[This article was first published on Getting Genetics Done, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
In the spirit of Learning in Public, I wanted an excuse to explore (1) click for creating command line interfaces, (2) Cookiecutter project templates, and (3) modern tools in the Python packaging ecosystem. If you’re primarily an R developer like me, I recently wrote about resources for getting better at Python for R users.
Click is a really nice package for creating command line interfaces, and I like it better than argparse or other similar utilities. Simon Willison’s click app cookiecutter template was really helpful in getting the boilerplate set up for a python package, and while I looked at build backends like Flit, Poetry, uv, etc., I ended up just using setuptools with a pyproject.toml.
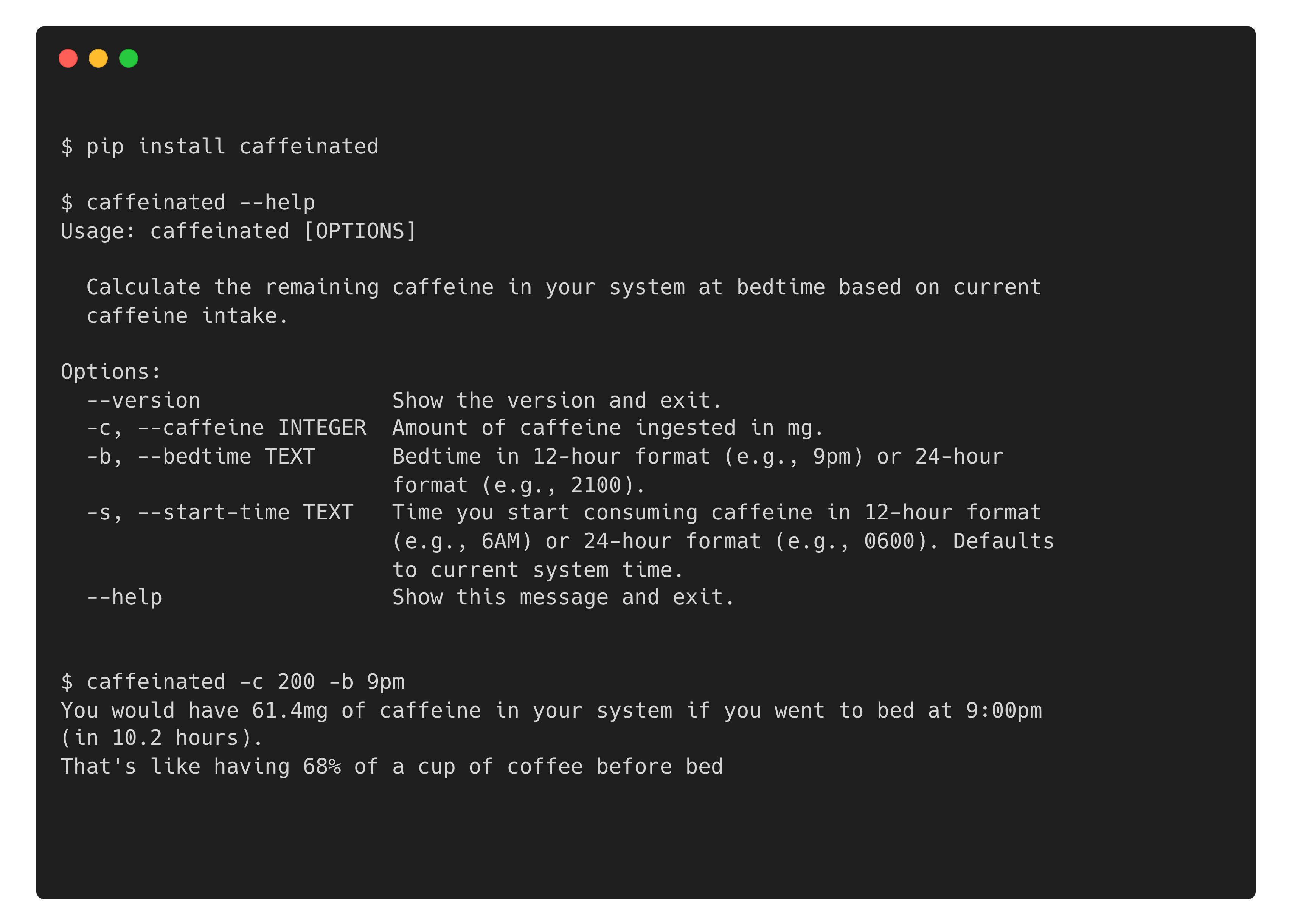
For this demo I built a silly little Python tool called caffeinated (inspired by coffee-o-clock) that tells you how much caffeine you’ll still have in your system at bedtime based on how much you consume and when. You can install it from PyPI and running caffeinated with the --help option (or without any arguments) prints the help. The code is on GitHub (github.com/stephenturner/caffeinated) if you want to follow along.
