This article has shown how transfer learning can be used to help you solve small data problems, while also highlighting the benefits of using it in other fields.
Long-term Implications and Future Developments in Transfer Learning
The original article reveals the potential of transfer learning as a tool to solve small data problems while also demonstrating its role in various fields. Granting a closer analysis, new perspectives arise concerning possible changes in its application and future development.
Long-term implications of transfer learning
Transfer learning is poised to meaningfully impact various fields in the long term, from healthcare to finance. One of the significant implications could be an increase in efficiency and efficacy in decisions, creating a beneficial upturn in results (especially in fields where timely and accurate decision-making is crucial).
Additionally, transfer learning could also pave the way for a reduction in costs, especially in scenarios where data collection is expensive or impractical. By using data acquired from other tasks, organizations can make full use of their databases, transforming them into valuable and actionable insights.
Future developments in transfer learning
We can predict an increase in the potency, scope, and application of transfer learning in the future. We should anticipate changes in the algorithms used in transfer learning, making them more efficient, reducing their cognitive requirements, and enabling them to handle more complex tasks.
There’s also potential for future development in the breadth of usage. Transfer learning may eventually find applications in new, unexplored fields, further diversifying its utility.
Actionable Advice
Given these insights, a few key pieces of advice arise:
Invest in transfer learning expertise: With the diverse applications and immense future potential of transfer learning, investing in this expertise now can provide a competitive edge in the future.
Explore collaborations: The ability of transfer learning to leverage data from different tasks opens up possibilities for fruitful collaborations. Look for potential partners to share data and insights.
Stay ahead of the curve: Keep an eye on emerging trends and developments in transfer learning to ensure your organization can adapt and stay ahead.
Conclusion
In conclusion, the use and development of transfer learning offer promising prospects in solving small data problems and its applications in various fields. Embracing these future potentials by staying informed and proactive is advisable for any organization aiming to thrive in the data-driven future.
