by jsendak | Nov 27, 2025 | DS Articles

Discover how AI is revolutionizing cybersecurity with advanced threat detection, predictive analysis, and automated responses, powered by GPU technology to combat evolving cyber threats.
Long-Term Implications and Future Developments in AI-Powered Cybersecurity
Artificial Intelligence (AI) has initiated a revolutionary transformation in the cybersecurity industry through advanced threat detection, predictive analysis, and automated responses. Its integration with Graphic Processing Units (GPU) technology has greatly enhanced the combat strategies against evolving cyber threats, which indicates game-changing future developments.
Predictive Analysis for Proactive Defense
One of the integral features of AI in cybersecurity is predictive analysis, an advanced technique to foresee potential cyber threats based on patterns and trends in data. This proactive approach to cybersecurity could greatly reduce the number of successful cyber-attacks in the future by detecting potential threats before they cause damage.
Automated Responses to Accelerate Threat Management
AI’s ability to automate responses to detected cyber threats can significantly increase the speed of threat management. If refined further, this capability might replace various manual activities currently conducted by cybersecurity professionals, thereby enhancing efficiency and reducing response time.
Integrated GPU Technology for Superior Performance
The addition of GPU technology in AI-powered cybersecurity algorithms has boosted threat detection and response times. Future innovations in this technology can help improve these features and augment the capability to handle concurrent tasks, contributing significantly to the evolution of cybersecurity capabilities.
Considerations for the Future
While these developments shed an optimistic light on the future of cybersecurity, some considerations must not be overlooked, including:
- Continuous learning: As cyber threats evolve, so too must the AI systems designed to counter them. Continuous learning models will be vital in maintaining the efficacy of AI in cybersecurity.
- Regulation: Guidelines and regulatory policies concerning the use of AI in cybersecurity will play an important role in governing its application and managing ethical concerns.
- Reliance on AI: With greater automation and predictive capabilities, organizations might become overly reliant on AI, potentially reducing the role of human cybersecurity professionals and related job opportunities.
Actionable Advice
Given the technological advancements and various considerations, here is some practical advice for organizations:
- Invest in continuous learning: As AI develops, continuous learning models and data updating should be priorities.
- Advocate for sound regulation: Encourage the development of clear regulations for the use of AI in cybersecurity to ensure ethical and effective application.
- Balance AI and human skill: While leveraging AI for predictive and automated responses, human expertise should still play a role in maintaining effective cyber defense mechanisms.
Through proper application and continuous advancement, AI stands to revolutionize the cybersecurity landscape, driving proactive defense strategies and enhancing response times. However, a balanced approach will be critical in ensuring the responsible use of AI.
Read the original article
by jsendak | Nov 7, 2025 | DS Articles
[This article was first published on
r.iresmi.net, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Day 7 of 30DayMapChallenge: « Accessibility » (previously).
Well, let us be rebellious and instead seek inaccessibility; more precisely the pole of inaccessibility of France (the Hexagon): the farthest location from the boundary. Not to be confused with the centroid.
library(sf)
library(dplyr)
library(ggplot2)
library(glue)
library(purrr)
library(polylabelr)
Data
We’ll use again the french administrative units (get the data from this post).
# France boundary
fr <- read_sf("~/data/adminexpress/adminexpress_cog_simpl_000_2022.gpkg",
layer = "region") |>
filter(insee_reg > "06",
insee_reg != "94") |>
st_transform("EPSG:2154") |>
st_union()
# French communes to get the point name
com <- read_sf("~/data/adminexpress/adminexpress_cog_simpl_000_2022.gpkg",
layer = "commune") |>
filter(insee_reg > "06",
insee_reg != "94") |>
st_transform("EPSG:2154")
Compute the POI
Get the inaccessibility pole of France with {polylabelr} and intersects with the commune layer to find the nearest city.
fr_poi <- poi(fr) |>
pluck(1) |>
as_tibble() |>
st_as_sf(coords = c("x", "y"), crs = "EPSG:2154") |>
st_join(com)
fr_poi_circle <- fr_poi |>
mutate(geometry = st_buffer(geometry, dist))
fr_centroid <- fr |>
st_centroid()
It seems to be in Saint-Palais in the Cher département.
