Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
In the realm of statistics, hypothesis testing stands as a cornerstone, enabling researchers and data analysts to make informed decisions based on data. At its core, hypothesis testing is about determining the likelihood that a certain premise about a dataset is true. It’s a method used to validate or refute assumptions, often leading to new insights and understandings.
Enter R, a powerful and versatile programming language, revered in the data science community for its robust statistical capabilities. R simplifies the complex process of hypothesis testing, making it accessible even to those who are just beginning their journey in data analysis. Whether you’re comparing groups, predicting trends, or exploring relationships in data, R provides the tools you need to do so effectively.
In this article, we delve into the basics of hypothesis testing using R. We aim to demystify the process, presenting it in a way that’s both understandable and practical. By the end, you’ll gain not just theoretical knowledge, but also practical skills that you can apply to your own datasets. So, let’s embark on this journey of statistical discovery together, unlocking new possibilities in data analysis with R.
The Essence of Hypothesis Testing
Hypothesis testing is a fundamental statistical tool that allows us to make inferences about a population based on sample data. At its core, it involves formulating two competing hypotheses: the null hypothesis (H0) and the alternative hypothesis (H1).
The null hypothesis, H0, represents a baseline or status quo belief. It’s a statement of no effect or no difference, such as “There is no difference in the average heights between two species of plants.” In contrast, the alternative hypothesis, H1, represents what we are seeking to establish. It is a statement of effect or difference, like “There is a significant difference in the average heights between these two species.”
To decide between these hypotheses, we use a p-value, a crucial statistic in hypothesis testing. The p-value tells us the probability of observing our data, or something more extreme, if the null hypothesis were true. A low p-value (commonly below 0.05) suggests that the observed data is unlikely under the null hypothesis, leading us to consider the alternative hypothesis.
However, hypothesis testing is not without its risks, namely Type I and Type II errors. A Type I error, or a false positive, occurs when we incorrectly reject a true null hypothesis. For example, concluding that a new medication is effective when it is not, would be a Type I error. This kind of error can lead to false confidence in ineffective treatments or interventions.
Conversely, a Type II error, or a false negative, happens when we fail to reject a false null hypothesis. This would be like not recognizing the effectiveness of a beneficial medication. Type II errors can lead to missed opportunities for beneficial interventions or treatments.
The balance between these errors is crucial. The significance level, often set at 0.05, helps control the rate of Type I errors. However, reducing Type I errors can increase the likelihood of Type II errors. Thus, statistical analysis is not just about applying a formula; it requires a careful consideration of the context, the data, and the potential implications of both types of errors.
R programming, with its comprehensive suite of statistical tools, simplifies the application of hypothesis testing. It not only performs the necessary calculations but also helps in visualizing data, which can provide additional insights. Through R, we can efficiently execute various hypothesis tests, from simple t-tests to more complex analyses, making it an invaluable tool for statisticians and data analysts alike.
In summary, hypothesis testing is a powerful method for making data-driven decisions. It requires an understanding of statistical concepts like the null and alternative hypotheses, p-values, and the types of errors that can occur. With R, we can apply these concepts more easily, allowing us to draw meaningful conclusions from our data.
Hypothesis Testing in R: A Practical Example
In this section, we will demonstrate how to conduct a hypothesis test in R using a real-world dataset. We’ll explore the ‘PlantGrowth’ dataset, included in R, which contains data on the weight of plants under different growth conditions. Our goal is to determine if there’s a statistically significant difference in plant growth between two treatment groups.
Setting Up the Environment
First, ensure that you have R installed on your system. Open R or RStudio and install the easystats package, which includes the report package for detailed reporting of statistical tests:
install.packages("easystats")
library(easystats)
Understanding the Dataset
The ‘PlantGrowth’ dataset in R comprises weights of plants grown in three different conditions. Let’s first examine the dataset:
library(datasets)
data("PlantGrowth")
head(PlantGrowth)
weight group
1 4.17 ctrl
2 5.58 ctrl
3 5.18 ctrl
4 6.11 ctrl
5 4.50 ctrl
6 4.61 ctrl
summary(PlantGrowth)
weight group
Min. :3.590 ctrl:10
1st Qu.:4.550 trt1:10
Median :5.155 trt2:10
Mean :5.073
3rd Qu.:5.530
Max. :6.310
This code loads the dataset and provides a summary, showing us the basic structure of the data, including the groups and the weights of the plants.
Formulating the Hypotheses
Our null hypothesis (H0) states that there is no difference in mean plant growth between the two groups. The alternative hypothesis (H1) posits that there is a significant difference.
Conducting the Hypothesis Test
We’ll perform a t-test to compare the mean weights of plants between two of the groups. This test is appropriate for comparing the means of two independent groups.
result <- t.test(weight ~ group,
data = PlantGrowth,
subset = group %in% c("ctrl", "trt1"))
This line of code conducts a t-test comparing the control group (‘ctrl’) and the first treatment group (‘trt1’).
Reporting the Results
Now, let’s use the report package to provide a detailed interpretation of the test results:
report(result)
Effect sizes were labelled following Cohen's (1988) recommendations.
The Welch Two Sample t-test testing the difference of weight by group (mean in group ctrl = 5.03, mean in group trt1 =
4.66) suggests that the effect is positive, statistically not significant, and medium (difference = 0.37, 95% CI [-0.29,
1.03], t(16.52) = 1.19, p = 0.250; Cohen's d = 0.59, 95% CI [-0.41, 1.56])
-------------------------------------------------------
print(result)
Welch Two Sample t-test
data: weight by group
t = 1.1913, df = 16.524, p-value = 0.2504
alternative hypothesis: true difference in means between group ctrl and group trt1 is not equal to 0
95 percent confidence interval:
-0.2875162 1.0295162
sample estimates:
mean in group ctrl mean in group trt1
5.032 4.661
The report function generates a comprehensive summary of the t-test, including the estimate, the confidence interval, and the p-value, all in a reader-friendly format. And in other form it is still pretty well described.
Interpreting the Results
The output from the report function will tell us whether the difference in means is statistically significant. A p-value less than 0.05 typically indicates that the difference is significant, and we can reject the null hypothesis in favor of the alternative. However, if the p-value is greater than 0.05, we do not have sufficient evidence to reject the null hypothesis.
So looking at our results we can say, that there is certain difference in measure we are checking, but according to high p-value this difference can be as well matter of pure chance, it is not significant statistically.
