Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Introduction
In data analysis with R, subsetting data frames based on multiple conditions is a common task. It allows us to extract specific subsets of data that meet certain criteria. In this blog post, we will explore how to subset a data frame using three different methods: base R’s subset() function, dplyr’s filter() function, and the data.table package.
Examples
Using Base R’s subset() Function
Base R provides a handy function called subset() that allows us to subset data frames based on one or more conditions.
# Load the mtcars dataset
data(mtcars)
# Subset data frame using subset() function
subset_mtcars <- subset(mtcars, mpg > 20 & cyl == 4)
# View the resulting subset
print(subset_mtcars)
In the above code, we first load the mtcars dataset. Then, we use the subset() function to create a subset of the data frame where the miles per gallon (mpg) is greater than 20 and the number of cylinders (cyl) is equal to 4. Finally, we print the resulting subset.
Using dplyr’s filter() Function
dplyr is a powerful package for data manipulation, and it provides the filter() function for subsetting data frames based on conditions.
# Load the dplyr package
library(dplyr)
# Subset data frame using filter() function
filter_mtcars <- mtcars %>%
filter(mpg > 20, cyl == 4)
# View the resulting subset
print(filter_mtcars)
In this code snippet, we load the dplyr package and use the %>% operator, also known as the pipe operator, to pipe the mtcars dataset into the filter() function. We specify the conditions within the filter() function to create the subset, and then print the resulting subset.
Using data.table Package
The data.table package is known for its speed and efficiency in handling large datasets. We can use data.table’s syntax to subset data frames as well.
# Load the data.table package
library(data.table)
# Convert mtcars to data.table
dt_mtcars <- as.data.table(mtcars)
# Subset data frame using data.table syntax
dt_subset_mtcars <- dt_mtcars[mpg > 20 & cyl == 4]
# Convert back to data frame (optional)
subset_mtcars_dt <- as.data.frame(dt_subset_mtcars)
# View the resulting subset
print(subset_mtcars_dt)
In this code block, we first load the data.table package and convert the mtcars data frame into a data.table using the as.data.table() function. Then, we subset the data using data.table’s syntax, specifying the conditions within square brackets. Optionally, we can convert the resulting subset back to a data frame using as.data.frame() function before printing it.
Conclusion
In this blog post, we learned three different methods for subsetting data frames in R by multiple conditions. Whether you prefer base R’s subset() function, dplyr’s filter() function, or data.table’s syntax, there are multiple ways to achieve the same result. I encourage you to try out these methods on your own datasets and explore the flexibility and efficiency they offer in data manipulation tasks. Happy coding!
Comprehensive Analysis of Subsetting Data Frames in R
In the realm of data analysis with R, extracting specific subsets of data based on various conditions is a crucial and frequent task. Three different methods highlighted for this purpose are: the use of base R’s subset() function, dplyr’s filter() function, and the data.table package. Familiarity with these methods is fundamental in handling data manipulation tasks with fluency and efficiency.
Key Points from the Original Article
Utilizing Base R’s subset() Function
Base R’s subset() function has been presented as a handy tool for data subsetting depending on one or more conditions. The ‘mtcars’ dataset was used as an example to create a subset where the miles per gallon (mpg) is greater than 20 and the number of cylinders (cyl) equals 4.
Dplyr’s filter() Function
The dplyr’s filter() function can also be used to subset data frames based on specific conditions. By using the pipe operator (%>%), the ‘mtcars’ dataset was piped into the filter() function, and appropriate conditions were specified to complete the subsetting process.
Data Manipulation using the data.table Package
The data.table’s syntax, known for its robustness and efficiency when dealing with large datasets, was also demonstrated for subsetting data frames. After loading the data.table package, the ‘mtcars’ data frame was converted into a data.table to use the specific syntax for subsetting.
Long-term Implications and Future Developments
As data continues to increase in volume and complexity, the need to handle this data efficiently is more than ever. Whether one choose to use Base R’s subset(), dplyr’s filter(), or data.table, users would have an advantage with efficient and powerful tools at their disposal to handle large and complex datasets.
Moving forward, the R community might continue to develop optimized packages and functions that allow analysts and data scientists to cleanly and quickly streamline data. As the field of data science continues to evolve, new packages and improved functions could be released, further aiding in efficient data manipulation.
Actionable Advice
It is recommended that data analysts and data scientists familiarize themselves with multiple ways of subsetting data in R. Proficiency in these techniques allows them to choose the most efficient and suitable method according to the complexity and size of the dataset at hand.
