Want to move into the data science field? Or advance your career in the data Don’t miss these must-have skills.
Unveiling the Must-Have Skills for a Successful Career in Data Science
Moving into the data science field or seeking to advance your career in data necessitates specific skills. Analyzing the key points in this text will help develop a thorough understanding of necessary skills and provide advice for future developments in this rapidly growing field.
Long-Term Implications and Possible Future Developments
As technologies evolve and become more sophisticated, skill needs for the data science field also change. Understanding these future developments can help prospective data scientists prepare themselves better.
In this Era of Big Data, the ability to interpret and analyze complex datasets is the most crucial skill. With an increasing amount of data generated every day, the demand for data science professionals is likely to climb in the future, which further highlights the necessity for these skills. Data scientists with these skills will remain in high-demand and will continue to command a premium in the market.
Actionable Advice Based on These Insights
For individuals interested in data science careers, developing the right skills is essential. The path towards a prosperous career in data science includes:
Mastering programming languages: Knowing Python, R, and SQL is essential. Start with Python as it’s easy to learn and widely used in data science.
Understanding Data Structures and Algorithms: As a data scientist, you will often deal with large, complex data sets. Thus, you should have a sound knowledge of data structures and algorithms.
Getting familiar with Machine Learning: Machine Learning is an integral part of many advanced data analysis processes. A basic understanding of Machine Learning algorithms is a must.
Improving Statistical Skills: Data science is deeply rooted in statistics. Without solid statistical skills, it’s challenging to interpret and analyze data effectively.
Practicing Data Visualization: A good data scientist should be able to represent complex data in an easy-to-understand format. Skills in data visualization tools like Tableau, Power BI, or R Shiny are beneficial.
Wrapping Up
As data science continues to evolve, it’s crucial to keep learning and updating your skills. Continuous learning, practice, and application of these skills in real-life data projects can give you an edge in the constantly growing data science market.
It is the International Brain Awareness Week for 2024, with events across institutes, globally, from March 11 – 17. This week is a good time to explore the pedestal of the brain, against the astounding rise of machines. AI embodiment was recently featured in Scientific American, AI Chatbot Brains Are Going Inside Robot Bodies. What… Read More »Embodied AI: Would LLMs and robots surpass the human brain?
LONG-TERM IMPLICATIONS AND FUTURE DEVELOPMENTS OF EMBODIED AI
Introduction
In the midst of the International Brain Awareness Week, it is essential to delve into the ever-evolving domain of artificial intelligence (AI) and how it may pose possible comparisons with the human brain. The concept of embodied AI, where AI systems are integrated within robot bodies, recently highlighted in Scientific American, raises many intriguing questions about the potential capabilities of such technology.
Understanding Embodied AI
Embodied AI comprises AI systems inextricably merged with robotic entities. Rather than merely functioning through a virtual chatbot, these AI systems can now interact with the real world. The benefits of this technology ranges from increased efficiency to potential solutions in sectors such as healthcare, manufacturing, education, and others.
Potential Implications
The evolutionary possibilities carry long-term implications. If the ongoing trend of technological advancement continues at its current pace, embodied AI could potentially achieve a level of intelligence beyond human capacity.
Surpassing Human Brain Capacity: While this may seem far-fetched, given certain advancements, it is plausible that over time, with the help of machine learning models (LLMs), robots could perhaps reach or even surpass the level of human brain intelligence.
Revolutionizing Industries: With the integration of LLMs in robotics, automation levels could reach unprecedented heights, bringing about enormous changes in industries. This could lead to increased efficiency and accuracy, drastically reshaping the global economy.
Ethical Implications: However, such developments also highlight ethical concerns about the development and deployment of AI. Concerns related to privacy, cybersecurity, and job displacement are likely to become more pronounced.
Possible Future Developments
The ongoing research in embodied AI indicates that our relationship with technology is only going to become more refined and complex. Here are some possible future developments:
The functionality of AI could evolve to become more human-like, enhancing user engagement and AI utilization.
Embodied AI could be harnessed to solve complex real-world problems, such as those related to climate change or disease outbreak prevention.
Regulations and ethical guidelines surrounding AI could become stricter, aiming to minimize potential mishaps or abuses of technology.