Map
fr_poi |>
ggplot() +
geom_sf(data = fr) +
geom_sf(data = fr_poi_circle, linewidth = 1, linetype = 3) +
geom_sf(data = fr_centroid, color = "darkgrey") +
geom_sf() +
geom_sf_text(aes(label = nom), vjust = -.5) +
labs(title = "Pole of inaccessibility",
subtitle = "France",
x = "", y = "",
caption = glue("https://r.iresmi.net/ - {Sys.Date()}
data from IGN Adminexpress 2022")) +
theme_minimal() +
theme(plot.caption = element_text(size = 6,
color = "darkgrey"))
Continue reading: Inaccessibility
Long-term Implications and Possible Future Developments
The analysis shared in the content reveals an interesting approach to understanding geographical inaccessibility. Instead of seeking out the most accessible points, the analysis turns the table to locate the pole of inaccessibility in France. However, this approach has long-term implications and can lead to several future developments.
Implications
Identifying and analyzing the poles of inaccessibility can have widespread implications not just in geographical studies but also in planning and development. Such information can be crucial for various sectors, including infrastructure development, disaster management, transportation planning, and much more. For instance, knowing the least accessible areas could help in planning future infrastructural expansion or even identifying regions that would need additional resources in case of emergencies.
Possible Future Developments
In the future, such analyses could not only be restricted to countries like France but could be extended to global data. With advanced mapping and data technologies like GIS combined with programming languages such as R, comprehensive global maps showing poles of inaccessibility can be created. At a more micro level, these analyses could be carried out for cities, states or regions to understand a more detailed view of inaccessibility.
Moreover, this kind of approach might pave the way for integrative studies involving mapping, data analysis, and machine learning to better predict areas of potential infrastructural or developmental issues.
Actionable Advice
Organizations or individuals involved in planning and development, geographical studies, disaster management, and similar fields should consider integrating such analyses into their regular assessments.
- Leverage available data: Utilize the vast amount of geographic and demographic data available for better planning and decision making.
- Invest in skills: Invest in learning or outsourcing skills in R or other programming languages with strong data analysis capabilities.
- Encourage Innovation: Instead of sticking to traditional forms of analysis, encourage the use of innovative methods such as the pole of inaccessibility to understand a different perspective.
In conclusion, the given text details a unique approach in the field of geographical data analysis. When used thoughtfully, such methods can offer fresh insights and possibly transform the way we plan and make decisions.
Read the original article
by jsendak | Nov 7, 2025 | DS Articles
Begin your AI and data journey for free at 365 Data Science.
Impacts and Future Prospects of AI and Data Science Learning
The transition towards a data-driven world has created an increasing demand for skills in artificial intelligence (AI) and data science. With a platform like 365 Data Science providing free access to data science learning, several long-term implications and potential future developments come to the forefront.
Long-term Implications
By enabling free access to AI and data science learning, the global workforce can increase their understanding and proficiency in these critical areas. This not only enhances individual capabilities but can drastically change businesses, industries, and economies. If used effectively, the insights gained from data science can inform decisions, improve operations, support innovation and drive growth.
The integration of AI and data science in various sectors heralds an era of advanced analytics and smarter, data-driven solutions.
This progression also prompts a change in the job market. There is a growing need for professionals skilled in data interpretation and AI. As more people gain these skills, we can expect a surge in qualified professionals tackling complex data-related challenges.
Potential Future Developments
With more people having access to AI and data science training, we can anticipate the rise of more innovative solutions in these fields. Thus, the evolution and expansion of AI and data-related technologies, like machine learning and predictive analytics, can speed up.
In a world powered by data, the democratization of AI and data science learning also means that individuals from different backgrounds can contribute to the tech industry’s diversity. This can stimulate further innovation and foster inclusivity within the sector.