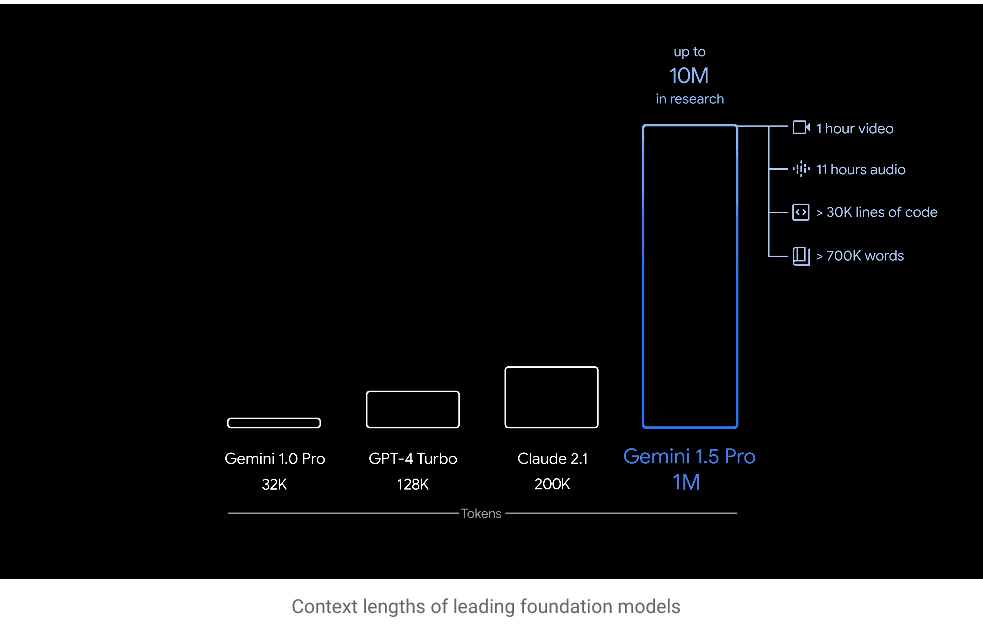
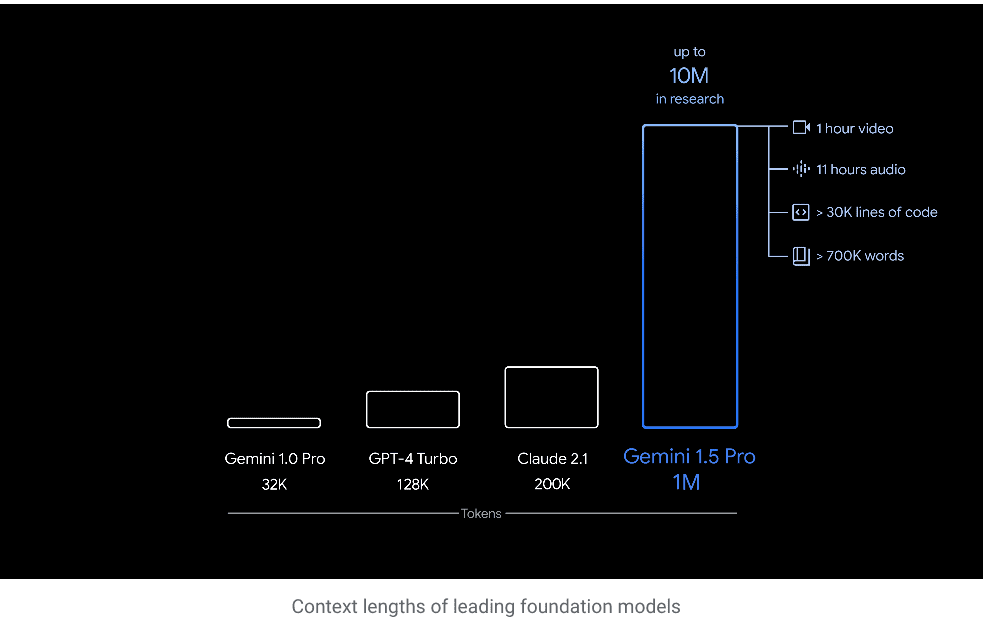
Image source https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/ Current LLM applications are mostly based on langchain or llamaindex. langChain and LlamaIndex are frameworks designed for LLM development. They each cater to different use cases with unique features. LangChain is a framework ideal for creating data-aware and agent-based applications. It offers high-level APIs for easy integration with various large language model (LLM)… Read More »Future of LLM application development – impact of Gemini 1.5 Pro with a 1M context window,
The Future of LLM Application Development
The digital landscape is always on the move, bringing with it new technologies and algorithms designed to revolutionize the way we work and interact. One advancement causing waves within artificial intelligence is the development of Large Language Models (LLM). Current LLM applications are predominantly based on two frameworks: langChain and LlamaIndex, both designed with unique features for separate use-cases. However, with the emergence of Google’s Gemini 1.5 Pro, the face of LLM application development may soon undergo a major transformation.
LangChain and LlamaIndex: Leaders in LLM Applications
LangChain and LlamaIndex have set themselves apart as the leading frameworks for LLM development. LangChain excels at creating data-aware and agent-based applications, providing high-level APIs for seamless integration with various LLMs. On the other hand, LlamaIndex caters to a different set of application development requirements. But despite their strengths, these two frameworks might soon have to contend with a fresh competitor: Google’s Gemini 1.5 Pro.
The Impact of Google’s Gemini 1.5 Pro
Google Gemini 1.5 Pro brings with it the promise of a significant impact on the future of LLM application development. This model stands out for its impressive 1M context window, an astounding leap from traditional models.
Long-Term Implications
The introduction of Google’s Gemini 1.5 Pro could potentially set new standards in LLM application development. With its enhanced capabilities, it may result in a shift in the current frameworks used, leading to an increased use of Gemini 1.5 Pro relative to langChain or LlamaIndex. This shift could stimulate changes in development practices, with a focus on harnessing the unique features that the Gemini model offers.