Actionable Advice
The rise of embodied AI raises important considerations for individuals, businesses, and society at large. Therefore, it is advisable to:
Stay informed about the latest developments in AI and understand their implications.
Incorporate embodied AI solutions in business practices, where applicable, for increased efficiency and innovation.
Support and advocate for responsible AI usage, advocating for privacy protection and ethical considerations in AI development and application.
All files (xlsx with puzzle and R with solution) for each and every puzzle are available on my Github. Enjoy.
Puzzle #404
Can analyst make something that looks good? Of course… Can analyst draw with numbers? Once more yeah. But today, like some times in past already, we have another way. I usually name making charts and dashboards — drawing or painting with numbers. Not today. We just recreate one specific graphic filling fields of spreadsheet (or in our case, make this graphic in console). And as you see above it is… Star-Spangled Banner aka flag of the USA.
Load libraries and data
library(tidyverse)
library(readxl)
test = read_excel("Excel/404 Generate US ASCII Flag.xlsx", range = "A1:AL15",
col_names = FALSE, .name_repair = "unique") %>% as.matrix()
# remove attribute "names" from matrix
attr(test, "dimnames") = NULL
result = matrix(NA, nrow = 15, ncol = 38)r
Transformation
# border of flag
result[1,] = "-"
result[15,] = "-"
result[2:14,1] = "|"
result[2:14,38] = "|"
# stripe section
for (i in 2:14){
for (j in 2:37){
if (i %% 2 == 0){
result[i,j] = 0
} else {
result[i,j] = "1"
}
}
}
# star section
for (i in 2:10){
for (j in 2:12){
if (i %% 2 == 0){
if (j %% 2 == 0){
result[i,j] = "*"
} else {
result[i,j] = NA
}
} else {
if (j %% 2 == 0){
result[i,j] = NA
} else {
result[i,j] = "*"
}
}
}
}
Validation
identical(result, test)
# [1] TRUE
Puzzle #405
Did you know sandwich numbers? That is that unique kind of numbers that as both neighbours has prime numbers, so they are like between two slices of toast bread. And our task is to find first 100 of sandwich numbers together with their “breads” aka neighbouring primes.
Load libraries and data
library(tidyverse)
library(readxl)
test = read_excel("Excel/405 Sandwich Numbers.xlsx", range = "A1:C101") %>% janitor::clean_names()
Transformation
is_prime <- function(x) {
if (x <= 1) return (FALSE)
if (x == 2 || x == 3) return (TRUE)
if (x %% 2 == 0) return (FALSE)
for (i in 3:sqrt(x)) {
if (x %% i == 0) return (FALSE)
}
TRUE
} # of course I could use primes package, but I decided otherwise :D
is_sandwich <- function(x) {
is_prime(x-1) && is_prime(x+1)
}
find_first_n_sandwich_numbers <- function(no) {
keep(1:10000, is_sandwich) %>%
unlist() %>%
head(no)
}
a = find_first_n_sandwich_numbers(100)
check = tibble(sandwich_number = a) %>%
mutate(before_number = sandwich_number - 1,
after_number = sandwich_number + 1) %>%
select(2,1,3)
Validation
all.equal(test, check)
# [1] TRUE
Puzzle #406
I suppose that in every educational system at least once Pythagorean Theorem is mentioned. In this puzzle given area and length of hypotenuse we have to find length of other two sides of right angled triangle. Of course there probably is some formula to do it at once, but I wanted to show you step by step way to do it. We are gonna use library numbers to use very useful function divisors. Otherwise we would have to check every combination of numbers to find numbers behind area of triangle.
Load libraries and data
library(tidyverse)
library(readxl)
library(numbers)
input = read_excel("Excel/406 Right Angled Triangle Sides.xlsx", range = "A2:B10") %>%
janitor::clean_names()
test = read_excel("Excel/406 Ri
Transformation
process_triangle = function(area, hypotenuse) {
ab = 2 * area
ab_divisors = divisors(ab)
grid = expand_grid(a = ab_divisors, b = ab_divisors) %>%
mutate(r = a * b,
hyp = hypotenuse,
hyp_sq = hyp**2,
sides_sq = a**2+b**2,
check = hyp_sq == sides_sq,
base_shorter = a < b) %>%
filter(check, base_shorter) %>%
select(base = a, perpendicular = b)
return(grid)
}
result = input %>%
mutate(res = map2(area, hypotenuse, process_triangle)) %>%
unnest(res) %>%
select(3:4)
Validation
identical(result, test)
# [1] TRUE
Puzzle #407
I like cyphering puzzles and I am really happy that we have one again. Today we merge 2 types of cyphers: Ceasar and Mirror, so we have reverse and shift coded text to succeed. Let’s check how it went.
