
by jsendak | Dec 8, 2024 | DS Articles

Much like Alice in Alice in Wonderland, who drank from the “Drink Me” bottle and shrank to explore a world she couldn’t access before, nanoeconomics invites us to think small—delving into the granular details of individual behaviors and decisions. By getting “very small indeed,” we unlock insights that reveal inefficiencies, minimize waste, and address Economic… Read More »Let’s Get Small! Nanoeconomics to Address Economic Welfare Loss
Nanoeconomics: A Closer Look at Individual Behavior for Greater Economic Welfare
Just as Alice shrunk herself to explore a world of new perspectives in “Alice in Wonderland,” the concept of nanoeconomics urges us to scale down our thinking and delve into the intricate details of individual behaviors and decisions. This economic approach, focused on the ‘nano’ or ultra-microscopic level, presents us with a wealth of insights that can help reduce inefficiencies, minimize waste and tackle economic welfare loss.
Why Nanoeconomics?
The importance of understanding the economic behaviors and decisions of individuals cannot be overstated. Traditional macroeconomic models have often been critiqued for their inability to address the granular variations in human behavior, hence missing out on considerable opportunities for improvement. By observing these behaviors at a microscopic level, nanoeconomics allows us to identify and address inefficiencies and waste which would otherwise go unnoticed.
The Future of Nanoeconomic Analysis
The potential of nanoeconomics is immense. It offers a platform for economic models that are more realistic, precise, and nuanced. As technology continues to advance, tools such as big data analytics and Artificial Intelligence (AI) will further enhance our ability to observe and analyze individual economic behaviors on a granular level.
The insights gathered can be instrumental in identifying areas of economic waste and inefficiency and crafting policies to minimize these. Hence, it will play an essential role in addressing economic welfare issues both from an individual and broader economic perspective.
Actionable Insights from Nanoeconomics
Invest in Technological Tools
Organizations and governments should invest in technologies like AI and big data analytics that facilitate granular level analysis. These tools will empower them to unearth insights from individual-level data, enabling the design of strategies and policies that can optimize resource allocation and reduce economic waste.
Research and Policy Focus
Policy-makers and researchers should embrace nanoeconomics as a lens through which to examine and understand economic systems. Such analytical scrutiny can reveal valuable insights for crafting more precise and effective policies that account for individual differences and behaviors.
Focus on Education and Awareness
There is a need to create awareness about nanoeconomics at all levels of society. An understanding of how individual actions contribute to overall economic welfare can help individuals make informed decisions that lead to economic efficiency and waste reduction.
By thinking small—really small, we can unlock big insights in economics. The future of economics could well be ‘nano.’
Read the original article
by jsendak | Dec 7, 2024 | DS Articles
[This article was first published on
Blog, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Happy December, R friends!
One of my favorite traditions in the R community is the Advent of Code, a series of puzzles released at midnight EST from December 1st through 25th, to be solved through programming in the language of your choosing. I usually do a few of them each year, and once tried to do every single one at the moment it released!
This year, I know I won’t be able to do it daily, but I’m going to do as many as I can using just data.table solutions.
I’ll allow myself to use other packages when there isn’t any data.table equivalent, but my solutions must be as data.table-y as possible.
I’m going to abuse the blog post structure and update this file throughout the week.