For beginners, starting with the base R’s subset() function might be a good starting point as it is straightforward and easy to grasp. Once familiar with the base R syntax, methods using advanced packages like dplyr and data.table could be explored.
Finally, practicing these methods on various datasets will help one get a commanding understanding of how, when, and where to apply these techniques most effectively.
Learn how to enhance the quality of your machine learning code using Scikit-learn Pipeline and ColumnTransformer.
Exploring the Future of Machine Learning with Scikit-learn Pipeline and ColumnTransformer
Machine learning and artificial intelligence are dynamic sectors constantly under the influence of technological upgrades and enhancements. Scikit-learn Pipeline and ColumnTransformer are tools designed to optimize the quality of your machine learning code, and they play a significant role in the ongoing evolution of these sectors.
The Role of Scikit-learn Pipeline and ColumnTransformer in Machine Learning
Significantly, the Scikit-learn Pipeline offers a way to streamline a lot of the common and repeatable processes involved in machine learning. On the other hand, ColumnTransformer is principally aimed at transforming features or datasets to optimize their utility within various machine learning frameworks.
Long-term implications and Future Developments
The advancements in machine learning, facilitated by Scikit-learn Pipeline and ColumnTransformer, have far-reaching implications. As machine learning efforts develop and grow more complex, tools like these are vital for maintaining efficiency and quality in coding processes. In the future, we can expect to see a continued expansion and fine-tuning of tools similar to these in order to meet the growing needs of machine learning projects.
Actionable Advice for Effective Use Of Scikit-learn Tools
Stay updated with the new advancements and updates: Like all digital tools, Scikit-learn Pipeline and ColumnTransformer are regularly updated. Keeping up with these updates will allow you to take full advantage of these tools and improve your machine learning efforts.
Improve your understanding of these tools: To fully utilize Scikit-learn Pipeline and ColumnTransformer, first dedicate some time to understanding their full range of applications and opportunities for enhancement. There are many resources available online, including tutorials and communities of users that can offer guidance and insight.
Implement these tools in your own projects: The only way to truly understand the benefits and challenges of Scikit-learn Pipeline and ColumnTransformer is to use them. Start by incorporating these tools into your existing projects and gradually build your expertise.
In conclusion, the use of Scikit-learn Pipeline and ColumnTransformer in improving the quality of machine learning code marks a significant step forward in the field. Being open to learning and integrating these tools into your coding practices is key to staying ahead in the vibrant and rapidly developing sector of artificial intelligence and machine learning.
Image source: Dall-e This week, the tech community has been abuzz with the announcement of the latest model from Mistral being closed source. This revelation confirms a suspicion held by many: the concept of open-source Large Language Models (LLMs) today is more a marketing term than a substantive promise. Historically, open source has been championed… Read More »Open source LLMs – no more than a marketing term?
Analysis of Closed Source Approach by Mistral: Implications and Future Developments
Over the past week, there has been significant discussion in the tech community about Mistral’s announcement that its latest model will follow a “closed source” approach. This surprised a number of observers, notably due to the present prominence of open-source Large Language Models (LLMs) in the field. Contrary to the open-source ideal of freely available and modifiable code, Mistral’s decision indicates a potential shift in the industry. In this context, suspicions that the heralded concept of open-source LLMs is more of a marketing term than a genuine commitment have been validated.
Implications of a Closed Source LLM
The move by Mistral implies a significant strategy pivot and may indicate a broader industry trend. Though the open-source model has historically been celebrated for fostering innovation, transparency, and collective problem-solving, the shift of such a pivotal player to a more reserved, ‘closed source’ model raises potential concerns for the ongoing openness of LLMs.
Potential Challenges
Reduced Transparency: With the source code not openly available, there is less opportunity for oversight and for ensuring that LLMs are free from bias and manipulation.
Fewer learning opportunities: The closed source approach also means that those who wish to study or build upon existing models will not have the opportunity to do so.
Collaboration and Creativity: A key advantage of the open-source model is the innovation that springs from diverse minds working collaboratively. Closing the source code could potentially stifle this.
Future Developments and Actonable Insights
Despite the potential challenges, the future is not necessarily bleak. The industry has often shown its capacity to adapt and evolve in response to shifts such as these. Integral to this evolution, however, is the need for informed debates about the implications of such moves and how to mitigate any potential drawbacks.
Adapting to a Closed Source Model
Advocacy for Transparency: It is now more essential than ever to lobby for greater transparency within the AI and LLM industry, irrespective of the source model utilized.
