlot({
x <- faithful$waiting
bins <- seq(min(x), max(x), length.out = input$bins + 1)
hist(x,
breaks = bins, col = "#75AADB", border = "white",
xlab = "Waiting time to next eruption (in mins)",
main = "Histogram of waiting times"
)
})
}
shinyApp(ui = ui, server = server)
after add this in quarto blog, you may see working shiny application.
You can see working example in this link
Summary
shinylive is a feature that utilizes wasm to run shiny on static pages, such as GitHub pages or quarto blogs, and is available as an R package and quarto extension, respectively.
Of course, since it is less than a year old, not all features are available, and since it uses static pages, there are disadvantages compared to utilizing a separate shiny server.
However, it is very popular for introducing shiny usage and simple statistical analysis, and you can practice it right on the website without installing R, and more features are expected to be added in the future.
The code used in blog (previous example link) can be found at the link.
Author: jhk0530
Add shiny in quarto blog with shinylive was first posted on March 10, 2024 at 5:25 pm.
Continue reading: Add shiny in quarto blog with shinylive
Implications and future developments of Shinylive
The implementation of Shiny applications without a server using WebAssembly (WASM) and Shinylive offers a significant development for R developers who want to share their work in static pages, such as beta-testing of applications or blogging. This article aims to discuss the long-term implications of this development, theorize possible future developments, and provide actionable advice for developers and data scientists interested in this technique.
I. Long-term implications
1. Greater convenience and flexibility: With Shinylive and WASM, static webpage hosting becomes more feasible for R developers, allowing them to share Shiny applications easily without the need for a server. This adds flexibility and makes the distribution of applications more efficient.
2. Enhance Shiny applications: The use of Shinylive not only enhances the capabilities of Shiny applications but also simplifies the process of embedding these applications on a static webpage or a quarto blog page, expanding their potential uses and applications.
3. Increasing adoption: This accessibility to a broader range of outlets for their work may encourage increased adoption of R and Shiny among the scientific and data analysis communities.
II. Possible future developments
1. Extended features and new packages: The Shinylive package is still young, and therefore it can be expected that more features will be added in the future. Developers may build more sophisticated packages similar to Shinylive to make the most out of static pages.
2. Increasing use of WASM: WASM’s potential proves to be high in this context, suggesting it may see broader adoption and improvements that could increase efficiency for developers.
III. Actionable advice
1. Stay updated: R developers who use Shiny apps should monitor the development of Shinylive and similar packages. It is recommended to use the latest version of the package as updates are released regularly.
2. Experiment with WASM: If you are a developer, do not shy away from WASM, despite its configuration challenges. Gaining this capability could open new possibilities for your applications and bring increased convenience when sharing work.
3. Consider static page hosting: Consider the benefits of static webpage hosting for sharing applications, as well as the potential broadening of the audience for your work. This mechanism can be highly appealing due to its simplicity and cost-effectiveness compared to setting up a dedicated server.
Conclusion
WASM and Shinylive together form an innovative solution for R developers looking to share Shiny applications in a flexible, server-less environment, thus broadening their application’s reach. As technology continues to progress, one can expect further enhancements and improved efficiency in this area. R developers should look forward to these developments and be prepared to integrate them into their work processes to reap their full benefits.
Read the original article
by jsendak | Mar 11, 2024 | DS Articles
From learning to earning: 4 essential DataCamp certifications to land your dream job.
Long-Term Implications and Future Developments of DataCamp Certifications
The increasing importance of data in contemporary business and societal decision-making underscores the growing demand for professionals skilled in data management and analysis. The recently published article “From learning to earning: 4 essential DataCamp certifications to land your dream job” emphasizes the benefit of such qualifications in strengthening career prospects. In this follow-up, we consider the long-term implications and possible future developments of these qualifications.