Possible Future Developments
This change could drive innovation in AI development, leading to new applications and use-cases being discovered. More efficient and sophisticated language-based applications could emerge, greatly enhancing user-experience and digital interactions. Further, this could also foster increased competition amongst AI development companies, potentially leading to more advanced LLM frameworks and models in the future.
Actionable Advice
Stay updated: With the AI landscape changing rapidly, it’s vital for developers and businesses to stay abreast with the latest frameworks and models. Regularly review new releases and updates in the field.
Invest in training: It’s crucial to invest in upskilling your teams to handle newer models like Gemini 1.5 Pro. This could involve online courses, industry seminars, or workshops.
Explore new use-cases: Leveraging the capabilities of advanced models such as Gemini 1.5 Pro can potentially open up new applications. Explore these possibilities actively to stay ahead of the competition.
In conclusion, while LangChain and LlamaIndex continue to serve as sturdy foundations for today’s LLM application development, the introduction of more advanced models such as Google’s Gemini 1.5 Pro is set to change the landscape. Businesses and developers must prepare for these developments and adapt to stay relevant in the increasingly competitive AI industry.
All files (xlsx with puzzle and R with solution) for each and every puzzle are available on my Github. Enjoy.
Puzzle #399
Today we have been given a list of random strings containing of certain number of letters duplicated. And our task is to count how many of each letters are there and present it as alphabetically pasted string. Sounds nice and it is nice. Let’s go.
Loading libraries and data
library(tidyverse)
library(readxl)
input = read_excel("Excel/399 Counter Dictionary.xlsx", range = "A1:A10")
test = read_excel("Excel/399 Counter Dictionary.xlsx", range = "B1:B10")
Once again we are playing with coordinates and checking if they form one structure. But this time vertices are mixed and we have some more to do. In this puzzle I will give you one surprise. Be patient.
Loading libraries and data
library(tidyverse)
library(readxl)
input = read_excel("Excel/400 Connected Points_v2.xlsx", range = "A1:D8")
test = read_excel("Excel/400 Connected Points_v2.xlsx", range = "E1:E8")
I asked AI chat to optimize my code from above, because I don’t really like when my code is to long without a purpose. So I tried it, and that is really a surprise.
I am not using matrices in my daily work often, but I really like puzzles in which I can use them to solve. Today we have to form triangle from string. We have to bend it to size of matrix. Let’s try.
Loading libraries and data
library(tidyverse)
library(readxl)
input1 = read_excel("Excel/401 Make Triangle.xlsx",
range = "A2:A2", col_names = F) %>% pull()
input2 = read_excel("Excel/401 Make Triangle.xlsx",
range = "A5:A5", col_names = F) %>% pull()
input3 = read_excel("Excel/401 Make Triangle.xlsx",
range = "A9:A9", col_names = F) %>% pull()
input4 = read_excel("Excel/401 Make Triangle.xlsx",
range = "A14:A14", col_names = F) %>% pull()
input5 = read_excel("Excel/401 Make Triangle.xlsx",
range = "A19:A19", col_names = F) %>% pull()
test1 = read_excel("Excel/401 Make Triangle.xlsx",
range = "C2:D3", col_names = F) %>% as.matrix(.)
dimnames(test1) = list(NULL, NULL)
test2 = read_excel("Excel/401 Make Triangle.xlsx",
range = "C5:D7",col_names = F) %>% as.matrix(.)
dimnames(test2) = list(NULL, NULL)
test3 = read_excel("Excel/401 Make Triangle.xlsx",
range = "C9:E12",col_names = F) %>% as.matrix(.)
dimnames(test3) = list(NULL, NULL)
test4 = read_excel("Excel/401 Make Triangle.xlsx",
range = "C14:F17", col_names = F) %>% as.matrix(.)