Greater Regulation: If more companies decide to follow Mistral’s path, there will be an increasing need for regulation to ensure that LLMs are unbiased and safe.
Industry Collaboration: Increased cooperation between open and closed source proponents could ensure that development and learning opportunities remain available.
Conclusively, while Mistral’s decision to move to a closed-source model poses potential challenges in terms of transparency and collaboration, it may also represent a chance for the tech community to push for responsible AI development practices and greater regulation. With these actions, it’s possible to mitigate potential drawbacks and continue fostering innovation in the space.
All files (xlsx with puzzle and R with solution) for each and every puzzle are available on my Github. Enjoy.
Puzzle #161
This week comes with some of hardest challenges I faced on ExcelBI series. It was looking pretty straightforward, but later I realised what is going on. One of the least used measures describing set of data is so called mode or dominant. It points most commonly used value, and it is barely similar to mean or median.
So the story… we have weeks with winning numbers, and for each week we need to find most commonly occuring number in period of 8 weeks (current and 7 priors). I must admit that in two rows I don’t have exactly the same output as in given solution, but… it can not finish any closer. Let’s look at it.
Load libraries and data
library(tidyverse)
library(readxl)
input = read_excel("Power Query/PQ_Challenge_161.xlsx", range = "A1:C30") %>% janitor::clean_names()
test = read_excel("Power Query/PQ_Challenge_161.xlsx", range = "E1:H30") %>% janitor::clean_names()
If you can find flaws in my code, and fix it, be brave and do it.
#Puzzle 162
Usually after storm we see a rainbow… After hard challenge, we get something that we can have fun solving without headache caused by level of dificulty. And today we have pattern extracting. REGEXP rules again. In random string we need to find Letter and two Digits that are divided by exactly one character that is not Letter or Digit. Can be space, dollar sign, hyphen… whatever you want. And as result we need to give extracted patterns without those special signs in, concatenated. Easy Peasy…
Load libraries and data
library(tidyverse)
library(readxl)
input = read_excel("Power Query/PQ_Challenge_162.xlsx", range = "A1:A10")
test = read_excel("Power Query/PQ_Challenge_162.xlsx", range = "C1:D10")
Long-Term Implications and Possible Future Developments
The approach used by the author to solve the ExcelBI puzzles #161 and #162 utilizing R showcases the versatility of machine learning (ML) and data analysis tools for handling and manipulating complex data structures. The example also highlights how simple commands can be implemented in order to solve inherently complicated problems.
Going forward, the use of advanced programming languages such as R in solving data-related puzzles opens up immense potential for future development in various sectors such as analytics, artificial intelligence (AI), and machine learning. These sectors widely use programming languages like R because of their varied capabilities to handle complex data sets, thereby improving the accuracy and speed of arriving at solutions.
Actionable Advice
Improved Data Handling
The example provided in the puzzles manifests the effective usage of ML tools in data handling, which can be a guide to many data analytics professionals. Applying similar logic and steps, professionals can manipulate complex data structures to solve real-world problems related to data analysis and AI. Therefore, it is highly recommended to understand and utilize these techniques to drive better insights from data.
Collaboration and Open-Source Learning
The author communicated the necessary steps in an open-source manner and encouraged other coders to identify any flaws and work jointly towards a solution. Such initiatives not only inspire collaboration but also promote a learning environment where individuals can learn from each other’s mistakes and improvements. The coding community is encouraged to continue in this path for ensuring a more comprehensive understanding and application of these concepts in real-world scenarios.
Continual Learning and Updating Skills
Considering the challenging nature of these puzzles, it was evident that individuals need to continually learn and update their knowledge on these programming tools in order to achieve optimal solutions. Therefore, active engagement in such puzzles and challenges is a great way to elevate one’s programming skills and stay updated with the latest techniques and methodologies in the industry.
Interdisciplinary Use
Similar strategies, when implemented with a focus on real-world applicability, can be beneficial across different sectors and industries. For example, the financial sector can utilize these programming strategies for complex data handling and forecasting. Therefore, individuals are encouraged to leverage these skills in a cross-disciplinary manner to derive superior insights.
Industry Engagement
Additionally, many programming and data science platforms regularly host such coding puzzles and challenges. These platforms also occasionally provide job postings for skilled individuals. Therefore, active participation in these challenges does not merely boost your coding skills but also opens avenues for industry engagement and potential job opportunities.
This article has shown how transfer learning can be used to help you solve small data problems, while also highlighting the benefits of using it in other fields.