Long-Term Implications
In the ever-changing digital landscape, a gap between industry requirements and the skillset of the existing workforce often emerges. Having data-specific qualifications like the ones offered in DataCamp can close this gap and offer job-seekers an edge over their counterparts. The increased demand for data literate professionals suggests that these certifications will remain highly valuable.
“The world is growing more data-focused every day, and those with the ability to understand and harness this data will be leading the way.”
The ability to analyze and manage data is indispensable in sectors such as business, healthcare, policy-making and beyond. This high demand across various sectors promises exciting and varied career opportunities for data professionals.
Future Developments
Data professions are continually evolving, and so too will the qualifications required for these roles. Artificial Intelligence and advanced analytics are predicted to reshape the data landscape, and future training programs and certifications will likely need to reflect these changes.
Increased Emphasis on Machine Learning and AI
We foresee a more prominent emphasis on concepts related to Artificial Intelligence (AI) and Machine Learning (ML) in future DataCamp certifications. These fields are projected to take a center stage in the upcoming years, heavily impacting data roles. Professionals equipped with such knowledge will have a competitive advantage.
Development of Ethics and Data Privacy Certifications
We also anticipate a rise in demand for certifications related to ethics and data privacy. With increased public scrutiny towards data management and usage, the need for data professionals with a strong understanding of ethical implications and privacy principles will undoubtedly grow.
Actionable Advice
If you’re planning to fortify your career prospects with data-centric skills, it’s advisable to consider obtaining data certifications, keeping the following pointers in mind:
- Stay updated with industry trends: It’s important to remain informed about emerging trends in the data field, ensuring your qualification remains relevant and up-to-date.
- Brush up on AI and ML: Given the expected rise of AI and ML in data analysis, getting ahead by familiarizing with these concepts can’t hurt.
- Ethics are essential: Be ready to demonstrate your commitment to ethical data use by seeking certificates related to data ethics and privacy.
Taking these steps will ensure that you stay competitive, informed and indispensable in the evolving field of data management.
Read the original article
by jsendak | Mar 11, 2024 | DS Articles
During a recent discussion with high school juniors and seniors, my goal was to enhance their awareness and understanding of Big (intrusive) Data and AI by focusing on two main areas. The bottom line is that I wanted to turn them into citizens of data science. And to accomplish that, I created a simple exercise… Read More »Creating an AI Utility Function: A Classroom Exercise
Introduction
The intersection between educational structures and emergent technologies, such as Big Data and Artificial Intelligence (AI), has created new approaches towards teaching and learning. A case in focus is the recent initiative to educate high school students on the implications of Big Data and AI, effectively turning them into ‘citizens of data science’. This endeavor includes an AI utility function exercise, designed to foster a deeper understanding of these complex technologies.
Long-term Implications of AI and Big Data in Education
The introduction of AI and Big Data into high school curriculum has significant long-term implications. Enhancing pupils’ awareness and understanding of these concepts is a crucial step towards their inevitable future in a data-driven world. This trend is expected to create global citizens who are not only competent users of data and AI but also understand their potential implications and ethical issues.
Early Exposure to Data Science and AI
One substantial long-term effect of this initiative is that students receive early exposure to data science and AI. This early exposure will likely proliferate the development of technological literacy, enabling the students to navigate and understand a world increasingly shaped by these technologies. It also opens avenues for students who wish to delve deeper into these areas in their future careers.
Solving Real-World Problems
The AI utility function exercise is designed to help students understand how AI works. This will equip them with the potential to apply AI in solving real-world problems in the future.
Possible Future Developments
While the present initiative is a positive step, the potential for its future enhancements and developments is vast.
Progression to More Advanced Topics
As students gain a solid foundation in understanding AI and Big Data, educators may introduce more advanced topics. These can include machine learning, neural networks, and comprehensive data analysis.
Collaboration with Tech Companies
Schools could partner with tech companies for guest lectures, internships, and practical workshops. These companies can offer realistic insights into the AI industry and provide hands-on experience to students.