Load libraries and data
library(tidyverse)
library(readxl)
input = read_excel("Excel/407 Mirror Cipher.xlsx", range = "A1:B10") %>%
janitor::clean_names()
test = read_excel("Excel/407 Mirror Cipher.xlsx", range = "C1:C10") %>%
janitor::clean_names()
Time: physics, math, eternity… but does time have any geometry? Stephen Hawking probably would say something about it, but we have much easier issue. We only need to check geometry of clock face. There are two or three hands on it. As long as we present time as cycles, we use circle presenting this cycle and positions of hands on the face of round, circular face of clock are enabling us to read time measurements. So lets check what angle hands presents at specific times of a day.
Load libraries and data
library(tidyverse)
library(readxl)
input = read_excel("Excel/408 Angle Between Hour and Minute Hands.xlsx", range = "A1:A10")
test = read_excel("Excel/408 Angle Between Hour and Minute Hands.xlsx", range = "B1:B10")
Transformation
angle_per_min_hh = 360/(60*12)
angle_per_min_mh = 360/60
result = input %>%
mutate(time = as.character(Time),
Time = str_extract(time, "sd{2}:d{2}")) %>%
separate(Time, into = c("hour","mins"), sep = ":") %>%
mutate(hour = as.numeric(hour),
mins = as.numeric(mins),
hour12 = hour %% 12,
period_hh = hour12*60 + mins,
period_mh = mins,
angle_hh = period_hh * angle_per_min_hh,
angle_mh = period_mh * angle_per_min_mh,
angle_hh_to_mh = if_else(angle_hh > angle_mh,
360 - (angle_hh - angle_mh),
angle_mh - angle_hh)) %>%
select(answer_expected = angle_hh_to_mh)
# there is probably single formula for this,
# but I wanted to show you this step by step.
Analyzing ExcelBI Puzzles and Their R Package Solutions
The article focuses on an interesting series of puzzles presented by ExcelBI and their solutions using the R programming language. Each puzzle presents a programming challenge and gives insights into how data analytics and programming skills can be used to solve real-world problems. While the author mostly uses R’s base packages, there’s also usage of external libraries like tidyverse, readxl, and numbers.
Key Points from the Puzzles
Puzzle #404
In the first puzzle, the task is to reproduce the flag of USA using matrix transformations in R based on a given pattern. This task shows the versatility of R programming in graphical work besides typical numerical analysis.
Puzzle #405
Puzzle #405 talks about finding a ‘sandwich numbers’, which are numbers sandwiched between two prime numbers. This interesting task reflects the power of mathematical functions in R, such as identifying prime numbers.
Puzzle #406
Using the Pythagorean theorem, the puzzle aims to find the length of two sides in a right-angled triangle given the area and hypotenuse. Comprising mathematical functions like area calculations and hypotenuse value derivation, this puzzle demonstrates the use of R programming in geometrical problems.
Puzzle #407
Puzzle #407 presents a text deciphering task involving the use of Caesar and mirror cyphers. This shows how R can be leveraged for decryption and encoding tasks, especially useful in cybersecurity.
Puzzle #408
Finally, the last puzzle has a task to find the angle between hour and minute hands at a specific time. The problem uses mathematical transformations and notion of time to solve a real-world problem.
Future Implications and Developments
These puzzles showcase the power, versatility, and breadth of the R programming language. Not restricted to just statistical analyses, users of R can leverage its features to solve a wide range of problems, from graphical reproductions and geometrical calculations to coding cyphers.
It is expected that the role of R will continue to expand, including into non-traditional areas, given the language’s open-source nature and active community of contributors.
