by jsendak | Mar 17, 2024 | DS Articles

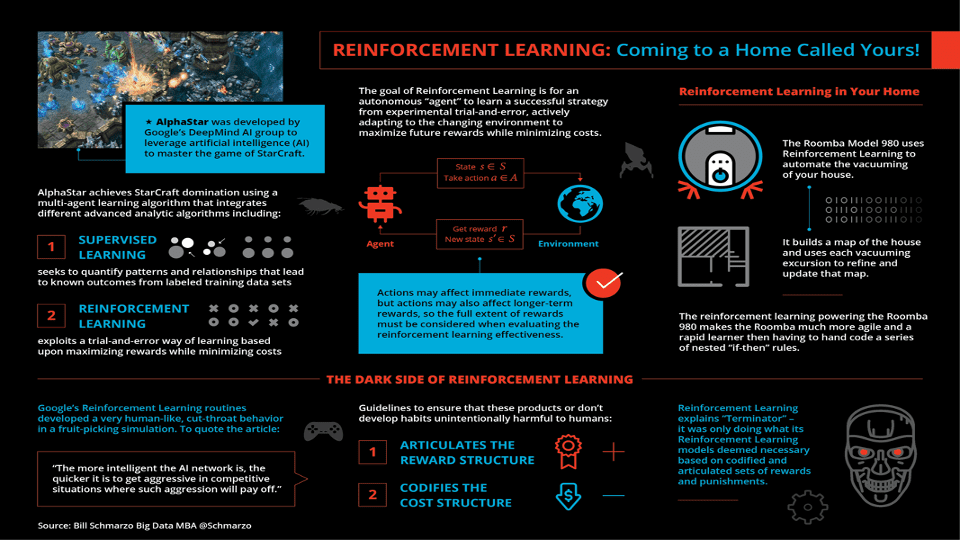
Sometimes, something happens right before your eyes, but it takes time (months, years?) to realize its significance. In February 2019, I wrote a blog titled “Reinforcement Learning: Coming to a Home Called Yours!” that discussed Google DeepMind’s phenomenal accomplishment in creating AlphaStar. I was a big fan of StarCraft II, a science fiction strategy game… Read More »Creating AlphaStar: The Start of the AI Revolution?
Analysis of the Emergence of the AI Revolution
The field of Artificial Intelligence is evolving at an unprecedented pace, with highly advanced systems such as Google DeepMind’s AlphaStar beginning to emerge. The creation of AlphaStar has demonstrated the groundbreaking potential of Reinforcement Learning, casting light on the future possibilities for AI. This development is noteworthy as it could potentially signify the start of an AI revolution.
AlphaStar: A Game Changer
AlphaStar, a product of Google DeepMind, is capable of achieving a high level of performance in playing StarCraft II, a complex science fiction strategy game. The remarkable accomplishment of AlphaStar lies in its use of Reinforcement Learning which allows it to learn and adapt in-depth strategies and tactical maneuvers within the game. The fact that an AI can excel in a domain of human expertise opens the door to multiple future opportunities.
Implications and Future Developments
Artificial Intelligence in Everyday Life
AlphaStar’s capabilities demonstrate that machines can learn from experience using reinforcement learning. This holds potential implications for embedding AI into everyday household tasks, revolutionizing the way we live and work. While we may be months, or even years, away from realizing this immense potential, the precedent set by AlphaStar indicates a clear trajectory towards an AI-centric future.
VR and Gaming Industry Transformation
Given AlphaStar’s proficiency in a strategy-based game, it could be projected that the future of the gaming industry will be significantly influenced by AI. This could lead to more immersive, dynamic, and intelligent virtual worlds in gaming. AI-controlled characters may become virtually indistinguishable from human players, bringing a new level of complexity and challenge.
Actionable Recommendations
The creation of AlphaStar is not just a game-changer for the AI industry, but it could potentially redefine various sectors:
- Household Technology Companies should start exploring the potential of integrating advanced AI, akin to AlphaStar, into their products.