Actionable Advice
- Education policymakers should consider introducing AI and Data Science as standalone subjects, promoting tech literacy from a young age.
- Teachers should continually upgrade their knowledge to effectively introduce students to these complex subjects.
- Students should actively engage in these learning opportunities to prepare for the technological future.
- Tech companies should see this as an opportunity to nurture the next generation of tech talent by partnering with schools and offering hands-on learning experiences.
Creating an AI Utility Function: A Classroom Exercise demonstrates the potential advantage of introducing complex technologies such as AI and Big Data in high school. It underlines the importance of understanding these concepts for the younger generation preparing for a data-driven future.
Read the original article
by jsendak | Mar 10, 2024 | DS Articles
[This article was first published on
Rstats – quantixed, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Answering the question of what fraction of a journal’s papers were previously available as a preprint is quite difficult to do. The tricky part is matching preprints (from a number of different servers) with the published output from a journal. The easy matches are those that are directly linked together, the remainder though can be hard to identify since the manuscript may change (authors, title, abstract) between the preprint and the published version.
A strategy by Crossref called Marple, that aims match preprints to published outputs seems like the best effort so far. Their code and data up to Aug 2023 is available. Let’s use this to answer the question!
My code is below, let’s look at the results first.

The papers that have a preprint version are red, and those without are in grey. The bars are stacked in these plots and the scale is free so that the journals with different volumes of papers can be compared. The plots show only research papers. Reviews and all other outputs have been excluded as far as possible.
We can replot this to show the fraction of papers that have an associated preprint:
We can see that Elife is on a march to become 100% of papers with preprint version. This is due to a policy decision taken a few years ago.
Then there is a tranche of journals who seem to be stabilising at between 25-50% of outputs having a preprinted version. These journals include: Cell Rep, Dev Cell, Development, EMBO J, J Cell Biol, J Cell Sci, MBoC, Nat Cell Biol, Nat Commun, and Plos Biol.
Finally, journals with a very small fraction of preprinted papers include Cells, FASEB J, Front Cell Dev Biol, JBC.
My focus here was on journals in the cell and developmental biology area. I suspect that the differences in rates between journals reflects the content they carry. Cell and developmental biology, like genetics and biophysics, have an established pattern of preprinting. A journal like JCB, carrying 100% cell biology papers tops out at 50% in 2022. Whereas EMBO J, which has a lower fraction of cell biology papers plateaus at ~30%. However, the discipline doesn’t really explain why Cells and Front Cell Dev Biol have such low preprint rates. I know that there are geographical differences in preprinting and so differences in the regional base of authors at a journal may impact their preprint rate overall. There are likely other contributing factors.
Caveats and things to note:
- the data only goes up to Aug 2023, so the final bar is unreliable.
- the assignment is not perfect – there will be some papers here that have a preprint version but are not linked up and some erroneous linkages. I had a sense check of the data for one journal and could see a couple of duplicates in the Crossref data out of ~600 for that journal. So the error rate seems very low.
- the PubMed data is good but again, it is hard to exclude some outputs that are not research papers if they are not tagged appropriately.