Actionable advice
- Keep Learning: With data science and AI constantly evolving, continuous learning and skill enhancement is crucial. Platforms like 365 Data Science can provide the necessary resources.
- Apply Your Skills: As the need for professionals with data science and AI skills grows, take advantage of the opportunities available in the job market.
- Innovate: Use your newfound knowledge to devise data-driven solutions for complex issues in various sectors.
- Encourage Diversity: Advocate for and contribute to the diversity of the tech industry.
In conclusion, the free access to AI and data science learning presents an invaluable opportunity for individuals and organizations. Embracing this burgeoning field today can pave the way for remarkable developments and innovations in the future.
Read the original article
by jsendak | Nov 6, 2025 | DS Articles
[This article was first published on
r.iresmi.net, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Day 6 of 30DayMapChallenge: « Dimensions » (previously).
According to Wikipedia, Uniform manifold approximation and projection (UMAP) is a nonlinear dimensionality reduction technique
. It will allow us to project many dimensions (well, only 3 in this example) onto a 2D plane.
library(sf)
library(umap)
library(dplyr)
library(tidyr)
library(ggplot2)
library(ggrepel)
library(glue)
options(scipen = 100)
Data
We’ll use the french communes (get the data from this post).
com <- read_sf("~/data/adminexpress/adminexpress_cog_simpl_000_2022.gpkg",
layer = "commune") |>
st_centroid() |>
mutate(x = st_coordinates(geom)[, 1],
y = st_coordinates(geom)[, 2])
UMAP
The dimensions taken into account are: location (x, y) and population. These variables should be scaled but the result is prettier without scaling…
umaps_params <- umap.defaults
umaps_params$random_state <- 20251106
com_umap <- com |>
st_drop_geometry() |>
select(x, y, population) |>
# scale() |>
umap(config = umaps_params)
res <- com_umap$layout |>
as_tibble(.name_repair = "universal") |>
bind_cols(com) |>
rename(UMAP1 = 1,
UMAP2 = 2)
Map
res |>
ggplot(aes(UMAP1, UMAP2, color = population)) +
geom_point() +
geom_text_repel(data = filter(res,
statut %in% c("Préfecture",
"Préfecture de région",
"Capitale d'état")),
aes(label = nom),
size = 3, force = .5, force_pull = 0.5, max.overlaps = 1e6,
bg.colour = "#ffffffaa", bg.r = .2, alpha = .6) +
scale_color_viridis_c(trans = "log1p", option = "H",
breaks = c(1000, 50000, 500000, 2000000)) +
coord_equal() +
labs(title = "Uniform manifold approximation and projection of french communes",
subtitle = "by location and population",
caption = glue("https://r.iresmi.net/ - {Sys.Date()}
data from IGN Adminexpress 2022")) +
theme_minimal() +
theme(plot.caption = element_text(size = 6,
color = "darkgrey"))
Continue reading: Dimension reduction
Long-Term Implications and Possible Developments of Applying UMAP
The article details the application of Uniform Manifold Approximation and Projection (UMAP), a nonlinear dimensionality reduction technique, to project dimensions onto a two-dimensional plane. In this case, it’s utilized to represent the french communes based on location and population.
The potential implications of effectively implementing and furthering the development of techniques like UMAP are wide-reaching.
Advanced Data Visualization and Analysis
With UMAP, visualizing complex, high-dimensional data becomes easier and more intuitive. Analysts can understand intricate relationships between different parameters more effectively. Future developments might lead to more powerful dimensionality reduction techniques, enabling easier interpretation of even higher-dimensionality datasets.
Improved Efficiency
Reducing dimensionality usually speeds up computation without losing too much information, which can be a significant advantage when dealing with particularly large datasets. The continual amelioration of algorithms like UMAP could lead to even more efficient data processing algorithms in the future.
Enhanced Machine Learning Models
Dimensionality reduction is crucial in many machine learning applications as it can help to mitigate the curse of dimensionality and reduce overfitting. Therefore, improvements in this field can lead to more accurate and reliable machine learning models.