Visualization
Visualizing our data can provide additional insights. Let’s create a simple plot to illustrate the differences between the groups:
library(ggplot2)
ggplot(PlantGrowth, aes(x = group, y = weight)) +
geom_boxplot() +
theme_minimal() +
labs(title = "Plant Growth by Treatment Group",
x = "Group",
y = "Weight")
This code produces a boxplot, a useful tool for comparing distributions across groups. The boxplot visually displays the median, quartiles, and potential outliers in the data. As you see ctrl and trt1 group indeed do not have big difference their ranges overcome one another. So maybe as exercise you can try check what about pair ctrl and trt2?
Considerations and Best Practices
When conducting hypothesis testing, it’s crucial to ensure that the assumptions of the test are met. For the t-test, these include assumptions like normality and homogeneity of variances. In practice, it’s also essential to consider the size of the effect and its practical significance, not just the p-value. Statistical significance does not necessarily imply practical relevance.
This example illustrates the power of R in conducting and reporting hypothesis testing. The easystats package, particularly its report function, enhances our ability to understand and communicate the results effectively. Hypothesis testing in R is not just about performing calculations; it’s about making informed decisions based on data.
Tips for Effective Hypothesis Testing in R
Hypothesis testing is a powerful tool in statistical analysis, but its effectiveness hinges on proper application and interpretation. Here are some essential tips to ensure you get the most out of your hypothesis testing endeavors in R.
1. Understand Your Data
Explore Before Testing: Familiarize yourself with your dataset before jumping into hypothesis testing. Use exploratory data analysis (EDA) techniques to understand the structure, distribution, and potential issues in your data.
Check Assumptions: Each statistical test has assumptions (like normality, independence, or equal variance). Ensure these are met before proceeding. Tools like ggplot2 for visualization or easystats functions can help assess these assumptions.
2. Choose the Right Test
Match Test to Objective: Different tests are designed for different types of data and objectives. For example, use a t-test for comparing means, chi-square tests for categorical data, and ANOVA for comparing more than two groups.
Be Aware of Non-Parametric Options: If your data doesn’t meet the assumptions of parametric tests, consider non-parametric alternatives like the Mann-Whitney U test or Kruskal-Wallis test.
3. Interpret Results Responsibly
P-Value is Not Everything: While the p-value is a critical component, it’s not the sole determinant of your findings. Consider the effect size, confidence intervals, and practical significance of your results.
Avoid P-Hacking: Resist the urge to manipulate your analysis or data to achieve a significant p-value. This unethical practice can lead to false conclusions.
4. Report Findings Clearly
Transparency is Key: When reporting your findings, be clear about the test you used, the assumptions checked, and the interpretations made. The report package can be particularly helpful in generating reader-friendly summaries.
Visualize Where Possible: Graphical representations of your results can be more intuitive and informative than numbers alone. Use R’s plotting capabilities to complement your statistical findings.
5. Continuous Learning
Stay Curious: The field of statistics and R programming is constantly evolving. Stay updated with the latest methods, packages, and best practices.
Practice Regularly: The more you apply hypothesis testing in different scenarios, the more skilled you’ll become. Experiment with various datasets to enhance your understanding.
Hypothesis testing in R is an invaluable skill for any data analyst or researcher. By understanding your data, choosing the appropriate test, interpreting results carefully, reporting findings transparently, and committing to continuous learning, you can harness the full potential of hypothesis testing to uncover meaningful insights from your data.
Conclusion
Embarking on the journey of hypothesis testing in R opens up a world of possibilities for data analysis. Throughout this article, we’ve explored the fundamental concepts of hypothesis testing, demonstrated its application with a practical example using the PlantGrowth dataset, and shared valuable tips for conducting effective tests.
Remember, the power of hypothesis testing lies not just in performing statistical calculations, but in making informed, data-driven decisions. Whether you’re a budding data enthusiast or an aspiring analyst, the skills you’ve gained here will serve as a solid foundation for your future explorations in the fascinating world of data science.
Keep practicing, stay curious, and let the data guide your journey to new discoveries. Happy analyzing!
Long-term Implications and Future Developments of Hypothesis Testing With R
In the continually evolving field of data analysis, the use of hypothesis testing in conjunction with robust programming languages such as R has become increasingly prevalent. The major insights from the original text hint at its growing importance and potential future developments. Understanding these points could present us with several actionable recommendations to harness the full potential of hypothesis testing in data analysis.
Emphasizing the Importance of Hypothesis Testing in Data Analysis
The essence of hypothesis testing lies in its ability to aid data-driven decision making. It provides a means for data scientists and researchers to determine the likelihood of a specific premise about a dataset being true. As highlighted in the original text, utilizing programming languages like R can significantly simplify this complex process, thereby making it accessible to beginners as well.
Actionable Insight:
Whether you’re a budding data enthusiast or an established researcher, investing your time in learning and refining your hypothesis testing skills with R programming could significantly enhance your data analysis abilities.
Effective Utilisation of the R Language Features
The versatile features offered by R facilitate a deep understanding of data, hence contributing to more accurate outcomes. In a future defined by data-driven decisions, harnessing the full potential of these features could result in effective hypothesis testing, making it an invaluable tool for statisticians and data analysts.
Actionable Insight:
Continued learning about the latest R programming methods, packages, and best practices can keep you updated with the rapidly changing data analysis field. Regular practice could also help develop expertise in applying hypothesis testing in various scenarios.
The Significance of Assumptions and Error Management
In any hypothesis test, assumptions form the basis of analyses. Additionally, understanding potential errors that could arise during the process and how they can be mitigated is crucial in ensuring the reliability of the findings. A careful consideration of these factors can enhance the accuracy of the data interpretation and consequently, the formulated decisions.
Actionable Insight:
Check assumptions pertinent to each statistical test, adjust testing parameters, and understand potential errors ahead of time for a reliable and comprehensive analysis.
Finding a Balance Between Statistical and Practical Significance
While a lower p-value is considered desirable in hypothesis tests, the importance of considering the practical significance of findings is often understated. Future developments may seek to find a balance between statistical significance and practical relevance, thereby making hypothesis testing more applicable in real-world scenarios.
Actionable Insight:
Avoid “p-hacking” and strictly focusing on p-values. Instead, consider practical implications, effect size, and confidence intervals. Statistical significance does not necessarily imply practical relevance, so findings should be interpreted in context.
Conclusion
Hypothesis testing in R is certain to continue playing a pivotal role in the data analysis realm. By emphasizing consistent learning, practical application, and thorough understanding of each aspect of hypothesis testing – from formulating hypotheses to interpreting results – you can stay ahead in this rapidly evolving field.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Introduction
Hey R enthusiasts! Steve here, and today I’m excited to share some fantastic updates about a key function in the tidyAML package – internal_make_wflw_predictions(). The latest version addresses issue #190, ensuring that all crucial data is now included in the predictions. Let’s dive into the details!