The code
devtools::install_github("ropensci/rentrez")
library(rentrez)
library(XML)
# pre-existing script that parses PubMed XML files
source("Script/pubmedXML.R")
# Fetch papers ----
# search term below exceed 9999 results, so need to use history
srchTrm <- paste('("j cell sci"[ta] OR',
'"mol biol cell"[ta] OR',
'"j cell biol"[ta] OR',
'"nat cell biol"[ta] OR',
'"embo j"[ta] OR',
'"biochem j"[ta] OR',
'"dev cell"[ta] OR',
'"faseb j"[ta] OR',
'"j biol chem"[ta] OR',
'"cells"[ta] OR',
'"front cell dev biol"[ta] OR',
'"nature communications"[ta] OR',
'"cell reports"[ta]) AND',
'"development"[ta]) AND',
'"elife"[ta]) AND',
'"plos biol"[ta]) AND',
'(2016 : 2023[pdat]) AND',
'(journal article[pt] NOT review[pt])')
# so we will use this
journalSrchTrms <- c('"j cell sci"[ta]','"mol biol cell"[ta]','"j cell biol"[ta]','"nat cell biol"[ta]','"embo j"[ta]',
'"biochem j"[ta]','"dev cell"[ta]','"faseb j"[ta]','"j biol chem"[ta]','"cells"[ta]',
'"front cell dev biol"[ta]','"nature communications"[ta]','"cell reports"[ta]',
'"development"[ta]','"elife"[ta]','"plos biol"[ta]')
# loop through journals and loop through the years
# 2016:2023
pprs <- data.frame()
for (i in 2016:2023) {
for(j in journalSrchTrms) {
srchTrm <- paste(j, ' AND ', i, '[pdat]', sep = "")
pp <- entrez_search(db = "pubmed",
term = srchTrm, use_history = TRUE)
if(pp$count == 0) {
next
}
pp_rec <- entrez_fetch(db = "pubmed", web_history = pp$web_history, rettype = "xml", parsed = TRUE)
xml_name <- paste("Data/all_", i,"_",extract_jname(j), ".xml", sep = "")
saveXML(pp_rec, file = xml_name)
tempdf <- extract_xml_brief(xml_name)
if(!is.null(tempdf)) {
pprs <- rbind(pprs, tempdf)
}
}
}
Now let’s load in the Crossref data and match it up
library(dplyr)
library(ggplot2)
df_all <- read.csv("Data/crossref-preprint-article-relationships-Aug-2023.csv")
# remove duplicates from pubmed data
pprs <- pprs[!duplicated(pprs$pmid), ]
# remove unwanted publication types by using a vector of strings
unwanted <- c("Review", "Comment", "Retracted Publication", "Retraction of Publication", "Editorial", "Autobiography", "Biography", "Historical", "Published Erratum", "Expression of Concern", "Editorial")
# subset pprs to remove unwanted publication types using grepl
pure <- pprs[!grepl(paste(unwanted, collapse = "|"), pprs$ptype), ]
# ensure that ptype contains "Journal Article"
pure <- pure[grepl("Journal Article", pure$ptype), ]
# remove papers with "NA NA" as the sole author
pure <- pure[!grepl("NA NA", pure$authors), ]
# add factor column to pure that indicates if a row in pprs has a doi that is also found in article_doi
pure$in_crossref <- ifelse(tolower(pure$doi) %in% tolower(df_all$article_doi), "yes", "no")
# find the number of rows in pprs that have a doi that is also found in pure
nrow(pure[pure$in_crossref == "yes",])
# summarize by year the number of papers in pure and how many are in the yes and no category of in_crossref
summary_df <- pure %>%
# convert from chr to numeric
mutate(year = as.numeric(year)) %>%
group_by(year, journal, in_crossref) %>%
summarise(n = n())
# make a plot to show stacked bars of yes and no for each year
ggplot(summary_df, aes(x = year, y = n, fill = in_crossref)) +
geom_bar(stat = "identity") +
theme_minimal() +
scale_fill_manual(values = c("yes" = "#ae363b", "no" = "#d3d3d3")) +
lims(x = c(2015.5, 2023.5)) +
labs(x = "Year", y = "Papers") +
facet_wrap(~journal, scales = "free_y") +
theme(legend.position = "none")
ggsave("Output/Plots/preprints_all.png", width = 2400, height = 1800, dpi = 300, units = "px", bg = "white")
# now do plot where the bars stack to 100%
ggplot(summary_df, aes(x = year, y = n, fill = in_crossref)) +
geom_bar(stat = "identity", position = "fill") +
theme_minimal() +
scale_fill_manual(values = c("yes" = "#ae363b", "no" = "#d3d3d3")) +
lims(x = c(2015.5, 2023.5)) +
labs(x = "Year", y = "Proportion of papers") +
facet_wrap(~journal) +
theme(legend.position = "none")
ggsave("Output/Plots/preprints_scaled.png", width = 2400, height = 1800, dpi = 300, units = "px", bg = "white")
Edit: minor update to first plot and code.