Actionable Advice
Enhance R Skills: The ability to handle diverse problems using R will likely become an increasingly valuable skill in the future. Therefore, learning R and improving programming skills can open up new opportunities.
Look Beyond Analytics: R isn’t just a tool for data analytics. These puzzles show that R can be used in a variety of tasks. Focus on understanding the principles and functionality of R to unlock its full potential.
Engage with the Community: The R community is a rich resource for learning and problem-solving. Don’t hesitate to engage, ask questions, and contribute when you can.
Long-term Implications and Future Developments of GPTs from the GPT Store.
Undoubtedly, the introduction of Generative Pre-training Transformers (GPTs) has revolutionously enhanced the AI and Machine Learning space. Based on the key points of the original text highlighting this rapidly progressing technology, we can anticipate potential long-term implications and future developments. Here are several probabilities and their potential impact.
Advancement in AI Language Comprehension
One of the fascinating potentials presented by GPTs is their remarkable capacity to simulate human-like language comprehension. They could significantly transform how we interact with technology, enhancing machines’ ability to understand and respond to human language more accurately.
Influence on the Automation of Tasks
As technology continues to advance, the possibility of automating various tasks formerly requiring human input becomes a reality. GPTs could drive developments leading to more sophisticated software that can accomplish tasks in diverse areas, from customer service to content creation.
Implications for Data Analysis
GPTs not only influence discourse processing but also the field of data analysis. As more business sectors increasingly rely on data-driven decision-making, GPTs could potentially revolutionize the speed and accuracy of data analytics software.
Further Development of Machine Learning
Since GPTs are based on machine learning, their usage and development will inevitably contribute to further advancements within the field, creating a continuous positive loop of growth and innovation.
Advice for the Future
Prepare for changes in the Workflow: As automation becomes more prevalent, businesses should be ready to adapt their workflows accordingly. Journey mapping and change management strategies can help smooth the transition.
Keep Up-to-date with developments: Staying informed about the latest improvements and usage of GPTs is equally crucial. Regular research and engagement with communities invested in this field can aid this.
Invest in Training and Upskilling: As tasks become more automated, the skills needed in the workplace will evolve. Training employees to work with these new systems and upskilling current IT staff will be important enhancements.
“The future is not something we enter. The future is something we create.” – Leonard I. Sweet
Embracing change and progress is necessary in order to leverage the most out of the future developments of GPTs. Therefore, proactive planning and readiness for upcoming innovations are prudent for the growth of any business.
The pros and cons of data cleaning in Python vs. data quality tools, guiding you to choose the best approach for pristine data management.
Data Cleaning in Python vs. Data Quality Tools: Key Takeaways and Long-term Implications
When managing data, the quality of the data has paramount importance. It affects the accuracy of analytics, integrity of reports, and crucially, the effectiveness of decision-making. Two of the most commonly used approaches for data management include data cleaning through Python programming and using dedicated data quality tools. Evaluating their advantages and disadvantages has major implications for both the short-term and long-term management of data.
Advantages and Disadvantages of Python for Data Cleaning
Python, an extremely powerful and versatile programming language, has proven to be incredibly useful for data cleaning. One of its biggest advantages is its flexibility. With Python, data can be manipulated and cleansed exactly as needed, provided you have the necessary expertise in code writing. It is ideal for complex or unique data cleaning tasks.
However, Python has its drawbacks. The biggest obstacle might be its requirement for firm programming skills. Not everyone working with data has the knowledge or time to learn Python in-depth. Also, it can be slow and inefficient to manually write code for each individual data cleaning task, especially for large datasets.
Pros and Cons of Dedicated Data Quality Tools
Dedicated data quality tools such as Trifacta and Talend, on the other hand, can provide a more user-friendly means of maintaining data integrity. These tools come with pre-set cleaning methods and various automation features that not only simplify the cleaning process but also significantly quicken it.
However, these tools can be costly, and they often lack the raw flexibility that Python provides. Data quality tools are best suited for standardised and recurring data cleaning tasks, with less capability for customisation for unique needs.
Future Directions
As big data trends continue to evolve, there will be an increased need for robust, efficient, and accessible data cleaning strategies. There’s potential for the further development and sophistication of dedicated data quality tools with more advanced automation and customisation features. Python will remain an important resource for its raw versatility and power.