dimnames(test4) = list(NULL, NULL)
test5 = read_excel("Excel/401 Make Triangle.xlsx",
range = "C19:G23", col_names = F) %>% as.matrix(.)
dimnames(test5) = list(NULL, NULL)
One of common topics in our series is of course cyphering. And today we have again some spy level puzzle. We have some phrase and keyword using which we need to code given phrase. Few weeks ago there was puzzle when lacking letters in keyword were taken from coded phrase. Today we are repeating key how many times we need. And there is one more detail, we have to handle spaces as well. Not so simple, but satisfying.
Loading libraries and data
library(tidyverse)
library(readxl)
input = read_excel("Excel/402 Vignere Cipher.xlsx", range = "A1:B10")
test = read_excel("Excel/402 Vignere Cipher.xlsx", range = "C1:C10")
We are summarizing some values into year brackets. Usually you do it using crosstab. And our job today is to make crosstab that is not excel crosstab, but should work like it. From R side usually you have to make pivot, but I didn’t. So we have pivot table (another word for crosstab), without using pivot neither in R nor in Excel. How? Look on it.
Loading libraries and data
library(tidyverse)
library(readxl)
input = read_excel("Excel/403 Generate Pivot Table.xlsx", range = "A1:B100")
test = read_excel("Excel/403 Generate Pivot Table.xlsx", range = "D2:F9")
Transformation
result = input %>%
add_row(Year = 2024, Value = 0) %>% ## just to have proper year range at the end
mutate(group = cut(Year, breaks = seq(1989, 2024, 5), labels = FALSE, include.lowest = TRUE)) %>%
group_by(group) %>%
summarize(Year = paste0(min(Year), "-", max(Year)),
`Sum of Value` = sum(Value)) %>%
ungroup() %>%
mutate(`% of Value` = `Sum of Value`/sum(`Sum of Value`)) %>%
select(-group)
Validation
identical(result, test)
# [1] TRUE
Feel free to comment, share and contact me with advices, questions and your ideas how to improve anything. Contact me on Linkedin if you wish as well.
In this text, the author challenges the reader with multiple puzzles. These puzzles are a testament to the flexibility and efficiency of the R programming language, which is used to solve each problem. The incorporation of the tidyverse and readxl libraries into the solutions further showcase the power of R. The problems touch on data processing in different forms: string manipulation, coordinate transformation, matrix generation, cipher creation, and pivot table creation.
Long-term Implications
The author demonstrates how R can be leveraged for data manipulation of various types, which provides insights into its potential uses for other data-related applications in the future. This includes data analysis, visualisation, machine learning, and modeling, with the possibility of extending R’s capabilities with libraries like tidyverse and readxl. This implies that learning and utilising R can be essential for analysts, data scientists and even business officials who engage with data regularly.
Possible Future Developments
The R programming language will likely continue to evolve, with more powerful and efficient libraries being developed. These will likely improve the language’s data pre-processing functionalities further, making it an even more potent analytic instrument. As more individuals becomes aware and learn R, a possible future development could be the provision of simpler interface for R that allows even non-programmers to execute complex data manipulations.
Actionable Advice
If you work with data in any capacity, consider learning and using R for your data processing needs. This language, with its numerous libraries such as tidyverse and readxl, not only provides extensive functionality for manipulating, summarising and analysing data, but also offers a deep capability to handle and solve complex data-oriented problems. Despite R having a somewhat steep learning curve initially, especially for those without programming background, the potential long-term benefits of being able to hand-craft solutions to problems make it an investment worth making.
More Exercises and Practice
Consider trying R on more complex problems such as those presented in the text. The more practice you get using the language, the more comfortable you will become in writing efficient R code. Further, consider developing the habit of constantly looking for problems to solve using R so as to enhance your problem-solving skills while also mastering the language.
Looking to learn SQL and databases to level up your data science skills? Learn SQL, database internals, and much more with these free university courses.