Long-term Implications and Future Developments in Transfer Learning
The original article reveals the potential of transfer learning as a tool to solve small data problems while also demonstrating its role in various fields. Granting a closer analysis, new perspectives arise concerning possible changes in its application and future development.
Long-term implications of transfer learning
Transfer learning is poised to meaningfully impact various fields in the long term, from healthcare to finance. One of the significant implications could be an increase in efficiency and efficacy in decisions, creating a beneficial upturn in results (especially in fields where timely and accurate decision-making is crucial).
Additionally, transfer learning could also pave the way for a reduction in costs, especially in scenarios where data collection is expensive or impractical. By using data acquired from other tasks, organizations can make full use of their databases, transforming them into valuable and actionable insights.
Future developments in transfer learning
We can predict an increase in the potency, scope, and application of transfer learning in the future. We should anticipate changes in the algorithms used in transfer learning, making them more efficient, reducing their cognitive requirements, and enabling them to handle more complex tasks.
There’s also potential for future development in the breadth of usage. Transfer learning may eventually find applications in new, unexplored fields, further diversifying its utility.
Actionable Advice
Given these insights, a few key pieces of advice arise:
Invest in transfer learning expertise: With the diverse applications and immense future potential of transfer learning, investing in this expertise now can provide a competitive edge in the future.
Explore collaborations: The ability of transfer learning to leverage data from different tasks opens up possibilities for fruitful collaborations. Look for potential partners to share data and insights.
Stay ahead of the curve: Keep an eye on emerging trends and developments in transfer learning to ensure your organization can adapt and stay ahead.
Conclusion
In conclusion, the use and development of transfer learning offer promising prospects in solving small data problems and its applications in various fields. Embracing these future potentials by staying informed and proactive is advisable for any organization aiming to thrive in the data-driven future.
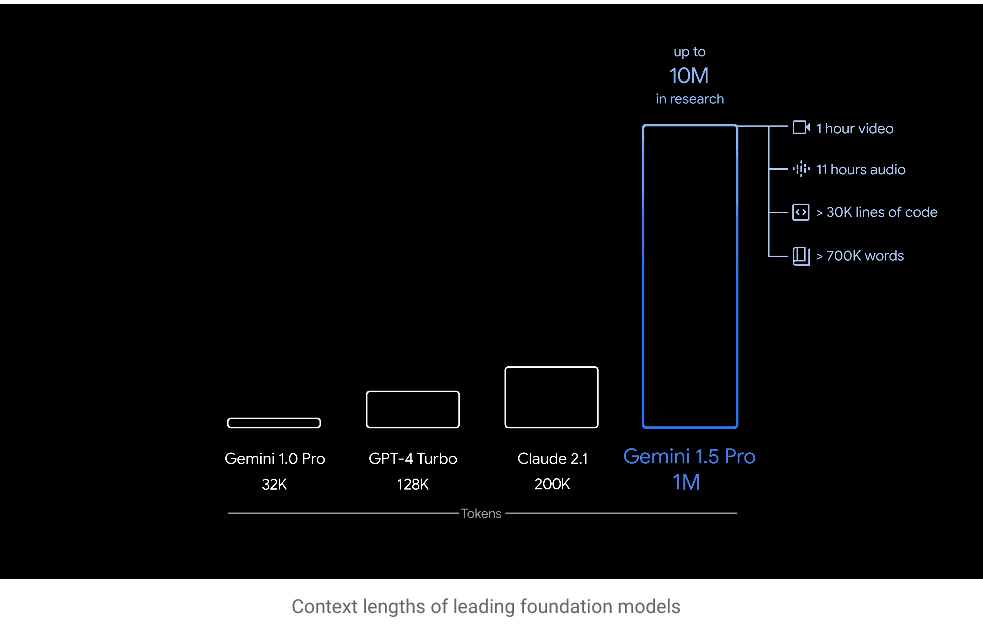
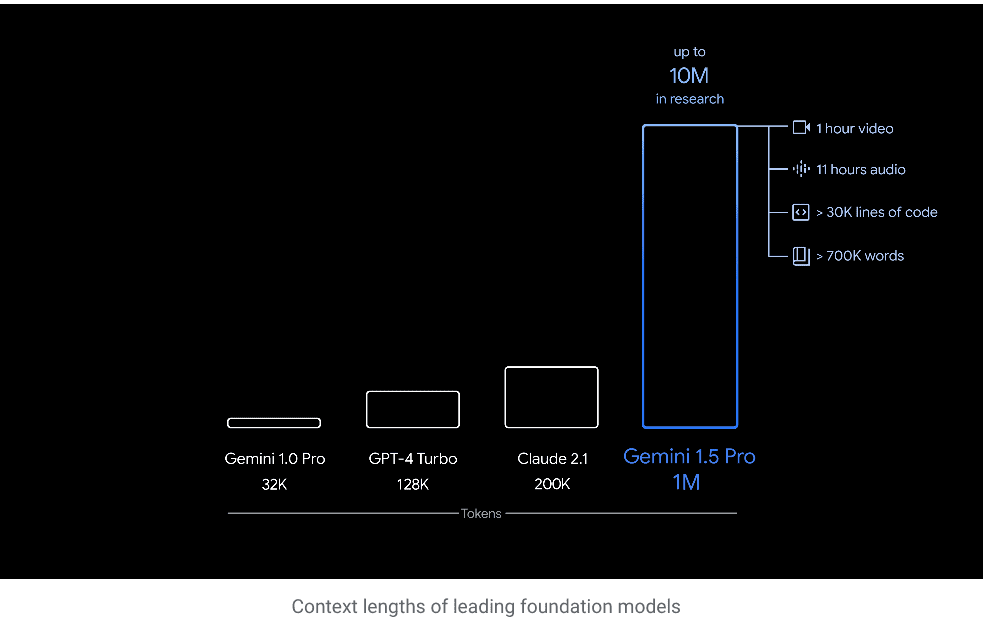
Image source https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/ Current LLM applications are mostly based on langchain or llamaindex. langChain and LlamaIndex are frameworks designed for LLM development. They each cater to different use cases with unique features. LangChain is a framework ideal for creating data-aware and agent-based applications. It offers high-level APIs for easy integration with various large language model (LLM)… Read More »Future of LLM application development – impact of Gemini 1.5 Pro with a 1M context window,
The Future of LLM Application Development