- Game Developers/ Companies should start collaborating with AI researchers to harness the benefits of advanced AI for more sophisticated gaming experiences.
- AI Researchers should leverage the success of AlphaStar to further explore the potential application areas for reinforcement learning.
In conclusion, the potential of the AI-enabled revolution should be respected and capitalized on. The success of AlphaStar is a key milestone in AI development and might very well be the start of a revolution we are yet to fully understand.
Read the original article
by jsendak | Mar 16, 2024 | DS Articles
[This article was first published on
R-posts.com, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
After some years as a Stata user, I found myself in a new position where the tools available were SQL and SPSS. I was impressed by the power of SQL, but I was unhappy with going back to SPSS after five years with Stata.
Luckily, I got the go-ahead from my leaders at the department to start testing out R as a tool to supplement SQL in data handling.
This was in the beginning of 2020, and by March we were having a social gathering at our workplace. A Bingo night! Which turned out to be the last social event before the pandemic lockdown.
What better opportunity to learn a new programming language than to program some bingo cards! I learnt a lot from this little project.
It uses the packages grid and gridExtra to prepare and embellish the cards.
The function BingoCard draws the cards and is called from the function Bingo3. When Bingo3 is called it runs BingoCard the number of times necessary to create the requested number of sheets and stores the result as a pdf inside a folder defined at the beginning of the script.
All steps could have been added together in a single function. For instance, a more complete function could have included input for the color scheme of the cards, the number of cards on each sheet and more advanced features for where to store the results.
Still, this worked quite well, and was an excellent way of learning since it was both so much fun and gave me the opportunity to talk enthusiastically about R during Bingo Night.
library(gridExtra)
library(grid)
##################################################################
# Be sure to have a folder where results are stored
##################################################################
CardFolder <- "BingoCards"
if (!dir.exists(CardFolder)) {dir.create(CardFolder)}
##################################################################
# Create a theme to use for the cards
##################################################################
thema <- ttheme_minimal(
base_size = 24, padding = unit(c(6, 6), "mm"),
core=list(bg_params = list(fill = rainbow(5),
alpha = 0.5,
col="black"),
fg_params=list(fontface="plain",col="darkblue")),
colhead=list(fg_params=list(col="darkblue")),
rowhead=list(fg_params=list(col="white")))
##################################################################
## Define the function BingoCard
##################################################################
BingoCard <- function() {
B <- sample(1:15, 5, replace=FALSE)
I <- sample(16:30, 5, replace=FALSE)
N <- sample(31:45, 5, replace=FALSE)
G <- sample(46:60, 5, replace=FALSE)
O <- sample(61:75, 5, replace=FALSE)
BingoCard <- as.data.frame(cbind(B,I,N,G,O))
BingoCard[3,"N"]<-"X"
a <- tableGrob(BingoCard, theme = thema)
return(a)
}
##################################################################
## Define the function Bingo3
## The function has two arguments
## By default, 1 sheet with 3 cards is stored in the CardFolder
## The default name is "bingocards.pdf"
## This function calls the BingoCard function
##################################################################
Bingo3 <- function(NumberOfSheets=1, SaveFileName="bingocards") {
myplots <- list()
N <- NumberOfSheets*3
for (i in 1 : N ) {
a1 <- BingoCard()
myplots[[i]] <- a1
}
ml <- marrangeGrob(myplots, nrow=3, ncol=1,top="")
save_here <- paste0(CardFolder,"/",SaveFileName,".pdf")
ggplot2::ggsave(save_here, ml, device = "pdf", width = 210,
height = 297, units = "mm")
}
##################################################################
## Run Bingo3 with default values
##################################################################
Bingo3()
##################################################################
## Run Bingo3 with custom values
##################################################################
Bingo3(NumberOfSheets = 30, SaveFileName = "30_BingoCards")
The Fun in Functional Programming was first posted on March 15, 2024 at 3:26 pm.