What’s New?
In response to user feedback, we’ve enhanced the internal_make_wflw_predictions() function to provide a comprehensive set of predictions. Now, when you make a call to this function, it includes:
The Actual Data: This is the real-world data that your model aims to predict. Having access to this information helps you assess how well your model is performing on unseen instances.
Training Predictions: Predictions made on the training dataset. This is essential for understanding how well your model generalizes to the data it was trained on.
Testing Predictions: Predictions made on the testing dataset. This is crucial for evaluating the model’s performance on data it hasn’t seen during the training phase.
How to Use It
To take advantage of these new features, here’s how you can use the updated internal_make_wflw_predictions() function:
.model_tbl: The model table generated from a function like fast_regression_parsnip_spec_tbl(). Ensure that it has a class of “tidyaml_mod_spec_tbl.” This is typically used after running the internal_make_fitted_wflw() function and saving the resulting tibble.
.splits_obj: The splits object obtained from the auto_ml function. It is internal to the auto_ml function.
Example Usage
Let’s walk through an example using some popular R packages:
library(tidymodels)
library(tidyAML)
library(tidyverse)
tidymodels_prefer()
# Create a model specification table
mod_spec_tbl <- fast_regression_parsnip_spec_tbl(
.parsnip_eng = c("lm","glm"),
.parsnip_fns = "linear_reg"
)
# Create a recipe
rec_obj <- recipe(mpg ~ ., data = mtcars)
# Create splits
splits_obj <- create_splits(mtcars, "initial_split")
# Generate the model table
mod_tbl <- mod_spec_tbl |>
mutate(wflw = full_internal_make_wflw(mod_spec_tbl, rec_obj))
# Generate the fitted model table
mod_fitted_tbl <- mod_tbl |>
mutate(fitted_wflw = internal_make_fitted_wflw(mod_tbl, splits_obj))
# Make predictions with the enhanced function
preds_list <- internal_make_wflw_predictions(mod_fitted_tbl, splits_obj)
This example demonstrates how to integrate the updated function into your workflow seamlessly. Typically though one would not use this function directly, but rather use the fast_regression() or fast_classification() function, which calls this function internally. Let’s now take a look at the output of everything.
[[1]]
# A tibble: 64 × 3
.data_category .data_type .value
<chr> <chr> <dbl>
1 actual actual 15.2
2 actual actual 19.7
3 actual actual 17.8
4 actual actual 15
5 actual actual 10.4
6 actual actual 15.8
7 actual actual 17.3
8 actual actual 30.4
9 actual actual 15.2
10 actual actual 19.2
# ℹ 54 more rows
[[2]]
# A tibble: 64 × 3
.data_category .data_type .value
<chr> <chr> <dbl>
1 actual actual 15.2
2 actual actual 19.7
3 actual actual 17.8
4 actual actual 15
5 actual actual 10.4
6 actual actual 15.8
7 actual actual 17.3
8 actual actual 30.4
9 actual actual 15.2
10 actual actual 19.2
# ℹ 54 more rows
You will notice the names of the preds_list output:
names(preds_list[[1]])
[1] ".data_category" ".data_type" ".value"
So we have .data_category, .data_type, and .value. Let’s take a look at the unique values of each column for .data_category and .data_type:
unique(preds_list[[1]]$.data_category)
[1] "actual" "predicted"
So we have our actual data the the predicted data. The predicted though has both the training and testing data in it. Let’s take a look at the unique values of .data_type:
unique(preds_list[[1]]$.data_type)
[1] "actual" "training" "testing"
This will allow you to visualize the data how you please, something we will go over tomorrow!
Why It Matters
By including actual data along with training and testing predictions, the internal_make_wflw_predictions() function empowers you to perform a more thorough evaluation of your models. This is a significant step towards ensuring the reliability and generalization capability of your machine learning models.
So, R enthusiasts, update your tidyAML package, explore the enhanced features, and let us know how these improvements elevate your modeling experience. Happy coding!
An important function used extensively in the Machine Learning sector, ‘internal_make_wflw_predictions()’, has recently received a major update in the tidyAML package. The changes introduced have addressed key data incorporation issues, ensuring that all elementary data is included in the predictions moving forward.
This article will explore the nuances of these changes, their implications for the future, and present an example of how to effectively utilize the function in its updated form. In this analysis, we’ll also provide actionable advice for R enthusiasts on integrating these changes into their workplace.
Understanding The Changes And Their Future Implications:
The internal_make_wflw_predictions() function has been significantly enhanced to yield a comprehensive set of predictions, in response to extensive user feedback. Highllights of these enhancements include:
The Actual Data: This refers to real-world data that the model aims to predict. Inclusion of the actual data improves an individual’s ability to evaluate the performance of their model on unseen data instances.
Training Predictions: These are forecasts made based on the training dataset. Access to training predictions aids in understanding the model’s generalization to the data it was trained on.
Testing Predictions: These are predictions made on the testing dataset which are crucial for assessing the performance of the model on data it hasn’t encountered during the training phase.
Eliminating the gaps in data used for machine learning models will enable one to perform a more comprehensive evaluation of models. As a result, this increases the reliability and generalization capability of predictive models – a key benefit to the future of machine learning.
Utilizing The Updated Function
The use of the internal_make_wflw_predictions() function with its new enhancements can be simplified into certain steps, as demonstrated in the code provided in the source article. Updating the tidyAML package is also recommended before integrating these changes into your workflow.
Example Usage
Here’s an example of how you can utilize these updates using popular R packages:
library(tidymodels)
library(tidyAML)
library(tidyverse)
tidymodels_prefer()
[…]
# Make predictions with the enhanced function
preds_list <- internal_make_wflw_predictions(mod_fitted_tbl, splits_obj)
By integrating this example into your workflow, the improvements in this function’s updates can substantially impact machine learning model predictions.
Key Advice for R Enthusiasts
The upgrade to the internal_make_wflw_predictions() in the tidyAML package presents an opportunity for more accurate predictions while also offering ease of accessibility to key data. The ability to assess model performance on unseen data will enhance the predictability and reliability of machine learning models.
We advise that users update their tidyAML package and explore the enhanced features. By understanding and utilizing these upgrades, users can elevate their modeling experience significantly and deliver more accurate results.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Implementing parallel execution in your code can be both a blessing and a curse. On the one hand, you’re leveraging more power your CPU has to offer and increasing execution speed, but on the other, you’re sacrificing the simplicity of single-threaded programs.