Demonstration of installing and running caffeinated (on GitHub and PyPI). First, pip install caffeinated, then run caffeinated --help for usage info. Run caffeinated -c 200 -b 9pm to see how much caffeine will remain in your system if you consume 200mg caffeine right now and go to bed at 9pm.
I’m not totally sure how accurate the formula is here, but I’m using this to calculate how much caffeine remains in circulation (and I’m going with 90mg for “a cup of coffee”).1
Where:
N(t) = Quantity of caffeine remaining
N0 = Original amount of caffeine
t = Time
t6 = Coffee’s half-life (6 hours)
Click
Click (Command Line Interface Creation Kit) is a Python package for creating command line interfaces in a composable way with as little code as necessary.
Why Click? Why not argparse/docopt/etc? Good questions. The Click documentation has a section on Why Click?, Why not Argparse? and Why not Docopt etc.? I like click because it enables you to easily create command line utilities with subcommands (e.g., mycommand subcommand ... e.g. like bedtools intersect ...), and it supports file handling, makes it easier to handle options versus arguments, and easily supports ANSI coloring of the output.
Simple Click demo
First let’s set up a folder structure we’ll use to create a Python package. Make a new folder named whatever you’re calling the package (in this case, caffeinated), and in that directory create a pyproject.toml file. Create a new subfolder with the same name as the parent directory (caffeinated), and in that folder you’ll have three files. Directory structure should look like this:
caffeinated/
caffeinated/
__init__.py
__main__.py
cli.py
pyproject.toml
The pyproject.toml will have just the basics you need for a Python package:
[project]
name = "caffeinated"
version = "0.1.1"
dependencies = ["click"]
[project.scripts]
caffeinated = "caffeinated.cli:caffeinated"
The __init__.py will be empty, and the __main__.py will just have one line that imports the function from the cli.py:
from .cli import caffeinated
if __name__ == "__main__":
caffeinated()
The cli.py actually has the code for your command line tool. This is a really simple program that just echos out the amount of caffeine you consumed and what time your bedtime is:
And now the caffeinated command line utility is ready to use. First, get some help. Notice how by specifying a default value
$ caffeinated --help
Usage: caffeinated [OPTIONS]
Options:
-c, --caffeine INTEGER
-b, --bedtime INTEGER
--help Show this message and exit.
Now run it:
$ caffeinated -c 200 -b 2100
Caffeine consumed: 200 mg
Your bedtime is: 2100
The real caffeinated app
You can see the real cookiecutter code here: github.com/stephenturner/caffeinated. Here are links to the actual working code. Everything important is in the cli.py file. It adds a few more arguments, picks up the version from the pyproject.toml, and defines functions to do all the calculation and conveniences such as translating “9pm” into 2100 (hours).
Once you update all the source or just pip install caffeinated again from PyPI, the tool will tell you approximately how much caffeine you’ll have remaining in your system after consuming a certain amount of caffeine at your chosen bedtime. Run caffeinated --help to get help on the options.
Cookiecutter
Organizing your project as a well-structured Python package can streamline development and distribution. The Cookiecutter package provides a straightforward way to generate project templates, ensuring consistency and best practices across your projects. Install it with pip, then I’ll use Simon Willison’s click-app cookiecutter template.
I’ve written scores of R packages for fun and profit. There’s really only one build backend toolchain for R packages that everyone uses: devtools with Roxygen documentation with liberal assistance from usethis.
The Python documentation has a good guide on Packaging Python Projects. The build backend ecosystem in Python is more diverse. I really wanted to take a closer look at Flit, Poetry, Hatch, and others, but because the cookiecutter template that I used created a pyproject.toml using setuptools by default, so I just ran with that.
setuptools is probably the oldest and most widely used packaging tools in Python with good documentation and community support. And with PEP 517, the standard became using a simpler pyproject.toml rather than the old setup.py. You can see my pyproject.toml for caffeinated here. It’s pretty simple, and one key feature is the readme="README.md" entry, which results in the documentation on the PyPI landing page (pypi.org/project/caffeinated/) populated with the README.md in the project root, avoiding the need for duplication.