Continue reading: The Fun in Functional Programming
Adaptability and Proactiveness in the Dynamic Realm of Programming Languages
In a digital age, we consistently see the rise and fall of programming languages and tools, compelling many developers to continually expand their skill sets. Often, they get introduced to new tools due to the requirements of their roles or out of curiosity on their part. With constant movement and growth in technical roles, developers are encouraged to stay dynamically inclined towards learning new languages.
In the shared user perspective, the shift was made from Stata to the use of SQL and SPSS. They found SQL’s power quite impressive but were trudging towards SPSS’s adoption due to past experiences. Fortunately, the opportunity arose to explore R, an option that appeared quite appealing.
Capitalizing on R: A Highly Effective Programming Tool
R programming language became an essential tool in the user’s quest for better data handling in conjunction with SQL. With its introduction around 2020, it paved the way to an enjoyable journey of learning, starting with the programming of bingo cards.
Implementing R in Project Scenarios
Technically, the R-language exercised in the bingo project involved packages like ‘grid’ and ‘gridExtra’ for card preparation and enhancement. Functions like “BingoCard”, which was used to draw the cards, and “Bingo3”, which called on “BingoCard” to create the required number of bingo sheets. The product of these functions was stored as a PDF in a predefined folder in the script.
Interestingly, all steps could be incorporated in one single function, enabling further customization, such as altering the cards’ color scheme, controlling the number of cards per sheet, and advanced features for storing the results. The two functions described were enough for the task at hand and served as an excellent starting point for the user to explore R.
Implications and Future Developments
This account of a journey into R programming signifies the flexibility and adaptability programmers require in a constantly developing tech ecosystem. It also highlights how learning new tools and languages can be made interesting and engaging through hands-on projects.
- On-Demand Learning: As the tech world evolves, the demand for learning new languages will increase. This makes it necessary for professionals to be proactive in picking up new skills.
- Complex Problem Solving: Even though R was initially used for a straightforward application like creating Bingo cards, it can be repurposed for more complex applications like data modeling, statistical computing, and graphic representation of data.
- Future Developments: With the R programming language’s capabilities, future developments could include more comprehensive functions and a broader array of applications beyond data handling and card creation.
This suggests that while developers should be ready to take on new tools and languages as they evolve, they might find themselves adopting languages like R in the long run due to its flexibility and versatility. They should consider investing time and resources in learning R to tackle complex data-related tasks in their professional roles.
Actionable Advice
Professionals in technical roles, particularly those dealing with data, should be open to exploring new tools such as R, while developers should consider standalone projects or activities to understand a new language better. Future tasks could include more complex problems to maximize the language’s capabilities and grow as a well-skilled and adaptable developer in this dynamic digital ecosystem.
Read the original article
by jsendak | Mar 16, 2024 | DS Articles
Data science is not the only career path you could take, even if you have already learned to be one.
Future Career Paths and Long-term Implications of Data Science Skills
The proficiency in data science opens the doors to a wide range of career opportunities beyond just a data scientist role. This post delves into the future implications and the potential career paths for those who possess data science skills.
Long-term Implications
The realm of data science has progressively become more versatile, with many sectors understanding the value of data analysis. As a result, the skills acquired in data science can be employed across various industries, engendering a multitude of long-term implications.
- Growth in Demand – The need for individuals with data science skills is rising across many sectors from tech firms to NGOs, making these skills valuable.
- Job Security – With the constant generation of data, it’s safe to suggest that data specialists will always be in demand, making this field quite secure for the future.
- High Earning Potential – Given the expertise needed and demand for data science skills, roles in data science are often associated with high salaries.
Future Career Opportunities
Armed with data science skills, several exciting career paths come to the forefront. A few include:
- Data Analyst: This job focuses on interpreting data and turning it into information which can offer ways to improve a business, thereby affecting business decisions.
- Machine Learning Engineer: These individuals create data funnels and deliver software solutions. They have a strong understanding of programming and statistical modeling.
- Data Science Consultant: These experienced professionals advise companies on data-related strategies and transformations.