The Importance of SQL and Database Knowledge in Data Science
As the article suggests, SQL and database knowledge is becoming increasingly crucial in the data science field. This kind of knowledge equips data scientists with the necessary skills to handle and manage larger datasets with ease, thereby improving efficiency and accuracy in their work. Many data scientists agree that mastering SQL and understanding database internals are essential, hence the growing trend of free university courses offering the same.
Potential Long-Term Implications
It’s predicted that the importance of SQL and databases in the field of data science will only grow over time. This might result in more educational institutions offering more in-depth and specialized courses, thereby setting a new educational standard for data science. Furthermore, this trend can potentially widen the skill gap between seasoned data scientists and budding data practitioners, increasing the importance of continuous learning and skill enhancement.
Future Developments
The field of data science is evolving rapidly and it is likely that SQL and databases will continue to be a substantial part of this evolution. SQL is already a reliable and robust language for managing databases, but enhancements and advancements may make it even more useful for data handling. Databases, in turn, will likely become even more sophisticated, capable of handling larger and more complex datasets.
Actionable insights
If you’re a data scientist or aspire to be one, prioritizing SQL and databases in your skill portfolio is advisable. Here are some useful tips:
Take advantage of free university courses: Utilize the resources mentioned in the article to not only learn SQL and databases but also explore more advanced subjects. Continuous learning is key to staying up-to-date and relevant in the field.
Practice SQL and Database Management: Just like with any other programming language, the key to mastery is through constant practice. Utilize sample databases to experiment with SQL commands and queries.
Stay Informed: Keep up with the latest developments in SQL and database technologies to ensure your skills are always relevant and up-to-date.
Conclusion
While future advancements will undoubtedly bring new tools and technologies to the world of data science, the role of SQL and databases is likely to remain critical. Data scientists who are adept in handling databases and skilled in SQL are expected to be in high demand. Thus, capitalizing on free learning resources like university courses is a wise move.
Unlock the power of GenAI in MarTech. Explore its impact on content creation, customer engagement, and ROI. Stay ahead in 2023-24 with leading tools and strategies
The Power of GenAI in MarTech: Impact and Future Developments
With the blend of marketing and technology, coined as MarTech, becoming a vital part of business strategies, it’s essential to consider how emerging technologies such as Generic Artificial Intelligence (GenAI) can be leveraged to maximize the impact on content creation, customer engagement, and return on investment (ROI).
Long-term Implications and Future Developments of GenAI in MarTech
The introduction of GenAI in MarTech provides an innovative platform for businesses to elevate their marketing strategies, allowing for cost-effective, highly adaptable, and robust solutions that drive customer engagement and boost ROI.
Unlock the power of GenAI in MarTech. Explore its impact on content creation, customer engagement, and ROI. Stay ahead in 2023-24 with leading tools and strategies
Content Creation
GenAI has the potential to transform the way content is created. With GenAI in charge of content production, businesses can ensure a higher level of personalization, optimal content structuring, and improved SEO strategies leading to enhance audience engagement. AI-generated content removes the risk of human error and delivers a high-quality, personalized experience for customers.
Customer Engagement
Through GenAI, companies can automate many aspects of customer engagement, making it seamless and more personalized. It can also collect and analyze customer data to inform decision-making and tailor their marketing strategies accordingly. This ultimately provides a personalized customer journey, leading to increased engagement and customer loyalty.
Return on Investment (ROI)
With intelligent automation and advanced data analytics, ROI improvement becomes a tangible reality of employing GenAI in MarTech. Decision-makers can track and predict customer behaviors, which enables precise marketing planning and thus leads to a greater return on investment.
Actionable Advice for Leveraging GenAI in MarTech
Stay Current: Keep up-to-date with the latest GenAI-enabled tools and strategies to keep your business ahead of the curve in the increasingly competitive market landscape.