Luckily, parallel processing in R is extremely developer-friendly. You don’t have to change much on your end, and R works its magic behind the scenes. Today you’ll learn the basics of parallel execution in R with the R doParallel package. By the end, you’ll know how to parallelize loop operations in R and will know exactly how much faster multi-threaded R computations are.
If you’re new to R and programming in general, it can be tough to fully wrap your head around parallelism. Let’s make things easier with an analogy.
Imagine you’re a restaurant owner and the only employee there. Guests are coming in and it’s only your responsibility to show them to the table, take their order, prepare the food, and serve it. The problem is – there’s only so much you can do. The majority of the guests will be waiting a long time since you’re busy fulfilling earlier orders.
On the other hand, if you employ two chefs and three waiters, you’ll drastically reduce the wait time. This will also allow you to serve more customers at once and prepare more meals simultaneously.
The first approach (when you do everything by yourself) is what we refer to as single-threaded execution in computer science, while the second one is known as multi-threaded execution. The ultimate goal is to find the best approach for your specific use case. If you’re only serving 10 customers per day, maybe it makes sense to do everything yourself. But if you have a striving business, you don’t want to leave your customers waiting.
You should also note that just because the second approach has 6 workers in total (two chefs, three waiters, and you), it doesn’t mean you’ll be exactly six times faster than when doing everything by yourself. Managing workers has some overhead time, just like managing CPU cores does.
But in general, the concept of parallelism is a game changer. Here’s a couple of reasons why you must learn it as an R developer:
Speed-up computation: If you’re old enough to remember the days of single-core CPUs, you know that upgrading to a multi-core one made all the difference. Simply put, more cores equals more speed, that is if your R scripts take advantage of parallel processing (they don’t by default).
Efficient use of resources: Modern CPUs have multiple cores, and your R scripts only utilize one by default. Now, do you think that one core doing all the work while the rest sit idle is the best way to utilize compute resources? Likely no, you’re far better off by distributing tasks across more cores.
Working on larger problems: When you can distribute the load of processing data, you can handle larger datasets and more complex analyses that were previously out of reach. This is especially the case if you’re working in data science since modern datasets are typically huge in size.
Up next, let’s go over R’s implementation of parallel execution – with the doParallel package.
R doParallel – Everything You Need to Know
What is R doParallel?
The R doParallel package enables parallel computing using the foreach package, so you’ll have to install both (explained in the following section). In a nutshell, it allows you to run foreach loops in parallel by combining the foreach() function with the %dopar% operator. Anything that’s inside the loop’s body will be executed in parallel.
This rest of the section will connect the concept of parallelism with a practical example by leveraging foreach and doParallel R packages.
Let’s begin with the installation.
How to Install R doParallel
You can install both packages by running the install.packages() command from the R console. If you don’t want to install them one by one, pass in package names as a vector:
install.packages(c("foreach", "doParallel"))
That’s it – you’re good to go!
Basic Usage Example
This section will walk you through a basic usage example of R doParallel. The goal here is to wrap your head around the logic and steps required to parallelize a loop in R.
We’ll start by importing the packages and using the detectCores() function from the doParallel package. As the name suggests, it will return the number of cores your CPU has, and in our case, store it into a n_cores variable:
library(foreach)
library(doParallel)
# How many cores does your CPU have
n_cores <- detectCores()
n_cores
My M2 Pro Macbook Pro has 12 CPU cores:
Image 1 – Number of CPU cores
The next step is to create a cluster for parallel computation. The makeCluster(n_cores - 1) will initialize one for you with one less core than you have available. The reason for that is simple – you want to leave at least one core for other system tasks.
Then, the registerDoParallel() functions sets up the cluster for use with the foreach package, enabling you to use parallel execution in your code:
And that’s all you have to setup-wise. You now have everything needed to run R code in parallel.
To demonstrate, we’ll parallelize a loop that will run 1000 times (n_iterations), square the number on each iteration, and store it in a list.
To run the loop in parallel, you need to use the foreach() function, followed by %dopar%. Everything after curly brackets (inside the loop) will be executed in parallel.
After running this code, it’s also a good idea to stop your cluster.
Here’s the entire snippet:
# How many times will the loop run
n_iterations <- 1000
# To save the results
results <- list()
# Use foreach and %dopar% to run the loop in parallel
results <- foreach(i = 1:n_iterations) %dopar% {
# Store the results
results[i] <- i^2
}
# Don't fotget to stop the cluster
stopCluster(cl = cluster)
The output of this code snippet is irrelevant, but here it is if you’re interested:
Image 2 – Computation results
And that’s how you can run a loop in parallel in R. The question is – will parallelization make your code run faster? That’s what we’ll answer next.
Does R doParallel Make Your Code Execution Faster?
There’s a good reason why most code you’ll ever see is single-threaded – it’s simple to write, has no overhead in start time, and usually results in fewer errors.
Setting up R loops to run in parallel involves some overhead time in setting up a cluster and managing the runtime (which happens behind the scenes). Depending on what you do, your single-threaded code will sometimes be faster compared to its parallelized version, all due to the mentioned overhead.
That’s why we’ll set up a test in this section, and see how much time it takes to run the same piece of code on different numbers of cores, different numbers of times.
The test() function does the following:
Creates and registers a new cluster with n_cores CPU cores, and stops it after the computation.
Uses foreach to perform iteration n_iter number of times.
Keeps track of time needed in total, and time needed to do the actual computation.
Returns a data.frame displaying the number of cores used, iterations made total running time, and total computation time.