Actionable Advice
“To stay ahead in the data science field, continue learning. This industry never stops evolving, neither should your skill set. ”
If you have learned to be a data scientist, keep building on your knowledge, and adapt to the dynamic nature of the field. A data scientist has a wide variety of career path options, but to achieve any of these roles, you should keep honing and updating your skills regularly, stay informed about the latest technological developments, and cultivate your analytical thinking.
To summarize, learning data science is a huge asset in today’s data-driven world and provides a plethora of career opportunities. However, this is an ever-evolving field necessitating constant learning and adaptation to stay on top of your game.
Read the original article
by jsendak | Mar 16, 2024 | DS Articles
Explore the significance of Retrieval-Augmented Generation (RAG) in the realm of Generative AI. Unravel the technical intricacies of RAG techniques, including RetrievalQA, MultiqueryRetriever, Vector Store-backed retriever, Hybrid Search using BM25Retriever, and Contextual Compression. Learn how RAG synergizes the strengths of retrieval-based and generative models to elevate the precision and relevance of generated text.
Analyzing the Impact and Future of Retrieval-Augmented Generation in Generative AI
In the dynamic world of artificial intelligence (AI), Retrieval-Augmented Generation (RAG) has emerged as a promising, novel framework that holds the potential to transform Generative AI’s capabilities. RAG leverages the power of both retrieval-based and generative models, effectively combining their strengths to generate highly precise and relevant text. The key techniques underpinning RAG’s success include, but not limited to, RetrievalQA, MultiqueryRetriever, Vector Store-backed retriever, Hybrid Search using BM25Retriever, and Contextual Compression.
Long-term Implications and Future Developments of RAG
Observing the significant strides RAG has already made in the Generative AI landscape, it’s clear that it’s likely to hold numerous long-term implications. RAG might play a major part in multiple fields like automated customer assistance, creative writing assistance, and content curation, among others. It is worth exploring these potential ramifications and possible future developments linked with this AI technique.
RAG’s Role in Revolutionizing Customer Assistance
One of the most significant implications of RAG is how it could potentially augment automated customer service systems. Given its ability to generate precise and relevant text, RAG may allow AI chatbots to respond more coherently and contextually to customer queries, thus enhancing customer experience and creating more interactive automated assistant platforms.
Impact on Content Creation and Curation
RAG’s strengths could also be leveraged in the realm of creative writing assistance and content curation. This technique, with its ability to generate high-quality, relevant content, can be used in AI-powered content generation tools, making it easier for creators to generate and curate engaging and value-added content.
Future Developments in RAG
The potential scope for future developments in RAG is vast and exciting. Enhancements in the constituent techniques of RAG like RetrievalQA, MultiqueryRetriever and others could lead to further advances. For instance, more accurate Vector Store-backed retrievers might improve the quality of search results while Improvements in Contextual Compression might enhance the overall text generation process.
Actionable Advice Based on These Insights
- Companies that rely on AI to drive their customer-facing operations should monitor developments in RAG closely, with a view to incorporate latest advancements to enhance customer service.
- Content creators and creative professionals can consider leveraging AI tools powered by RAG to streamline their content generation and curation process.
- Stakeholders invested in AI development should prioritize refining and enhancing the underlying techniques of RAG for achieving higher precision and relevant text generation.
Retrieval-Augmented Generation, as the name suggests, stands poised to redefine the landscape of Generative AI. Staying alert to its potential and working persistently to maximize its capabilities will yield game-changing results for many applications.
Read the original article
by jsendak | Mar 15, 2024 | DS Articles
[This article was first published on
Saturn Elephant, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
I will soon release an update of qspray on CRAN as well
as a new package: resultant. This post shows an
application of these two packages.