Actionable Advice
Choosing the right approach for your data management depends on your specific requirements, budget, and staff expertise. If your environment requires bespoke data cleansing activities and you have skilled programmers in your team, Python could be the ideal solution.
On the other hand, if time is a crucial factor, or if your data cleaning needs are fairly standardised, investing in a dedicated data quality tool might be the way forward. A middle ground could also be a viable option for some, aiming for a mix of Python and data quality tools, adjusting the balance as needed based on your evolving data management needs.
The focus should be on maintaining the integrity and usability of the data at all times. It is essential to continually reassess your data cleaning strategies to ensure they stay effective in the evolving big data landscape.
[This article was first published on R-posts.com, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Shiny, without server
In previous article, I introduced method to share shiny application in static web page (github page)
At the core of this method is a technology called WASM, which is a way to load and utilize R and Shiny-related libraries and files that have been converted for use in a web browser. The main problem with wasm is that it is difficult to configure, even for R developers.
Of course, there was a way called shinylive, but unfortunately it was only available in python at the time.
Fortunately, after a few months, there is an R package that solves this configuration problem, and I will introduce how to use it to add a shiny application to a static page.
shinylive
shinylive is R package to utilize wasm above shiny. and now it has both Python and R version, and in this article will be based on the R version.
shinylive is responsible for generating HTML, Javascript, CSS, and other elements needed to create web pages, as well as wasm-related files for using shiny.
You can see examples created with shinylive at this link.
Install shinylive
While shinylive is available on CRAN, it is recommended to use the latest version from github as it may be updated from time to time, with the most recent release being 0.1.1. Additionally, pak is the recently recommended R package for installing R packages in posit, and can replace existing functions like install.packages() and remotes::install_github().
You can think of shinylive as adding a wasm to an existing shiny application, which means you need to create a shiny application first.
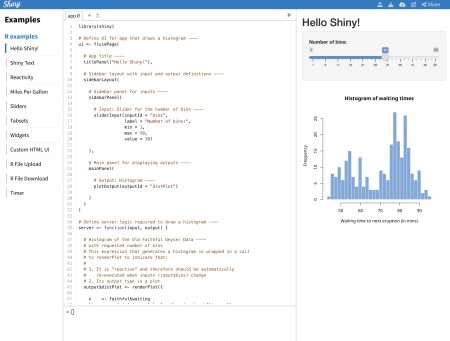
For the example, we’ll use the code provided by shiny package (which you can also see by typing shiny::runExample("01_hello") in the Rstudio console).
library(shiny)
ui <- fluidPage(
titlePanel("Hello Shiny!"),
sidebarLayout(
sidebarPanel(
sliderInput(
inputId = "bins",
label = "Number of bins:",
min = 1,
max = 50,
value = 30
)
),
mainPanel(
plotOutput(outputId = "distPlot")
)
)
)
server <- function(input, output) {
output$distPlot <- renderPlot({
x <- faithful$waiting
bins <- seq(min(x), max(x), length.out = input$bins + 1)
hist(x,
breaks = bins, col = "#75AADB", border = "white",
xlab = "Waiting time to next eruption (in mins)",
main = "Histogram of waiting times"
)
})
}
shinyApp(ui = ui, server = server)
This code creates a simple shiny application that creates a number of histograms in response to the user’s input, as shown below.
There are two ways to create a static page with this code using shinylive, one is to create it as a separate webpage (like previous article) and the other is to embed it as internal content on a quarto blog page .
First, here’s how to create a separate webpage.
shinylive via web page
To serve shiny on a separate static webpage, you’ll need to convert your app.R to a webpage using the shinylive package you installed earlier.
Based on creating a folder named shinylive in my Documents(~/Documents) and saving `app.R` inside it, here’s an example of how the export function would look like shinylive::export('~/Documents/shinylive', '~/Documents/shinylive_out')
When you run this code, it will create a new folder called shinylive_out in the same location as shinylive, (i.e. in My Documents), and inside it, it will generate the converted wasm version of shiny code using the shinylive package.
If you check the contents of this shinylive_out folder, you can see that it contains the webr, service worker, etc. mentioned in the previous post.