Here’s what this function looks like in the code:
test <- function(n_cores, n_iter) {
# Keep track of the start time
time_start <- Sys.time()
# Create and register cluster
cluster <- makeCluster(n_cores)
registerDoParallel(cluster)
# Only for measuring computation time
time_start_processing <- Sys.time()
# Do the processing
results <- foreach(i = 1:n_iter) %dopar% {
i^2
}
# Only for measuring computation time
time_finish_processing <- Sys.time()
# Stop the cluster
stopCluster(cl = cluster)
# Keep track of the end time
time_end <- Sys.time()
# Return the report
return(data.frame(
cores = n_cores,
iterations = n_iter,
total_time = difftime(time_end, time_start, units = "secs"),
compute_time = difftime(time_finish_processing, time_start_processing, units = "secs")
))
}
And now for the test itself. We’ll test a combination of using 1, 6, and 11 cores for running the test() function 1K, 10K, 100K, and 1M times. After each iteration, the results will appended to res_df:
res_df <- data.frame()
# Arbitrary number of cores
for (n_cores in c(1, 6, 11)) {
# Arbitrary number of iterations
for (n_iter in c(1000, 10000, 100000, 1000000)) {
# Total runtime
current <- test(n_cores, n_iter)
# Append to results
res_df <- rbind(res_df, current)
}
}
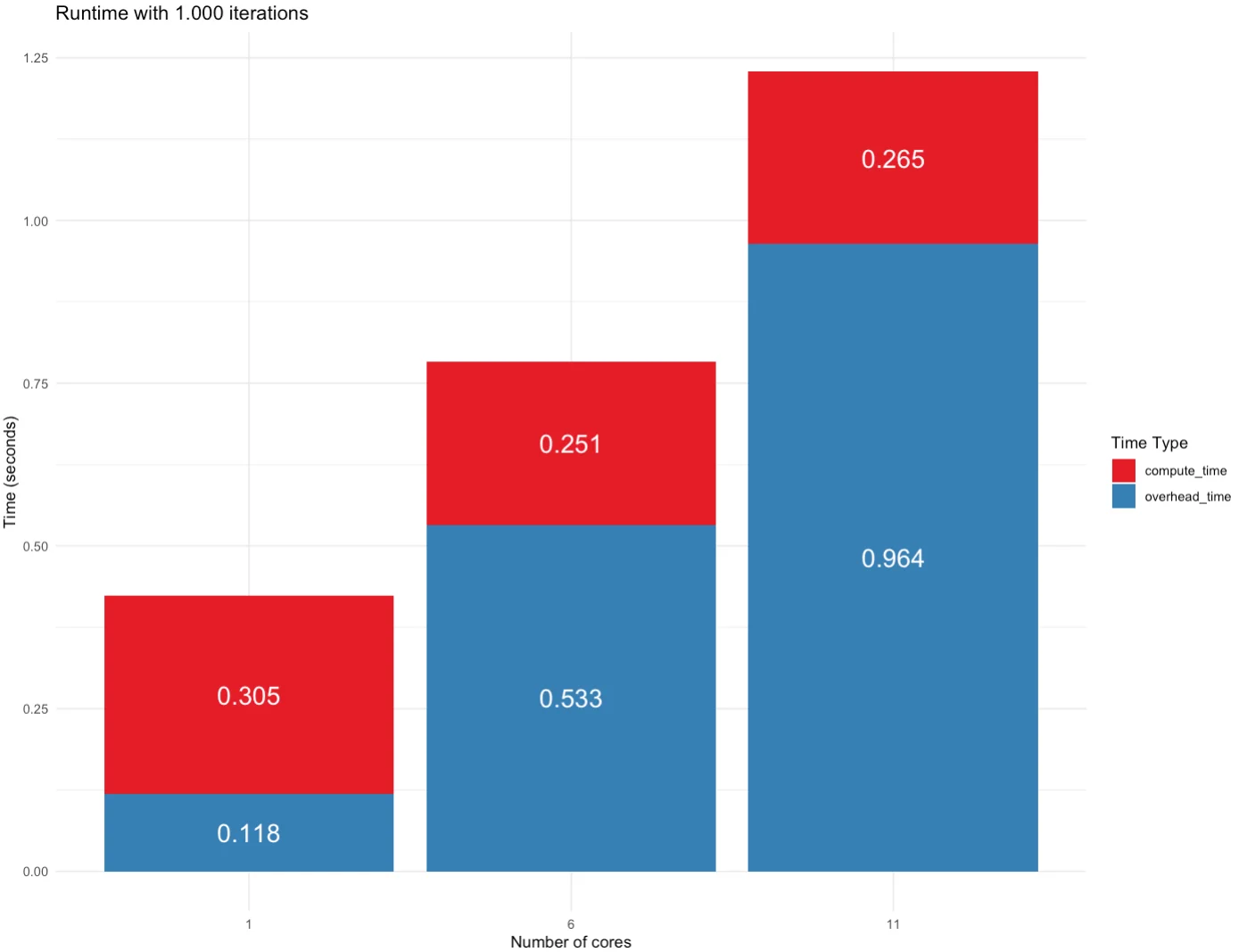
res_df
Here are the results:
Image 3 – Runtime comparisons
Looking at the table data can only get you so far. Let’s visualize our runtimes to get a better grasp of compute and overhead times.
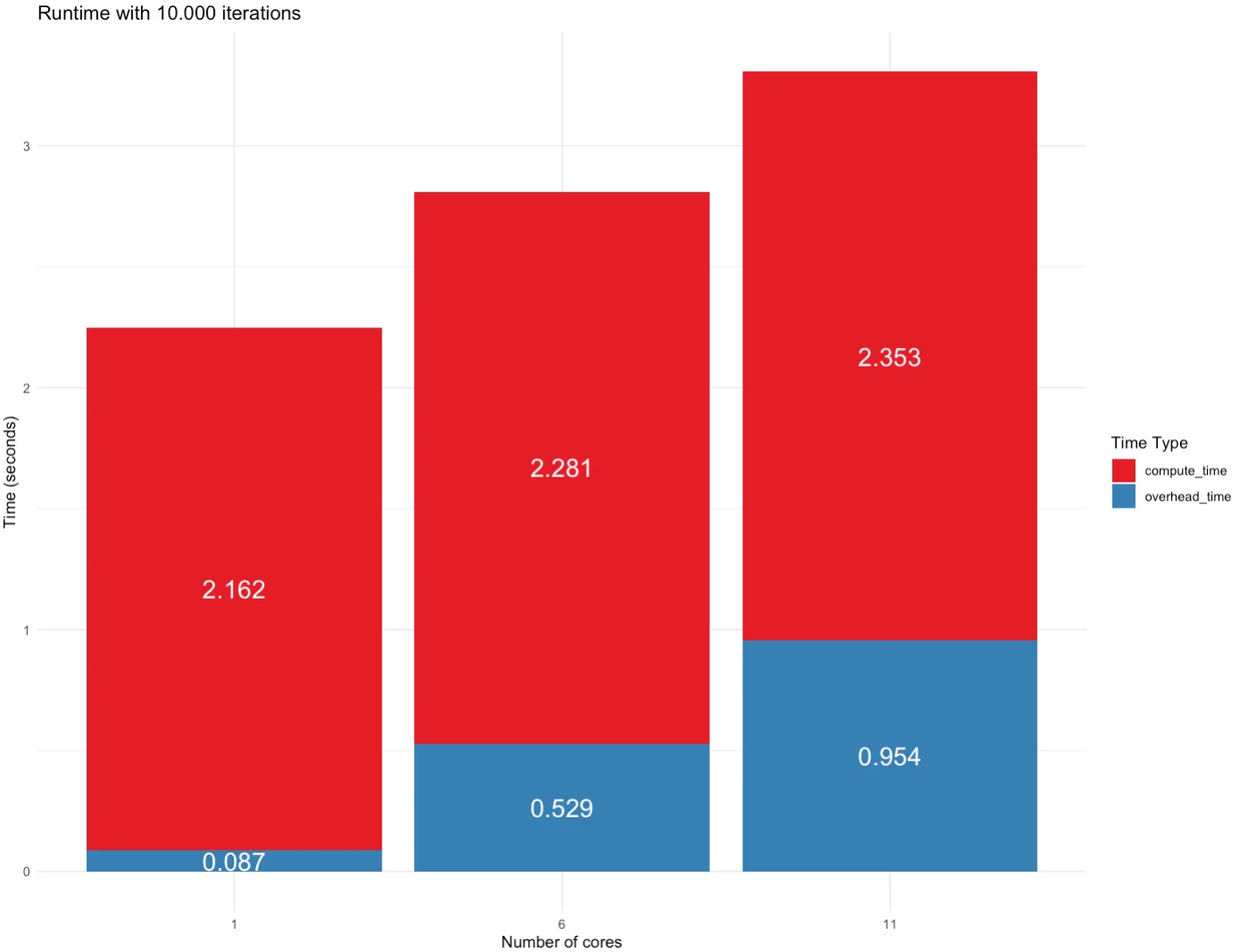
There’s a significant overhead for utilizing and managing multiple CPU cores when there are not so many computations to go through. As you can see, using only 1 CPU core took the longest in compute time, but managing 11 of them takes a lot of overhead:
Image 4 – Runtime for 1K iterations
If we take this to 10K iterations, things look interesting. There’s no point in leveraging parallelization at this amount of data, as it increases both compute and overhead time:
Image 5 – Runtime for 10K iterations
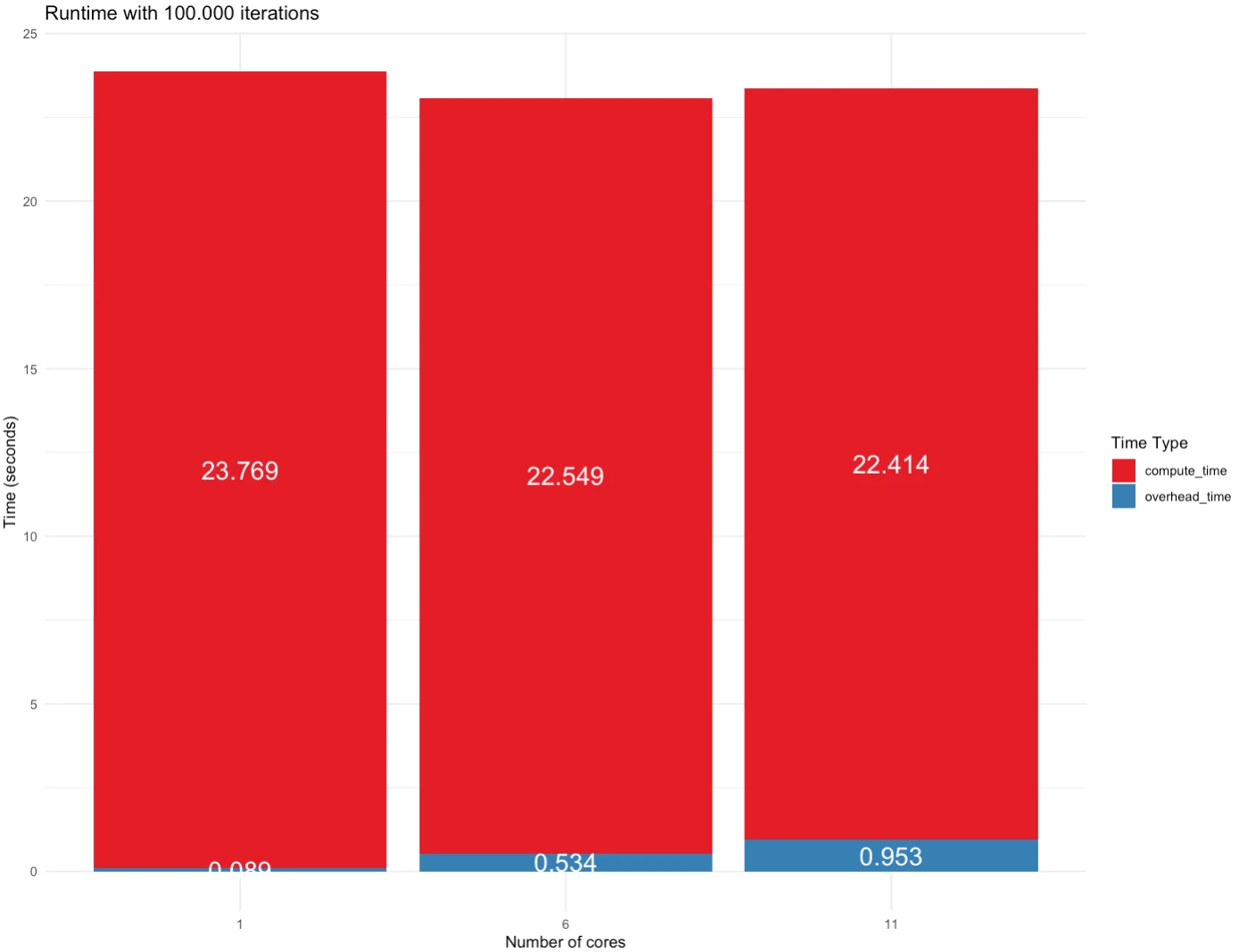
Taking things one step further, to 100K iterations, we have an overall win when using 6 CPU cores. The 11-core simulation had the fastest runtime, but the overhead of managing so many cores took its toll on the total time:
Image 6 – Runtime for 100K iterations
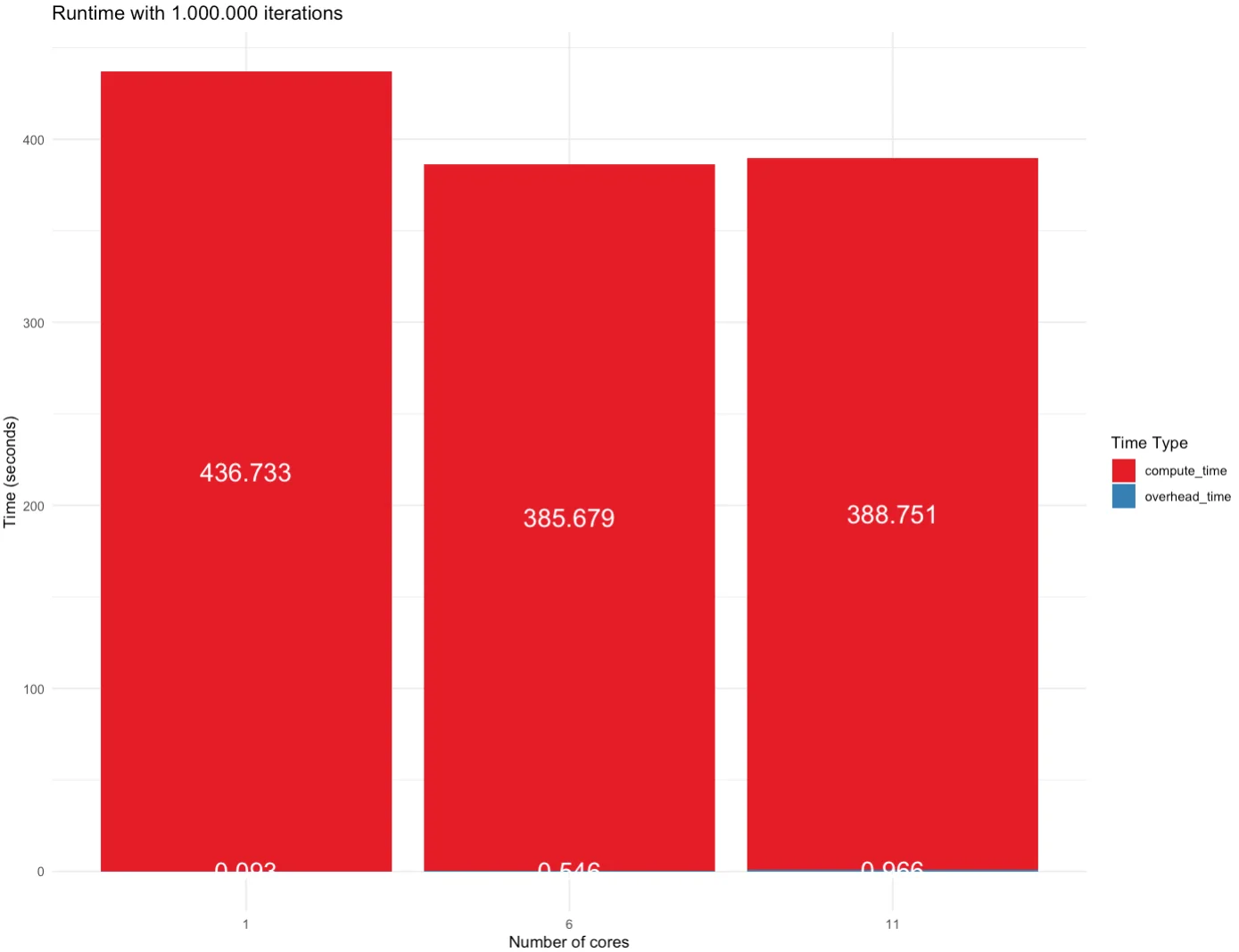