Consider the two algebraic curves
(f(x,y)=0) and
(g(x,y)=0) where
[ f(x, y) = y^4 – y^3 + y^2 – 2x^2y + x^4 quad text{ and } quad
g(x, y) = y – 2x^2. ]
We will derive their intersection points. First of all, let’s plot them.
f <- function(x, y) {
y^4 - y^3 + y^2 - 2*x^2*y + x^4
}
g <- function(x, y) {
y - 2*x^2
}
# contour line for f(x,y)=0
x <- seq(-1.2, 1.2, len = 2000)
y <- seq(0, 1, len = 2000)
z <- outer(x, y, f)
crf <- contourLines(x, y, z, levels = 0)
# contour line for g(x,y)=0
x <- seq(-1, 1, len = 2000)
y <- seq(0, 1.5, len = 2000)
z <- outer(x, y, g)
crg <- contourLines(x, y, z, levels = 0)
Theoretically there is only one contour line for both. But for some
technical reasons, crf is split into several pieces:
So we need a helper function to construct the dataframe that we will
pass to ggplot2::geom_path:
intercalateNA <- function(xs) {
if(length(xs) == 1L) {
xs[[1L]]
} else {
c(xs[[1L]], NA, intercalateNA(xs[-1L]))
}
}
contourData <- function(cr) {
xs <- lapply(cr, `[[`, "x")
ys <- lapply(cr, `[[`, "y")
data.frame("x" = intercalateNA(xs), "y" = intercalateNA(ys))
}
datf <- contourData(crf)
datg <- contourData(crg)
I also plot the intersection points that we will derive later:
datPoints <- data.frame("x" = c(-0.5, 0, 0.5), "y" = c(0.5, 0, 0.5))
library(ggplot2)
ggplot() +
geom_path(aes(x, y), data = datf, linewidth = 1, color = "blue") +
geom_path(aes(x, y), data = datg, linewidth = 1, color = "green") +
geom_point(aes(x, y), data = datPoints, size = 2)
Now we compute the resultant of the two polynomials with
respect to (x):
# define the two polynomials
library(qspray)
x <- qlone(1)
y <- qlone(2)
P <- f(x, y)
Q <- g(x, y)
# compute their resultant with respect to x
Rx <- resultant::resultant(P, Q, var = 1) # var=1 <=> var="x"
prettyQspray(Rx, vars = "x")
## [1] "16*x^8 - 32*x^7 + 24*x^6 - 8*x^5 + x^4"
We need the roots of the resultant
(R_x). I use
giacR to get them:
library(giacR)
giac <- Giac$new()
command <- sprintf("roots(%s)", prettyQspray(Rx, vars = "x"))
giac$execute(command)
## [1] "[[0,4],[1/2,4]]"
giac$close()
## NULL
Thus there are two roots: (0) and
(1/2) (the output of
GIAC also provides their multiplicities). Luckily, they
are rational, so we can use substituteQspray to replace
(y) with each of these roots in
(P) and
(Q). We firstly do the substitution
(y=0):
Px <- substituteQspray(P, c(NA, "0"))
Qx <- substituteQspray(Q, c(NA, "0"))
prettyQspray(Px, "x")
## [1] "x^4"
prettyQspray(Qx, "x")
## [1] "(-2)*x^2"
Clearly, (0) is the unique common
root of these two polynomials. One can conclude that
((0,0)) is an intersection point.
Now we do the substitution (y=1/2):
Px <- substituteQspray(P, c(NA, "1/2"))
Qx <- substituteQspray(Q, c(NA, "1/2"))
prettyQspray(Px, "x")
## [1] "x^4 - x^2 + 3/16"
prettyQspray(Qx, "x")
## [1] "1/2 - 2*x^2"
It is easy to see that
(x= pm 1/2) are the roots of the
second polynomial. And one can check that they are also some roots of
the first one. One can conclude that
((-1/2, 1/2)) and
((1/2, 1/2)) are some intersection
points.
And we’re done.
Continue reading: An application of the resultant
Long-Term Implications and Future Developments
The author has announced updates for the qspray package and introduced a new package named resultant, both for the R programming language. This update and new package will provide a beneficial tool for the R community, streamlining the process of finding intersection points between two distinct algebraic curves. This functionality will, in the long term, simplify and speed up various mathematical and coding tasks.