The digital landscape is always on the move, bringing with it new technologies and algorithms designed to revolutionize the way we work and interact. One advancement causing waves within artificial intelligence is the development of Large Language Models (LLM). Current LLM applications are predominantly based on two frameworks: langChain and LlamaIndex, both designed with unique features for separate use-cases. However, with the emergence of Google’s Gemini 1.5 Pro, the face of LLM application development may soon undergo a major transformation.
LangChain and LlamaIndex: Leaders in LLM Applications
LangChain and LlamaIndex have set themselves apart as the leading frameworks for LLM development. LangChain excels at creating data-aware and agent-based applications, providing high-level APIs for seamless integration with various LLMs. On the other hand, LlamaIndex caters to a different set of application development requirements. But despite their strengths, these two frameworks might soon have to contend with a fresh competitor: Google’s Gemini 1.5 Pro.
The Impact of Google’s Gemini 1.5 Pro
Google Gemini 1.5 Pro brings with it the promise of a significant impact on the future of LLM application development. This model stands out for its impressive 1M context window, an astounding leap from traditional models.
Long-Term Implications
The introduction of Google’s Gemini 1.5 Pro could potentially set new standards in LLM application development. With its enhanced capabilities, it may result in a shift in the current frameworks used, leading to an increased use of Gemini 1.5 Pro relative to langChain or LlamaIndex. This shift could stimulate changes in development practices, with a focus on harnessing the unique features that the Gemini model offers.
Possible Future Developments
This change could drive innovation in AI development, leading to new applications and use-cases being discovered. More efficient and sophisticated language-based applications could emerge, greatly enhancing user-experience and digital interactions. Further, this could also foster increased competition amongst AI development companies, potentially leading to more advanced LLM frameworks and models in the future.
Actionable Advice
Stay updated: With the AI landscape changing rapidly, it’s vital for developers and businesses to stay abreast with the latest frameworks and models. Regularly review new releases and updates in the field.
Invest in training: It’s crucial to invest in upskilling your teams to handle newer models like Gemini 1.5 Pro. This could involve online courses, industry seminars, or workshops.
Explore new use-cases: Leveraging the capabilities of advanced models such as Gemini 1.5 Pro can potentially open up new applications. Explore these possibilities actively to stay ahead of the competition.
In conclusion, while LangChain and LlamaIndex continue to serve as sturdy foundations for today’s LLM application development, the introduction of more advanced models such as Google’s Gemini 1.5 Pro is set to change the landscape. Businesses and developers must prepare for these developments and adapt to stay relevant in the increasingly competitive AI industry.