And finally, let’s take a look at 1M iterations. This is the point where the overhead time becomes insignificant. Both 6-core and 11-core implementations come close, and both are faster than a single-core implementation:
Image 7 – Runtime for 1M iterations
To summarize the results – parallelization makes the compute time faster when there’s a significant amount of data to process. When that’s not the case, you’re better off sticking to a single-threaded execution. The code is simpler, and there’s no overhead to pay in terms of time required to manage multiple CPU cores.
Summing up R doParallel
R does a great job of hiding these complexities behind the foreach() function and %dopar% command. But just because you can parallelize some operation it doesn’t mean you should. This point was made perfectly clear in the previous section. Code that runs in parallel is often more complex behind the scenes, and a lot more things can go wrong.
You’ve learned the basics of R doParallel today. You now know how to run an iterative process in parallel, provided the underlying data structure stays the same. Make sure to stay tuned to Appsilon Blog, as we definitely plan to cover parallelization in the realm of data frames and processing large datasets.
Comprehension of Parallel Execution with R’s doParallel Package
The doParallel package in R enables data processing at faster speeds by implementing parallel processing. By using multiple threads for execution, the package leverages more power from the CPU, thus increasing execution speed. This model of operation is likened to having multiple workers in a restaurant, each handling a specific task concurrently to serve customers faster.
However, the use of parallel processing also poses complexities and challenges. It introduces management overhead, so its advantages are significant mainly when dealing with larger datasets and more complex analyses. Therefore, while it’s important for developers to understand this concept, it should be applied judiciously.
Detailed Walkthrough of R doParallel Implementation
Usage of the doParallel package involves certain steps:
Installation: Besides doParallel, it requires installing the foreach package as well. They are installed via R’s install.packages() function.
Basic Usage: After importing the packages, one can determine the number of available CPU cores for parallelization using the detectCores() function. Then the makeCluster() function creates a cluster for parallel computation, which gets registered for use with the foreach package.