December 1st
Part One
d1 <- fread("day1_dat1.txt")
d1[, V1 := sort(V1)]
d1[, V2 := sort(V2)]
d1[, diff := abs(V1-V2)]
sum(d1$diff)
Part Two
d1[, similarity := sum(V1 == d1$V2)*V1, by = V1]
sum(d1$similarity)
December 2nd
Part One
d1 <- fread("day2_dat1.txt", fill = TRUE)
check_report <- function(vec) {
vec <- na.omit(vec)
has_neg <- vec < 0
has_pos <- vec > 0
inc_dec <- sum(has_neg) == length(vec) | sum(has_pos) == length(vec)
too_big <- max(abs(vec)) > 3
return(inc_dec & !too_big)
}
d1t <- transpose(d1)
deltas <- d1t[-nrow(d1t)] - d1t[2:nrow(d1t)]
res <- apply(deltas, 2, "check_report")
sum(res)
Part Two
test_reports <- function(dat) {
deltas <- dat[-nrow(dat)] - dat[2:nrow(dat)]
res <- apply(deltas, 2, "check_report")
res
}
res <- test_reports(d1t)
for (i in 1:nrow(d1t)) {
res <- res | test_reports(d1t[-i,])
}
sum(res)
Just for fun
I found the use of apply deeply unsatisfying, even though it was fast, so just for fun:
d1t <- transpose(d1)
deltas <- d1t[-nrow(d1t)] - d1t[2:nrow(d1t)]
is_not_pos <- deltas <= 0
is_not_neg <- deltas >= 0
is_big <- abs(deltas) > 3
res_inc <- colSums(is_not_neg | is_big, na.rm = TRUE)
res_dec <- colSums(is_not_pos | is_big, na.rm = TRUE)
sum(res_inc == 0) + sum(res_dec == 0)
Yay.
Continue reading: Advent of Code with data.table: Week One
Advent of Code: Leveraging data.table for Programming Puzzles
The Advent of Code, a series of increasingly complex programming puzzles typically solved in multiple programming languages, holds a prominent place in the R programming community’s festive traditions. The event extends from December 1st through to the 25th and provides users an intriguing platform to showcase their programming skills.
Long-term Implications
The long-term implications of using data.table and R to solve the Advent of Code puzzles are manifold. Firstly, data.table is a highly optimized data manipulation package in R which has a significant speed advantage. This advantage can enable programmers to solve larger-scale complex problems in a fraction of the time it might take using other R packages.
Moreover, the systematic approach to solving Advent of Code puzzles with data.table provides a real-world practical example of how efficient data manipulation techniques can be applied in programming using R. This practice serves as a learning tool, contributing to the improvement of technical programming skills among participants as well as observers.
Future Developments
As R and data.table continue to be optimized and enriched with new features, solving the Advent of Code puzzles with these resources will become increasingly efficient. Additionally, as more individuals participate in this event using R and its packages, more creative and effective solutions will be generated that can act as learning resources for others.
Actionable Advice
- Embrace Challenges: Participate in the Advent of Code event as it offers a platform to challenge yourself, solve problems using R, and learn from others.
- Use Optimized Packages: Utilize the data.table package where necessary for efficient data manipulation and querying. This method can significantly reduce the computation time required to solve complex problems.
- Share Your Solutions: Share your solutions publicly and provide explanations where possible to help others learn from your expertise and approach.
- Stay Updated: Constantly update your knowledge about the latest functions and features in R and its packages. Staying up-to-date allows you to incorporate these features in your solutions effectively.
Read the original article
by jsendak | Dec 7, 2024 | DS Articles
Whether you’re building an LLM from scratch or augmenting an LLM with additional finetuning data, following these tips will deliver a more robust model.
Long-term implications and future trends in LLM creation and improvement
Building an LLM (Language Learning Model) whether from scratch or attempting to augment an existing one with additional fine-tuning data, is a complex task that holds a promising future. With the advancement of artificial intelligence and machine learning, these models are progressively becoming more refined. However, it’s the keen attention to detail in their design process that results in a robust model, capable of accuracy and adaptability.
Long-term implications
The gradual refinement of Language Learning Models presents an opportunity for a seismic shift in sectors like education, communication, and business. Language barriers that once hindered multinational operations might be obliterated, fostering efficient dialogues across continents and cultures.
The development and advancement of such tools might spearhead the transformation towards an era of seamless and intuitive communication. The long-term prospect for LLMs implies a future where machines could potentially understand, translate, and even respond in any global language with the fluidity of a native speaker.
Future developments
Artificial intelligence, in its ever-developing state, can provide new capabilities to LLMs. Few future developments may include:
- Advanced emotions detection: Future LLMs may understand and respond to human emotions based on the tone of communication.