More specifically, the export function is responsible for adding the files from the local PC’s shinylive package assets, i.e. the library files related to shiny, to the out directory on the local PC currently running R studio.
Now, if you create a github page or something based on the contents of this folder, you can serve a static webpage that provides shiny, and you can preview the result with the command below.
To add a shiny application to a quarto blog, you need to use a separate extension. The quarto extension is a separate package that extends the functionality of quarto, similar to using R packages to add functionality to basic R.
First, we need to add the quarto extension by running the following code in the terminal (not a console) of Rstudio.
quarto add quarto-ext/shinylive
You don’t need to create a separate file to plant shiny in your quarto blog, you can use a code block called {shinylive-r}. Additionally, you need to set shinylive in the yaml of your index.qmd.
filters:
- shinylive
Then, in the {shinylive-r} block, write the contents of the app.R we created earlier.
#| standalone: true
#| viewerHeight: 800
library(shiny)
ui <- fluidPage(
titlePanel("Hello Shiny!"),
sidebarLayout(
sidebarPanel(
sliderInput(
inputId = "bins",
label = "Number of bins:",
min = 1,
max = 50,
value = 30
)
),
mainPanel(
plotOutput(outputId = "distPlot")
)
)
)
server <- function(input, output) {
output$distPlot <- renderPlot({
x <- faithful$waiting
bins <- seq(min(x), max(x), length.out = input$bins + 1)
hist(x,
breaks = bins, col = "#75AADB", border = "white",
xlab = "Waiting time to next eruption (in mins)",
main = "Histogram of waiting times"
)
})
}
shinyApp(ui = ui, server = server)
after add this in quarto blog, you may see working shiny application.
shinylive is a feature that utilizes wasm to run shiny on static pages, such as GitHub pages or quarto blogs, and is available as an R package and quarto extension, respectively.
Of course, since it is less than a year old, not all features are available, and since it uses static pages, there are disadvantages compared to utilizing a separate shiny server.
However, it is very popular for introducing shiny usage and simple statistical analysis, and you can practice it right on the website without installing R, and more features are expected to be added in the future.
The code used in blog (previous example link) can be found at the link.
The implementation of Shiny applications without a server using WebAssembly (WASM) and Shinylive offers a significant development for R developers who want to share their work in static pages, such as beta-testing of applications or blogging. This article aims to discuss the long-term implications of this development, theorize possible future developments, and provide actionable advice for developers and data scientists interested in this technique.
I. Long-term implications
1. Greater convenience and flexibility: With Shinylive and WASM, static webpage hosting becomes more feasible for R developers, allowing them to share Shiny applications easily without the need for a server. This adds flexibility and makes the distribution of applications more efficient.
2. Enhance Shiny applications: The use of Shinylive not only enhances the capabilities of Shiny applications but also simplifies the process of embedding these applications on a static webpage or a quarto blog page, expanding their potential uses and applications.
3. Increasing adoption: This accessibility to a broader range of outlets for their work may encourage increased adoption of R and Shiny among the scientific and data analysis communities.
II. Possible future developments
1. Extended features and new packages: The Shinylive package is still young, and therefore it can be expected that more features will be added in the future. Developers may build more sophisticated packages similar to Shinylive to make the most out of static pages.
2. Increasing use of WASM: WASM’s potential proves to be high in this context, suggesting it may see broader adoption and improvements that could increase efficiency for developers.
III. Actionable advice
1. Stay updated: R developers who use Shiny apps should monitor the development of Shinylive and similar packages. It is recommended to use the latest version of the package as updates are released regularly.
2. Experiment with WASM: If you are a developer, do not shy away from WASM, despite its configuration challenges. Gaining this capability could open new possibilities for your applications and bring increased convenience when sharing work.
3. Consider static page hosting: Consider the benefits of static webpage hosting for sharing applications, as well as the potential broadening of the audience for your work. This mechanism can be highly appealing due to its simplicity and cost-effectiveness compared to setting up a dedicated server.
Conclusion
WASM and Shinylive together form an innovative solution for R developers looking to share Shiny applications in a flexible, server-less environment, thus broadening their application’s reach. As technology continues to progress, one can expect further enhancements and improved efficiency in this area. R developers should look forward to these developments and be prepared to integrate them into their work processes to reap their full benefits.