—
The post title comes from “Pre Self” by Godflesh from the “Post Self” album.
Continue reading: Pre Self: what fraction of a journal’s papers are preprinted?
Understanding the Growth and Prevalence of Preprinting in Academic Publishing
Preprinting – the sharing of academic papers before peer review – is steadily becoming common practice in many fields. Yet, measuring how many of a journal’s papers are available as preprints can be tricky, due to discrepancies in details like author names, titles, and abstracts that may occur during the transition from preprint to published version. Nonetheless, this task is essential as it allows us to observe the state and trend of preprinting practices, which will significantly influence the future of academia and publishing.
Findings and Analysis
The code discussed in the article attempts to correlate self-archived preprint papers with their corresponding published outputs, using strategies such as Crossref’s Marple. Through analysis, we observe that some journals, like Elife, are almost entirely composed of papers with preprint versions due to policy shifts favoring preprinting within the past few years. A second group of publications, including widely recognized journals such as Cell Reports, Development, and Nat Commun, have around 25-50% of their content originating from preprints. However, several journals, like Cells and FASEB J, show very low preprint rates.
The rate differences between journals could be influenced by the specificity of their subjects. Fields like cell and developmental biology – which are quite established in their preprinting practices – tend to feature higher rates of preprint originality. For instance, the Journal of Cell Biology’s (JCB) preprint rates reached 50% in 2022, while EMBO Journal – a journal with lesser focus on cell biology – only reaches around 30%. Geographic differences among the author base, alongside other undefined factors, could also affect preprint rates.
Long-term Implications and Future Developments
The rise of preprinting… practices presents several potential implications for the academic and publishing communities. If current trends persist or accelerate, we could see a more open and transparent academic landscape where the sharing of pioneering research does not have to wait for the lengthy publishing process. However, it also raises issues, such as the credibility of non-peer-reviewed papers and potential ‘scooping’ of research ideas.
At this rate, the publishing world may need to revise its policies and practices to accommodate and properly manage these changes. Incorporating more robust measures for preprint and published article matching could help improve data analytics and reporting in academic publishing. Furthermore, efforts to standardize preprinting practices may help alleviate some concerns or issues born out of its rapid adoption.
Actionable Advice
Scholars and researchers are advised to stay updated on preprinting practices in their respective fields. Preprinting can provide more immediate visibility to your research, but careful consideration should be given to the potential drawbacks. Further, journals and publishers should reassess their approaches to preprints, taking steps to more accurately account for the shift to this new publishing model.
Lastly, developers, data analysts, and librarians could cross-reference this code with their data to extract meaningful insights about preprint practices in their respective fields or institutions. This data will help keep these stakeholders informed and facilitate more strategic decision-making processes in line with the changing nature of academic publishing.
Read the original article
by jsendak | Mar 10, 2024 | DS Articles
This article explains the concept of regularization and its significance in machine learning and deep learning. We have discussed how regularization can be used to enhance the performance of linear models, as well as how it can be applied to improve the performance of deep learning models.
Understanding the Impact of Regularization on Machine Learning and Deep Learning
Our exploration into the world of machine learning and deep learning brings up one significant aspect – regularization. This process plays a key role in improving the performance of both linear models and deep learning models. Through this article, we will delve deeper into the future implications of regularization and how it may evolve as these technologies continue to expand.
Long-Term Implications of Regularization
Given the current trends and advances in machine learning and deep learning algorithms, regularization is poised to have lasting implications. One major aspect is in the prevention of overfitting, where models are too closely fit to the training data, hence underperforming on unseen data. As machine learning and deep learning become more sophisticated, regularization will become increasingly vital in mitigating this issue.