- Superior semantic understanding: They might boast an enhanced capacity to comprehend context, slang, and colloquial language, thus delivering an even more human-like interaction.
- Personalized language learning: LLMs may offer tailored language learning experiences, adapting to individual learning styles and speeds.
Actionable advice
Based on the long-term implications and potential future developments in LLM, the following actions can be taken:
- Investment: Corporate entities, especially in the technology sector, should consider investing resources in the development of such models. This may result in significant ROI in the long run.
- Collaboration: Collaboration between AI developers and linguists could help in building LLMs that are more comprehensive and adaptable.
- Research: Continue to emphasize research in this field. As the technology further evolves, it will be crucial to stay updated with the latest developments and its implications in the effective use of LLMs.
- Policy: It will be increasingly important for public and industry policies to be established to regulate the use of LLMs and ensure they are used ethically and responsibly.
Rapid advancement in artificial intelligence and machine learning indicates a promising future for LLMs. To stay ahead in this domain, incessant learning and understanding of these technologies will be pivotal in unleashing robust and efficient language learning models.
Read the original article
by jsendak | Dec 7, 2024 | DS Articles
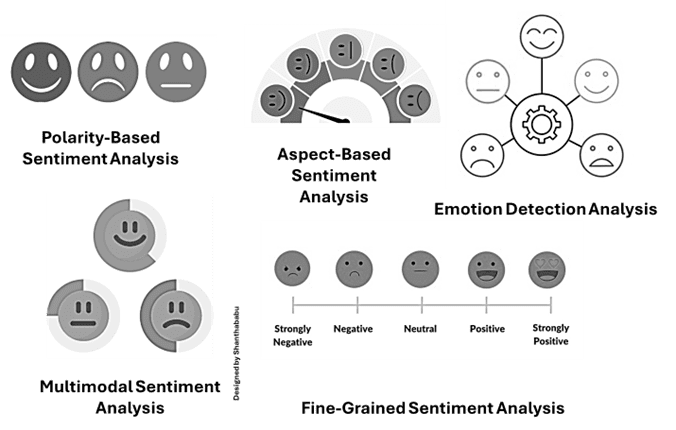
Introduction Sentiment analysis, also known as opinion mining, is a powerful concept in the Natural Language Processing (NLP) technique that interprets and classifies emotions expressed in textual data. Of course, it identifies whether the sentiment is positive, negative, or neutral. With the outcome, each business and researcher can enable and understand customer opinions, market trends,… Read More »Sentiment analysis at scale: Applying NLP to multi-lingual and domain-specific texts
Summary of Sentiment Analysis in Natural Language Processing
Sentiment analysis, or opinion mining, is a highly effective method utilized in the techniques of Natural Language Processing (NLP). It interprets and categorizes emotional undertones expressed within textual data, identifying sentiments as either positive, negative, or neutral. This knowledge has wide utility, enabling businesses and researchers to comprehend customer attitudes, emerging market trends, and much more.
Long-Term Implications of Sentiment Analysis
Enhancements in Customer Insights
As businesses start to understand customer sentiment more effectively, they can proactively make adjustments based on their needs and preferences. This could lead to improved customer experience, higher levels of satisfaction, and ultimately, stronger brand loyalty.
Ability to Forecast Market Trends
With sentiment analysis, businesses would be better equipped to recognize emerging patterns and trends. These trends might be in the form of online sentiments expressed towards new product launches, changes in industry regulations, or shifts in consumer behavior. As a result, businesses can stay ahead of the curve and adjust their strategies accordingly.
Future Developments in Sentiment Analysis
Application to Multi-Lingual Texts
Future innovations in sentiment analysis could expand to include multi-lingual processing. As businesses become increasingly global, their customer base becomes more diverse linguistically. Thus, processing and interpreting multi-lingual texts to understand sentiment could be a critical development in NLP.