Actionable Advice
The application of UMAP or similar dimensionality reduction techniques could be beneficial for any business or researcher dealing with large, complex datasets. However, it’s crucial to understand where and how to use these tools effectively.
- Upskill in data analysis techniques: The R programming language offers a wealth of packages and functions, such as UMAP, which can be beneficial for data analysis. Learning to work with these advanced tools would be a profitable upskill move for any data scientist or analyst.
- Apply dimensionality reduction thoughtfully: While dimensionality reduction can be beneficial to simplify data analysis and visualizations, it should be used judiciously. It is important to understand that some data loss happens during the dimensionality reduction process. It’s crucial to ensure that the resulting model retains the essential features that will give the most accurate outcomes.
- Keep up with latest developments: The field of data science is rapidly evolving, with new methods and tools developing constantly. Keep up-to-date with the latest research – tomorrow’s groundbreaking technique could be just around the corner.
Read the original article
by jsendak | Nov 6, 2025 | DS Articles
Learn how developers and data scientists use SerpApi to automate real-time search data collection for AI model training and analytics workflows.
Analyzing the Key Points of Real-time Search Data Collection
SerpApi is a tool that helps developers and data scientists automate the process of real-time search data collection. This tool is especially geared towards AI model training and analytics workflows. Considering this information, let’s evaluate the long-term implications and possible future developments.
Long-term Implications and Possible Future Developments
The emergence of services like SerpApi is indicative of the increasing reliance on machine learning technologies in the field of data analysis. Over the long term, the automation of search data collection would significantly enhance efficiency in these processes, allowing for more accurate and rapid insights.
The future of real-time data collection services like SerpApi appears bright. As more businesses adopt AI-based technologies for operational efficiency, the demand for similar services is poised to rise. Furthermore, with future advances in AI and machine learning, these search data collection tools may become even more efficient and sophisticated.
Actionable Advice
Based on these insights, it is prudent for businesses and individuals in the field of data science or AI development to familiarize themselves with services like SerpApi. Below is some actionable advice:
- Educate Yourself and Your Team: Ensure that your team is proficient in AI model training and analytics workflows. Additionally, familiarize yourselves with tools like SerpApi to navigate the shift towards automated real-time search data collection.
- Invest in Automation: Businesses should consider investing in machine learning technologies. These solutions streamline operations, reduce task redundancy, and ultimately improve efficiency and decision-making.
- Stay Informed: The field of AI and machine learning is perpetually evolving. It is important to stay up-to-date with the latest developments. This will not only provide competitive advantage, but also facilitate better decision-making strategies in the long run.