Invest in Training: GenAI tools are only as effective as the staff using them. Investing in team training for the effective use of AI-based systems can make a significant difference in results.
Quality over Quantity: Just because AI can create a bulk of content, doesn’t mean it should. Maintain a focus on creating high-quality content suited to your target audience needs.
Data Security: As GenAI collects and analyzes vast amounts of customer data, businesses must ensure data security and privacy are maintained. Staying compliant with regulations preserves consumer trust.
In conclusion, GenAI holds a lot of potentials to revolutionize traditional MarTech. By truly understanding its capabilities and future developments, businesses can remain one step ahead and drive their marketing initiatives towards unprecedented success in 2023-24 and beyond.
[This article was first published on Mark H. White II, PhD, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
The Academy Awards are a week away, and I’m sharing my
machine-learning-based predictions for Best Picture as well as some
insights I took away from the process (particularly XGBoost’s
sparsity-aware split finding). Oppenheimer is a heavy favorite
at 97% likely to win—but major surprises are not uncommon, as we’ll
see.
I pulled data from three sources. First, industry awards. Most unions
and guilds for filmmakers—producers, directors, actors,
cinematographers, editors, production designers—have their own awards.
Second, critical awards. I collected as wide as possible, from the
Golden Globes to the Georgia Film Critics Association. More or less: If
an organization had a Wikipedia page showing a historical list of
nominees and/or winners, I scraped it. Third, miscellaneous information
like Metacritic score and keywords taken from synopses to learn if it
was adapted from a book, what genre it is, the topics it covers, and so
on. Combining all of these was a pain, especially for films that have
bonkers names like BİRDMAN or (The Unexpected Virtue of
Ignorance).
The source data generally aligns with what
FiveThirtyEight used to do, except I casted a far wider net in
collecting awards. Other differences include FiveThirtyEight choosing a
closed-form solution for weighting the importance of awards and then
rating films in terms of “points” they accrued (out of the potential
pool of points) throughout the season. I chose to build a machine
learning model, which was tricky.
To make the merging of data feasible (e.g., different tables had
different spellings of the film or different years associated with the
film), I only looked at the movies who received a nomination for Best
Picture, making for a tiny dataset of 591 rows for the first 95
ceremonies. The wildly small N presents a challenge for building a
machine learning model, as does sparsity and missing data.
Sparsity and Missing Data
There are a ton of zeroes in the data, creating sparsity. Every
variable (save for the Metacritic score) is binary. Nomination variables
(i.e., was the film nominated for the award?) may have multiple films
for a given year with a 1, but winning variables (i.e., did the film win
the award?) only have a single 1 each year.
There is also the challenge of missing data. Not every award in the
model goes back to the late 1920s, meaning that each film has an NA if it was released in a year before a given award. For
example, I only included Metacritic scores for contemporaneous releases,
and the site launched in 2001, while the Screen Actors Guild started
their awards in 1995.
My first thought was an ensemble model. Segment each group of awards,
based on their start date, into different models. Get predicted
probabilities from these, and combine them weighted on the inverse of
out-of-sample error. After experimenting a bit, I came to the conclusion
so many of us do when building models: Use XGBoost. With so little data
to use for tuning, I simply stuck with model defaults for
hyper-parameters.
Outside of its reputation for being accurate out of the box, it
handles missing data. The docs simply
state: “XGBoost supports missing values by default. In tree algorithms,
branch directions for missing values are learned during training.” This
is discussed in deeper detail in the “sparsity-aware split finding”
section of the paper
introducing XGBoost. The full algorithm is shown in that paper, but the
general idea is that an optimal default direction at each split in a
tree is learned from the data, and missing values follow that
default.
Backtesting
To assess performance, I backtested on the last thirty years of
Academy Awards. I believe scikit-learn would call this group
k-fold cross-validation. I removed a given year from the dataset,
fit the model, and then made predictions on the held-out year. The last
hiccup is that the model does not know that if Movie A from Year X wins
Best Picture, it means Movies B – E from Year X cannot. It also does not
know that one of the films from Year X must win. My cheat
around this is I re-scale all the predicted probabilities to sum to
one.