Flit (flit.pypa.io) looks like a very minimal, very simple build backend for packaging plain Python code. I also took a look at Poetry (python-poetry.org), because if I were building something more complex I think I’d want something to help me manage dependencies instead of having to add them to the pyproject.toml by hand. Poetry helps with this. Finally, there’s a lot of interest in uv (docs.astral.sh/uv) right now. It’s a Python package and project manager written in Rust, and the benchmarks are impressive. See the “uv: Unified Python packaging” blog post for more. uv doesn’t yet have a build backend, but that’s in the works at astral-sh/uv#3957.
Building python packages with setuptools vs Flit vs Poetry vs uv might be the subject of a future post, but for now, I’m just using setuptools+build.
building and deploying with setuptools+build+twine
The pyproject.toml created by the cookiecutter template I used had just about everything I needed to build the package. From here it was simple. This will build the .whl binary file and .tar.gz source packages in a dist/ folder.
python -m build
After this it’s fairly straightforward to upload this to PyPI. But, before uploading to the production pypi.org, you should probably upload to the testing repository (test.pypi.org) first to avoid polluting PyPI with broken or testing packages.
twine upload -r testpypi dist/*
Uploading to the real PyPI follows the same convention. I recommend using a token in your .pypirc file instead of a username/password prompt.
twine upload dist/*
A few seconds later your package will be on PyPI, and you can install it with pip install like you would any other package. The caffeinated package is on PyPI at https://pypi.org/project/caffeinated/.
If you’ve ever tried getting a package into CRAN you know how onerous the process can be and how strict the CRAN maintainers can be2 and you may be shocked to see how easy it is to get a package onto PyPI. There is no curation or review process with PyPI. Upload your source and wheel files with twine and your package is live.
Docker
Once the app is on PyPI it’s easy to create a Docker container. There’s a Dockerfile in the repo that looks like this:
FROM python:3.11-alpine
RUN pip install caffeinated
WORKDIR /files
ENTRYPOINT ["caffeinated"]
CMD ["--help"]
You can build it like this (replace stephenturner with your Docker username):
$ docker run stephenturner/caffeinated -c 200 -b 9pm
You would have 35.4mg of caffeine in your system if you went to bed at 9:00pm (in 15.0 hours).
That's like having 39% of a cup of coffee before bed.
Alternatively, you can easily create an image with your new tool and additional tools you might want in the same container using Seqera containers (see the video linked further below for more details). I created this image that includes both caffeinated and cowsay, and I’m piping the result of caffeinated into cowsay.
$ docker run --rm community.wave.seqera.io/library/pip_caffeinated_python-cowsay:5a33eb2abfe4e6a5 sh -c 'caffeinated --caffeine 200 --bedtime 9pm --start-time 8am | cowsay'
__________________________________________
/ You would have 44.5mg of caffeine in
| your system if you went to bed at 9:00pm |
| (in 13.0 hours). That's like having 49% |
of a cup of coffee before bed. /
------------------------------------------
^__^
(oo)_______
(__) )/
||----w |
|| ||
Learning more
This is part of my TIL / Learning in Public series, which I wrote about recently:
For a quick intro on Click, see the official Click intro video. It’s over 10 years old at this point, it’s mostly still applicable.
This video from NeuralNine demonstrates how to create Click groups to create CLI utilities with subcommands:
This video from ArjanCodes explains how to create a Python Package and publish on PyPI. It uses the old setup.py instead of the more modern pyproject.toml convention, but otherwise it’s still good to understand the steps in the process.
Finally, a little more about easily creating containers with multiple tools for multiple architectures using Seqera Containers:
To leave a comment for the author, please follow the link and comment on their blog: Getting Genetics Done.
Long-term Implications and Possible Future Developments
The use of Click and Cookiecutter to build Command Line Interface (CLI) tools using Python can have several long-term implications. They make it possible to design more efficient and user-friendly command line tools. In addition, the ability to standardize boilerplate tasks through Cookiecutter templates results in faster and more consistent development. Plus, their relatively simpler design, when compared to other tools like argparse makes them more favorable to use.