Domain-Specific Texts
Data from specific domains, such as legal texts or medical records, present a unique challenge with their specialised language and context. Future advancements in NLP and sentiment analysis might address this challenge, helping organizations in these sectors understand their client sentiment better.
Actionable Advice
- Invest in NLP Technologies: To stay ahead of the curve, organizations should consider investing in NLP technologies to boost customer understanding and proactively respond to emerging market trends.
- Upskill Teams: Ensure that teams are well-versed in the latest NLP tools and techniques. Regular training on advancements in NLP and sentiment analysis would be helpful.
- Expand Linguistic Capabilities: If you operate in multiple countries or have multicultural audiences, expanding your business’s linguistic capabilities could be of immense value. This can include investing in tools capable of multi-lingual sentiment analysis.
- Adapt to Domain-Specific Analysis: If your organization operates in a specialized field with unique language or context, developing or using NLP applications for domain-specific analysis could drastically improve your business’s understanding of consumer sentiment.
Read the original article
by jsendak | Dec 6, 2024 | DS Articles
[This article was first published on
geocompx, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
As 2024 comes to an end, we have things to celebrate in the geocompx community, including the completion of two books: the second edition of Geocomputation with R and the first edition of Geocomputation with Python. Both books are open-source, can be accessed by anyone for free online, and will be on sale soon (watch this space). We are proud of the work we have done, grateful for the contributions we have received, and excited about the future.
We think that open source and open access resources are essential for the development of the field of geocomputation. They allow people to learn about geocomputation, improve their skills, and solve real-world problems. They also enable researchers to share their work, collaborate with others, and build on existing knowledge. In short, we believe that open-source geocomputational resources can make the world a better place.
However, creating, maintaining, and contributing to such resources is time-consuming and can be hard to sustain, especially for newcomers to open source software development who are likely to be younger and less financially secure.1
Now, we opened two ways to support the geocompx project financially:
- First, you can donate to the project using the following link: donate.stripe.com/4gweWl94Q9E35AQ6oo.
- Second, you can sponsor the project on GitHub at github.com/sponsors/geocompx.
The donations and sponsorships will be used to support the development and maintenance of the project. Our ideas for using the funds include:2
- Paying for the domain and other infrastructure costs
- Supporting contributors to the project, for example, by providing free books or bounties3
- Organizing competitions and other events to promote the project and engage the community
We appreciate any support you can provide, whether it’s a one-time donation, a monthly sponsorship, or simply spreading the word about the project. Thank you for helping us make open-source geocomputational resources more accessible and sustainable!
Citation
BibTeX citation:
@online{nowosad,_robin_lovelace2024,
author = {Nowosad, Robin Lovelace, Jakub},
title = {Support Geocomp*x* and the Development of Open-Source
Geocomputation Resources!},
date = {2024-12-06},
url = {https://geocompx.org/post/2024/support/},
langid = {en}
}
For attribution, please cite this work as:
Nowosad, Robin Lovelace, Jakub. 2024.
“Support Geocomp*x* and the
Development of Open-Source Geocomputation Resources!” December 6,
2024.
https://geocompx.org/post/2024/support/.
Continue reading: Support geocompx and the development of open-source geocomputation resources!
Future Developments in Open-Source Geocomputation
As we bid farewell to 2024, it is evident that the field of geocomputation is gaining ground, with the completion of two noteworthy texts: Geocomputation with R second edition and the first edition of Geocomputation with Python. Produced by the geocompx community, these books are available for free as open-source resources, underscoring the team’s dedication to fostering information accessibility and skill enhancement in the field of geocomputation.
The Value of Open-Source Geocomputational Resources
The geocompx community champions the importance of open-source resources within the realm of geocomputation. The proponents argue that such resources do not just facilitate learning and skill enhancement, but also provide a platform for global researchers to share their work, foster collaborations, and build upon existing knowledge. Their aim is simple: to leverage open-source geocomputational resources to create a better world. However, they acknowledge the significant challenges involved in establishing and maintaining these resources, particularly for beginners in open-source software development, who are likely younger and less financially secure.