The predictions for the last thirty years:
Year
Predicted Winner
Modeled Win Probability
Won Best Picture?
Actual Winner
1993
schindler’s list
0.996
1
schindler’s list
1994
forrest gump
0.990
1
forrest gump
1995
apollo 13
0.987
0
braveheart
1996
the english patient
0.923
1
the english patient
1997
titanic
0.980
1
titanic
1998
saving private ryan
0.938
0
shakespeare in love
1999
american beauty
0.995
1
american beauty
2000
gladiator
0.586
1
gladiator
2001
a beautiful mind
0.554
1
a beautiful mind
2002
chicago
0.963
1
chicago
2003
the lord of the rings: the return of the king
0.986
1
the lord of the rings: the return of the king
2004
the aviator
0.713
0
million dollar baby
2005
brokeback mountain
0.681
0
crash
2006
the departed
0.680
1
the departed
2007
no country for old men
0.997
1
no country for old men
2008
slumdog millionaire
0.886
1
slumdog millionaire
2009
the hurt locker
0.988
1
the hurt locker
2010
the king’s speech
0.730
1
the king’s speech
2011
the artist
0.909
1
the artist
2012
argo
0.984
1
argo
2013
12 years a slave
0.551
1
12 years a slave
2014
birdman
0.929
1
birdman
2015
spotlight
0.502
1
spotlight
2016
la la land
0.984
0
moonlight
2017
the shape of water
0.783
1
the shape of water
2018
roma
0.928
0
green book
2019
parasite
0.576
1
parasite
2020
nomadland
0.878
1
nomadland
2021
the power of the dog
0.981
0
coda
2022
everything everywhere all at once
0.959
1
everything everywhere all at once
Of the last 30 years, 23 predicted winners actually won, while 7
lost—making for an accuracy of about 77%. Not terrible. (And,
paradoxically, many of the misses are predictable ones to those familiar
with Best Picture history.) However, the mean predicted probability of
winning from these 30 cases is about 85%, which means the model is maybe
8 points over-confident. We do see recent years being more prone to
upsets—is that due to a larger pool of nominees? Or something else, like
a change in the Academy’s makeup or voting procedures? At any rate, some
ideas I am going to play with before next year are weighting more
proximate years higher (as rules, voting body, voting trends, etc.,
change over time), finding additional awards, and pulling in other
metadata on films. It might just be, though, that the Academy likes to
swerve away from everyone else sometimes in a way that is not readily
predictable from outside data sources. (Hence the fun of watching and
speculating and modeling in the first place.)
This Year
I wanted to include a chart showing probabilities over time, but the
story has largely remained the same. The major inflection point was the
Directors Guild of America (DGA) Awards.
Of the data we had on the day the nominees were
announced (January 23rd), the predictions were:
Film
Predicted Probability
Killers of the Flower Moon
0.549
The Zone of Interest
0.160
Oppenheimer
0.147
American Fiction
0.061
Barbie
0.039
Poor Things
0.023
The Holdovers
0.012
Past Lives
0.005
Anatomy of a Fall
0.005
Maestro
0.001
I was shocked to see Oppenheimer lagging in third and to see The Zone of Interest so high. The reason here is that, while
backtesting, I saw that the variable importance for winning the DGA
award for Outstanding Directing – Feature Film was the highest by about
a factor of ten. Since XGBoost handles missing values nicely, we can
rely on the sparsity-aware split testing to get a little more
information from these data. If we know the nominees of an award but not
the winner yet, we can still infer: Anyone who was nominated is left NA, while anyone who was not nominated is set to zero. That
allows us to partially use this DGA variable (and the other awards where
we knew the nominees on January 23rd, but not the winners). When we do
that, the predicted probabilities as of the announcing of the
Best Picture nominees were:
Film
Predicted Probability
Killers of the Flower Moon
0.380
Poor Things
0.313
Oppenheimer
0.160
The Zone of Interest
0.116
American Fiction
0.012
Barbie
0.007
Past Lives
0.007
Maestro
0.003
Anatomy of a Fall
0.002
The Holdovers
0.001
The Zone of Interest falls in favor of Poor Things,
since the former was not nominated for the DGA award while the latter
was. I was still puzzled, but I knew that the model wouldn’t start being
certain until we knew the DGA award. Those top three films were
nominated for many of the same awards. Then Christopher Nolan won the
DGA award for Oppenheimer, and the film hasn’t been below a 95%
chance for winning Best Picture since.