As a future development, this technology could expand to more complex equations or higher-dimensional forms. Further development of code and packages specialised in algebraic computations is also an area to anticipate.
Actionable Advice
For developers and users who frequently work with mathematical computations and R language for data analysis or modelling tasks, getting familiar with these packages could improve efficiency and productivity. Both ‘qspray’ and ‘resultant’ packages can streamline the procedure of finding intersection points, which are often used in solving complex mathematical equations or optimization problems.
Learning how to use qspray and resultant
- Using qspray and resultant packages as demonstrated in the article could become a regular part of your R programming toolkit. Take the time to understand the example given, and apply it to your scenarios.
- Continuously monitor the updates and improvements of these two packages. The developers often introduce significant enhancements in new releases.
- Reach out to the developer community if you have questions or need advice. The R programming community is typically very supportive and can provide valuable guidance.
Long-term strategy for leveraging resultant and qspray
- Consider training sessions or workshops to help your team gain a deep understanding and hands-on experience with these packages. This will improve overall team productivity and efficiency when working with R.
- Keep an eye on similar packages or developments. The field of R packages for mathematical computations is fast evolving, and continual learning is required to keep up to date.
In conclusion, these packages are set to make a meaningful contribution to the R programming environment. Individuals and teams who leverage these packages early could see significant long-term benefits in terms of efficiency and productivity.
Read the original article
by jsendak | Mar 15, 2024 | DS Articles
Run large language models on your local PC for customized AI capabilities with more control, privacy, and personalization.
Implications and Future Developments of Running Large Language Models Locally
Bringing the utilization of large language models directly to local PCs offers a hefty arena for the advancement of artificial intelligence (AI) technology. This practice not only raises noteworthy benefits for individual users and businesses alike, but also significant challenges and considerations for the future of AI.
Advantages and Long-Term Implications
The shift to localhost usage has a profound impact on data privacy, personalization, and control over AI applications. By running large language models locally, users can ensure data sensitivity as it remains on the device, eliminating risks associated with data transmission to servers.
Secondly, individuals seize greater control over the model customization as per their unique requirements. Local PCs’ running AI language models will host dynamic, personalized, and potentially superior AI functionalities. Innovations in this domain could provoke a transformative leap in the way users traditionally interact with AI.
Future trends in AI might see an exponential growth in AI literacy as users become more acquainted with managing large language models on their PCs. It could also enhance users’ ability to craft AI applications better fit to solve intricate problems in their respective fields.
Challenges and Considerations
While utilizing local PCs’ presents advantages, it also implores significant concerns. One of the most notable is the substantial computational power and storage that large language models require, making it a considerable challenge for average PCs.
The potential incapacity of many devices to manage such power-hungry applications remains a potential roadblock. However, the advancement in hardware technology and efficiency optimization of AI algorithms can mitigate this downside.
Actionable Advice
To harness the potential of running large language models on local PCs, here are some pieces of advice:
- Invest in Hardware Upgrades: Purchasing a PC with advanced computational capabilities will be beneficial. It doesn’t necessarily need to be the most expensive model in the market, but one that correctly aligns with your particular AI requirements.
- Understand Your Needs: Since AI models can be customized as per individual requirements, it’s crucial to understand the precise functionalities and features you need from your AI applications. This understanding will help set your configurations and streamline your AI usage efficiently.
- Learn and Adapt: As the field of AI evolves, it’s essential to be receptive and adaptive to the new developments in executing large language operations locally.
- Secure Your Data: Although data is more secure on a local PC compared to the cloud, there’s still a necessity to adopt robust security measures to protect sensitive information.
In conclusion, the shift towards running large language models on local PCs poses both exciting opportunities and challenges. While we anticipate the scalability in terms of privacy and customization, preparing for the required computational needs and advancing our AI literacy will be key to adapting to this impending AI age.
Read the original article