Supporting the Initiative
The geocompx project has opened up avenues for financial support via two mechanisms. Donations can be made directly using a specific link or sponsorship can be engaged through GitHub. Contributions are primarily funneled into infrastructural costs, such as domain procurement, while also offering various forms of support to contributors. The geocompx project also aims to leverage funds to facilitate competitions and community events to improve visibility and engagement in the project.
The Long-Term Implications
With free access to open-source textbooks like Geocomputation with R and Geocomputation with Python, more individuals can gain deep insights into geocomputation, potentially catalyzing research innovations and solutions to address real-world challenges. Moreover, fostering such a culture of knowledge sharing can stimulate effective collaborations, further propelling advancements in the field.
On another note, the financial support model of geocompx appears to be poised for a long-standing, sustainable future. Contributions manifest as a direct investment into the field of geocomputation by funding infrastructure costs, supporting contributors, and facilitating community events – all of which are crucial to the continual growth and development of the field.
Actionable Advice
If you value the work of the geocompx community and believe in the power of open-source resources, consider supporting their efforts. Donations can be made via Stripe or through sponsorship on GitHub. Even if a financial contribution is not viable for you, spreading the word about the project can be hugely impactful.
In a broader perspective, individuals, corporations, and educational institutions with vested interest in geocomputation can also incorporate these open-source texts into their learning and research processes. They offer a treasure trove of knowledge that can spark new lines of thought, facilitate skills development, and fuel progress in the world of geocomputation.
Read the original article
by jsendak | Dec 6, 2024 | DS Articles
Learn how to bring the power of AI right to your Android phone—no cloud, no internet, just pure on-device intelligence!
Bringing AI to Your Android: The Future is Here
Android smartphones have grown in capabilities vastly over the years. Interestingly, they offer much more than just communication – they’re taking significant strides towards enabling AI capabilities on devices, right into the pockets of customers. This development boasts of providing AI power that doesn’t require any cloud or internet assistance – this is pure on-device intelligence, and it’s set to revolutionize the way we interact with our smartphones.
The Long-Term Implications
The potential of having AI capabilities right in our Android devices holds implications that will impact the future of technology significantly:
- Enhanced User Experiences: AI capabilities can enable possibilities for personalization in real time based on user behavior, preferences, and location. This would particularly excel in areas such as recommendation systems, providing users with uniquely tailored experiences.
- Increased Device Efficiency: On-device AI can control energy and processor usage more effectively, extending battery life and improving overall device performance.
- Data Privacy: Unlike cloud-based AI, on-device AI doesn’t require data to be sent over the Internet for processing, protecting user data and maintaining privacy.
Possible Future Developments
At the intersection of mobile technology and AI, there are seemingly limitless possibilities. Some potential developments could include:
- Gesture Control: AI could enable more intuitive interfaces, such as gesture control. Slight hand motions could allow you to scroll, zoom in and out, or navigate across multiple applications.
- Advanced Health Monitoring: AI could analyze health data, predict potential health risks, and guide users towards healthier life choices.
- Smarter Personal Assistants: AI power could transform voice-driven assistants to understand context, learn from past interactions, and provide more meaningful assistance.
Actionable Advice
Embracing the potential of on-device AI is no longer a luxury—it’s a necessity. Here are a few bits of actionable advice to harness its full potential:
- Upgrade Your Device: To take advantage of on-device AI capabilities, consider upgrading to a device with the latest hardware capable of supporting these features.
- Stay Updated: Always ensure your device is running the latest software to keep up with advancements and improvements in AI applications.
- Privacy Settings: Be aware of the privacy settings of different apps involving AI. Revisit settings frequently to ensure your data is protected and used in a way you’re comfortable with.
The power of AI in the palm of your hand promises an exciting future. It’s up to us to embrace it, cherish it, and gear up for the thrilling ride ahead in technology.
Read the original article



























 ︎
︎