By leveraging tools such as SerpApi, you can streamline your data analysis processes, derive insights faster, and ultimately drive your business forward in the AI-driven world of tomorrow.
Read the original article
by jsendak | Nov 6, 2025 | DS Articles
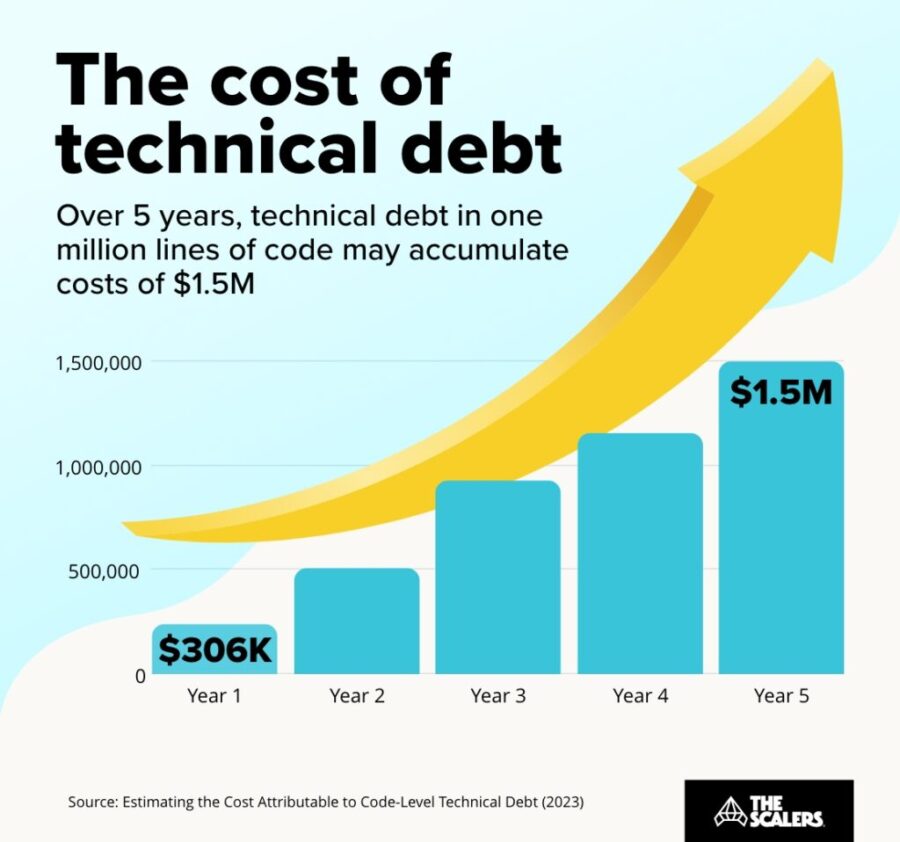
Discover the hidden price of not being AI-ready. Learn how enterprise legacy data warehouses accumulate technical debt, and calculate the true Total Cost of Inaction.
Exploring The Financial Implications of Not Being AI-Ready
As technology advances at an unprecedented pace, businesses clinging to outdated systems, such as enterprise legacy data warehouses, are finding themselves at a significant disadvantage. More importantly, their decision to delay digital transformation is accumulating invisible costs or ‘technical debt.’ Understanding and calculating these costs is critical in assessing the Total Cost of Inaction.
The Cost of Technical Debt
Technical debt is not necessarily a result of poor decisions or mistakes. It is often an unintended consequence of prioritizing quick solutions over long-term planning. However, as short-term fixes pile up, systems become increasingly complex, outdated, and difficult to maintain, resulting in a larger than anticipated expenditure over time.
The rising technical debt due to legacy systems
Legacy data warehouses were once a workhorse of data analytics. But as data volumes ramp up, these systems become a bottleneck, unable to keep up with scale-up requirements and newer, faster technologies. A company’s inability to leverage data effectively causes not only operational inefficiencies but also negative impacts on decision-making processes.
Calculating the Total Cost of Inaction
Placing an explicit value on the cost of not upgrading to AI-ready systems can be challenging, but it is necessary for a comprehensive financial and strategic analysis. Factors to consider while calculating the Total Cost of Inaction include:
- Cost of lost business opportunities: Opportunities missed through inefficiency or due to the inability to leverage data to drive insights and actions.
- Operational costs: The costs to maintain and repair outdated systems which tend to require more resources and time.
- Compliance costs: Higher costs of compliance when dealing with systems that do not meet modern security standards.
Future Implications and Development
As businesses increasingly adopt AI and machine learning tools, the technological gap between AI-ready and non-AI companies will widen. Companies with AI-ready systems are likely to enjoy greater operational efficiency, better data-driven decision making and a stronger competitive advantage. From a broader perspective, the lack of readiness may even affect the company’s position in the market, its credibility, and potential for growth.
Actionable Recommendations
Organizations should consider the following steps to mitigate technical debt and navigate the path towards becoming AI-ready:
- Invest in upgrading systems: Seek out modern, scalable solutions designed with artificial intelligence capabilities in mind.
- Train staff: Invest in training employees to manage and leverage new technologies effectively.
- Align technology with the business strategy: Ensure the technology strategy aligns with broader business objectives and growing customer needs.
It is important to view the transition towards being AI-ready not as a cost, but as an investment towards future-proofing the organization for the emerging digital world.
Read the original article