Loop Parallelization: Code to be parallelized is placed within a foreach loop followed by the %dopar% operator. The doParallel package allows these loops to run in parallel.
Despite this, there’s no guarantee that parallelization will make code execution faster in all cases. Often single-threaded code is simpler to write and can actually result in faster execution times when including overhead. Hence, deeper analysis is needed to reveal the impact of parallelism on execution speed.
Evaluating Performance Impact of Parallelism Using R doParallel
A practical test conducted for different numbers of cores and iterations illustrated the effects of parallel execution. It was observed that for lower numbers of iterations, the overhead from setting up and managing multiple CPU cores added significantly to the total runtime, exceeding benefits from faster computation.
However, when the amount of data increased to the level of 1 million iterations, overhead time became relatively insignificant. At this scale, parallelism demonstrated superior performance compared to single-thread processing. Thus, significant benefits from parallelization become apparent when processing a larger amount of data.
Final Insights and Suggestions for Future Use of R doParallel
In conclusion, the use of R’s doParallel package for parallel processing can drastically enhance computation speed. However, rendering code for parallel execution may introduce complexities and is not always beneficial due to management overhead.
In terms of future development, extend your knowledge of parallelization beyond loop operations. It’s valuable to utilize parallel processing for more extensive tasks such as handling data frames and large datasets.
Actionable advice: Always consider the trade-offs of implementing parallel processing in your code. Opt for parallel processing when dealing with larger scale problems and maximize CPU utilization.
From Chaos to Clarity: Understanding the Unstructured Data Dilemma.
Understanding the Unstructured Data Dilemma: From Chaos to Clarity
The challenge posed by unstructured data is a growing focus in this digital age. As information continues to accumulate across varied and often disconnected platforms, its potential to drive business decision making increases. However, many businesses are yet to harness the full potential of their unstructured data. With copious amounts of data being generated daily, the dilemma has shifted from data collection to efficient and strategic data utilization.