Furthermore, with the exponential growth of data, models are becoming increasingly complex, fuelling overfitting and increasing computational costs. Through regularization, we can better manage this complexity, keeping computational requirements in check and enhancing the overall performance of the models.
Possible Future Developments
As technology and data science evolve, so too does our need for improved regularization techniques. We may soon witness the development of new regularization algorithms that are more effective in preventing overfitting and reducing computational costs.
Notably, there may be advancements in adaptive regularization techniques that adjust the regularization strength based on the complexity of the model. This would lead to smarter and more efficient machine learning and deep learning models.
Actionable Advice
- Stay Informed: As regularization becomes increasingly important, it’s crucial to stay updated on the latest research and methodologies. New techniques could bring significant benefits to your machine learning and deep learning models.
- Invest in Training: Regularization is a nuanced aspect of machine learning and deep learning. It’s vital to understand it fully to leverage its benefits. Continuous training and learning opportunities for your team will ensure you’re well-equipped.
- Adopt Best Practices: Implement regularization in your workflows to enhance model performance. It’s a preventive measure against overfitting and a method for improving prediction accuracy on unseen data.
- Future-proof Your Machine Learning Models: Invest in developing or adopting adaptive regularization techniques that can adjust to the complexity of the model. This will make your models both effective and efficient.
Read the original article
by jsendak | Mar 10, 2024 | DS Articles
As we approach 2024, no brand or customer remains unaffected by AI. Our interactions in the marketplace have altered as a result.
Understanding the Impact of AI by 2024
Whether directly or indirectly, it is undeniable that artificial intelligence has touched virtually every aspect of our lives, including the business sector. As we approach 2024, no brand or customer is unaffected by AI. This is leading to a significant transformation in the marketplace dynamics, altering our interactions with businesses and other consumers.
Long-Term Implications of AI in Businesses
The Dawn of Personalized Shopping
AI-backed personalization is poised to change the shopping experience as we know it. With the capacity to process and analyze vast customer data, AI can accurately predict buying behavior and preferences, creating a more personalized shopping experience. This essentially means businesses will win customers over based not just on product quality, but also on the ability to provide an enriched, tailored experience.
Improved Customer Service
Artificial intelligence is shaping the future of customer service. Chatbots integrated with AI capabilities can effectively respond to customer queries 24/7, which not only improves customer satisfaction, but also brings significant cost savings for businesses. This consistent AI-efficiency promises to refine the future of the customer service industry.
Augmenting Decision Making
AI technology is increasingly intersecting with decision-making processes in businesses. By providing predictive analysis and valuable insights, AI can guide businesses to make informed decisions, reducing risks and maximizing profitability.
Possible Future Developments
Even though the impact of AI on business is already profound, it is bound to become more prominent in the future. We may foresee advancements in AI technology such as self-improving algorithms, an increase in the adoption of AI in small and medium enterprises (SMEs), and a perpetual evolution in customer service practices.
Actionable Advice
Given this trend, there are several strategies that businesses can adopt to remain competitive:
- Invest in AI Technology: Businesses need to understand that AI is not just a fad, but an investment with substantial return potential. Enterprises should consider integrating AI within their business strategy and improve their operational efficiency.
- Data Management: Handling and processing data is a key part of AI integrations. To implement AI solutions effectively, businesses need to have robust data management systems in place. This would allow them to fully leverage AI’s power for predictive analysis and decision making.
- Focus on Personalization: With AI’s ability to create tailored experiences, businesses should make personalization a core aspect of their strategy. This not only enhances customer satisfaction but also boosts brand loyalty.
- Continual Learning: The field of AI is constantly evolving. Businesses need to stay abreast with the latest developments and trends in AI technology to maintain a competitive edge.
As we embark upon the future, we must acknowledge and respect the role of artificial intelligence in reshaping our world. For businesses, the task at hand is clear: to adapt, evolve, and thrive in this new AI-dominated landscape.
Read the original article