Final Predictions
The probabilities as they stand today, a week before the ceremony,
have Oppenheimer as the presumptive winner at a 97% chance of
winning.
Film
Predicted Probability
Oppenheimer
0.973
Poor Things
0.010
Killers of the Flower Moon
0.005
The Zone of Interest
0.004
Anatomy of a Fall
0.003
American Fiction
0.002
Past Lives
0.001
Barbie
0.001
The Holdovers
0.001
Maestro
0.000
There are a few awards being announced tonight (Satellite Awards, the
awards for the cinematographers guild and the edtiors guild), but they
should not impact the model much. So, we are in for a year of a
predictable winner—or another shocking year where a CODA or a Moonlight takes home film’s biggest award. (If you’ve read this
far and enjoyed Cillian Murphy in Oppenheimer… go check out his
leading performance in Sunshine,
directed by Danny Boyle and written by Alex Garland.)
To leave a comment for the author, please follow the link and comment on their blog: Mark H. White II, PhD.
The original article offered data on the use of machine learning to predict the winners of the Academy Awards. This approach used numerous datasets related to previous awards, critical accolades, and additional factors such as genre or adaptation. This data was then fed into machine learning algorithms, notably the XGBoost Model, which can deal with missing values and data sparsity, common issues that occur when compiling studies this vast and arduous.
Implications
The ability to predict Oscar outcomes accurately, even with an accuracy rate of about 77%, is both intriguing and revealing. Additionally, the algorithm was observed to be slightly overconfident, indicating a potential area for future work. On the other hand, the consistent accuracy might also signify that the model was able to capture some outright patterns or rules that determine Oscar wins, possibly shedding light on tendencies or biases inherent in the Academy’s decision-making process.
Possible Future Developments
Technology and artificial intelligence are gradually ingraining themselves into the film industry, and this predictive algorithm is a clear example of their potential usage. The model could theoretically be extended to predict other outcomes, perhaps even aiding film production companies in designing films to maximize their Oscar potentials. Though this would require the accuracy to be substantially improved and the existence of consistent, predictable patterns in Oscar decision-making.
Actionable Advice
Model Improvement
The first area where action can be taken is model improvement. As mentioned in the original article, there are changes in the rules, voting body, and voting trends over time – weighting more proximate years higher might be a feasible improvement to the model. It may also be worthwhile to consider if any other variables might impact the Academy’s voting behavior and try incorporating them into the current model.
Field Usage
The model could be of interest to film production companies, news agencies, or even betting companies – all of which would profit from accurate predictions about the Oscars. This could create market demand, leading to commercialization opportunities for such a model.
Studying Voting Decisions
If the model continues to predict Oscar outcomes correctly, it might indicate that there are consistent rules behind the voting decisions. Further exploration might reveal tendencies or biases in the Academy’s voting, which would pose interesting questions about the fairness and independence of the voting process.
In Conclusion
Although this a promising and exciting predictive model, its accuracy and subsequent analysis must be taken with a grain of salt, as this model isn’t perfect. Regardless, this use of machine learning is a fascinating peek into possible applications of AI and data science within the film industry. Keep an eye on future developments in this area – it’s definitely a space worth watching.