Long-term Implications
While unstructured data has created a crisis in the short term, its long-term implications present promising opportunities for businesses. Enterprises that can effectively harness and interpret their data can edge out competitors, create new business models, and ultimately drive growth. If adequately managed, unstructured data can be a treasure trove of insights that fuel innovation and strategic business decisions.
However, it’s worth noting that continuing with unmanaged and unanalyzed unstructured data could also lead to significant setbacks. Difficulty in data retrieval, higher storage costs, increased risk of security breaches, and lost opportunities for actionable insights are potential hurdles.
Future Developments
Future developments promise to mitigate the challenges of unstructured data. Advances in artificial intelligence (AI) and machine learning technologies offer robust solutions to extract valuable insights from unstructured data. Implementation of AI-powered tools can not only ease extraction and analysis of unstructured data but also enhance patterns recognition, potentially changing how businesses operate.
Data privacy regulations will continue to evolve and shape the future of unstructured data management. As businesses strive to maintain compliance, an increased focus on secure data storage practices is inevitable.
Actionable Advice
Leveraging the power of unstructured data requires corporations to strategize their approach. The following actionable advice can guide your business towards effective unstructured data management:
Invest in AI and machine learning tools: These technologies can help make sense of massive, unstructured data sets, uncovering trends and insights that could drive strategic decisions.
Ensure data security: Implement robust security measures to protect your data from breaches, thereby safeguarding your confidential information and maintaining compliance with data privacy laws.
Pursue data literacy: Equip your staff with the skills to understand and interpret the data. A team proficient in data literacy can more effectively derive actionable insights.
Integrate your data platforms: Centralizing your data makes it easier to access, track, and analyze. Invest in integrative platforms that consolidate your data sources into a single, manageable point of control.
It’s evident that the unstructured data dilemma presents both challenges and opportunities. By leveraging the right tools and strategies, businesses can turn this potential chaos into clarity, gaining a competitive edge in today’s volatile market landscape.
The future of cloud computing is bright and offers a plethora of opportunities for businesses to grow and evolve.
The Future of Cloud Computing
As advancements in technology evolve, cloud computing has taken center stage as a vital tool for businesses. With the future promising an even brighter landscape, it has become clear that cloud computing will redefine the way enterprises are structured and operate. The potential for growth is astounding offering organizations both big and small long-term potential in terms of efficiency, cost-effectiveness, scalability, and accessibility.
The Long-term Implications
If the current wave of technological advancement is anything to go by, cloud computing’s future is tipped for even more transformation. As business landscapes increase in complexity, the need for flexible and scalable systems becomes paramount. Cloud computing suits perfectly in this scenario thanks to its highly adaptable capabilities.
Businesses will likely wean themselves off traditional systems for a more streamlined cloud-based infrastructure. One major long-term implication may be a shift in operational costs. As companies move away from traditional data centers, they will be able to divert resources typically used for maintaining these infrastructures towards other business aspects. Therefore, savings made in operational costs would be quite substantial.
Scalability and Flexibility
Another key long-term benefit of cloud computing is scalability and flexibility. More businesses are likely to leverage the scalability that cloud services offer allowing them to adapt more effectively to fast-changing markets. Also, businesses can flex their operations easily with cloud computing, minimising redundancy and maximising efficiency.
Future Developments
Following predictions by technology pundits, we can expect a number of possibilities in the world of cloud computing. Here are some prospective future developments:
Greater integration: More software is moving towards being cloud-based, ensuring seamless integration across different platforms.
Advanced security measures: As businesses move more of their operations to the cloud, there will be a higher emphasis on advanced security measures to protect sensitive business data.
AI and Machine learning: Artificial Intelligence (AI) and Machine Learning (ML) are likely to play a significant role in automating and optimizing cloud computing processes.
Actionable Advice
It’s clear that the future of cloud computing is packed with numerous advantages for businesses. To leverage these benefits, it’s imperative for organizations to:
Invest in skills development: Companies should consider investing in training their staff to familiarize them with the dynamics of cloud computing. This will equip them with the right skills to manage and control cloud platforms effectively.
Build robust security systems: With the increased risk of cybersecurity threats, businesses must prioritize building solid security systems to protect their sensitive data.
Adapt to changes: The digital revolution waits for no one. It is essential to recognize the benefits of cloud computing, adapt offerings accordingly, and stay ahead of the competition.
In conclusion, the evolution of cloud computing offers exponential growth opportunities for businesses. Harnessing these benefits will help shape an efficient and competitive future landscape for businesses willing to embrace its potential.
Looking to make a career in data science? Here are five free university courses to help you get started.
Paving Your Way Towards A Prosperous Data Science Career: The Role of Free University Courses
The global need for data scientists is rapidly increasing as organizations in virtually every field require professionals to help them interpret extensive data and inform strategic decisions. This increasing demand has led to the surge of free university courses targeted at aspirants looking to make a career in data science.
Long-term Career Implications
Benefiting from these free data science courses can have profound long-term implications for your professional development. Firstly, they enhance your competency levels and ensure you are equipped with cutting-edge skills vital in this ever-evolving field. Secondly, these courses foster a continuing learning mindset, a significant aspect in staying relevant as disruptive technologies become a norm across industries.
Potential Future Developments
Given the fast-paced nature of the field, we can anticipate several future developments in terms of free university courses on data science. Universities might consider collaborations with leading tech giants to provide experiential learning and real-world data projects. Moreover, there might also be a trend towards more specialized courses focusing on new realms like artificial intelligence (AI), Machine Learning (ML), and big data.
Actionable Points
In light of the given insights, here are actionable steps to maximize your potential in building a thriving data science career:
Regularly Explore Course Offerings: Stay updated on new courses, as new trends emerge in the field of data science. This continued learning will allow you to stay relevant.
Gain Hands-on Experience: Seek opportunities to apply the theoretical knowledge gained through these courses in real-world settings. Practice with datasets and projects that are in line with your career interests.
Develop Soft Skills: While technical expertise is key, enhance your communication, problem-solving, and critical-thinking skills. These are essential for presenting data findings and insights to non-technical team members and stakeholders.
Continue Learning: The learning should not stop with these courses. Continued professional development is key in this fast-paced field. Keep abreaching of latest trends by not limiting yourself to courses, but also participating in webinars, forums and workshops.
Conclusion
To stay at the forefront in the data science field, engaging in free university courses is crucial. They provide a solid foundation for your career and inculcate a culture of continuous learning. The application of these discovered insights will put you on the path to a thriving data science career.