Actionable Advice Based on Insights
Learn the Basics: Good grasp of Python and understanding Click and Cookiecutter packages is a prerequisite to successful command line tool development. Watching some introductory videos about Click and Cookiecutter can give an intuitive understanding of how they work and their practical uses. Familiarize yourself with creating and reading toml (Tom’s Obvious, Minimal Language) files. They are particularity useful to Python data science projects.
Plan ahead: Your project will be easier to manage if you plan your directory structure and decide what each part of your application will do. Using tools like Click and Cookiecutter can help standardize the project structure. Make sure to understand their directory structure and the logic behind it.
Practice of the application: Getting more familiar with the process of creating your own Python package from scratch and then deploy and distribute it using Docker or other similar services enhances your practical skills in this field. This will be helpful not just for Python but also for other programming languages you would learn in the future.
Stay updated: As with any other technology, keeping yourself updated with changes in Python packaging and distribution tools is crucial. The comparison between setuptools, Flit, Poetry, uv and such tools could be a good research topic to stay abreast of the evolving tech.
Potential Future Developments
The future may see further development in Python packaging and distribution tools. Improvements could come in with increased simplicity, more automation, and more robust management of more complex projects. Or, new technologies could emerge to supplement or even replace some of these existing tools. So, tracking these developments should be an essential part of every developer’s learning journey.
Conclusion
Utilizing Click and Cookiecutter for building CLI tools provides a significant opportunity to streamline development workflows. By learning these tools and understanding their advantages and applications, developers can leverage them to enhance productivity and efficiency. Maintaining an aware of evolving trends and techniques can lead to more optimal utilization of these and other Python packages and tools.
arXiv:2411.04685v1 Announce Type: new Abstract: This paper focuses on the generalized grouping problem in the context of cellular manufacturing systems (CMS), where parts may have more than one process route. A process route lists the machines corresponding to each part of the operation. Inspired by the extensive and widespread use of network flow algorithms, this research formulates the process route family formation for generalized grouping as a unit capacity minimum cost network flow model. The objective is to minimize dissimilarity (based on the machines required) among the process routes within a family. The proposed model optimally solves the process route family formation problem without pre-specifying the number of part families to be formed. The process route of family formation is the first stage in a hierarchical procedure. For the second stage (machine cell formation), two procedures, a quadratic assignment programming (QAP) formulation and a heuristic procedure, are proposed. The QAP simultaneously assigns process route families and machines to a pre-specified number of cells in such a way that total machine utilization is maximized. The heuristic procedure for machine cell formation is hierarchical in nature. Computational results for some test problems show that the QAP and the heuristic procedure yield the same results.
In the article “Generalized Grouping Problem in Cellular Manufacturing Systems: A Network Flow Approach,” the authors delve into the challenges of the generalized grouping problem in the context of cellular manufacturing systems (CMS). They address the issue of parts having multiple process routes and propose a novel approach inspired by network flow algorithms. By formulating the process route family formation as a unit capacity minimum cost network flow model, they aim to minimize dissimilarity among process routes within a family. This model optimally solves the problem without pre-specifying the number of part families to be formed. Furthermore, the authors present two procedures for the second stage of machine cell formation: a quadratic assignment programming (QAP) formulation and a hierarchical heuristic procedure. They demonstrate through computational results that both approaches yield similar outcomes. Overall, this research offers valuable insights into optimizing process route family formation and machine cell formation in CMS.
Exploring Innovative Solutions for Generalized Grouping in Cellular Manufacturing Systems
In the context of cellular manufacturing systems (CMS), the generalized grouping problem poses unique challenges. This problem arises when parts can follow multiple process routes, where each route consists of a series of machines required for a specific operation. The objective is to form process route families that minimize dissimilarity based on the machines required. In this article, we propose innovative solutions and ideas to tackle this problem and provide insights into improving efficiency and productivity in CMS.
Formulating the Generalized Grouping Problem
Building on the foundation of network flow algorithms, our research formulates the process route family formation as a unit capacity minimum cost network flow model. By leveraging this formulation, we can optimally solve the problem without pre-specifying the number of part families to be formed. This flexibility allows for a more adaptable and dynamic approach to process route family formation.
The process route family formation serves as the first stage in a hierarchical procedure, paving the way for subsequent stages such as machine cell formation. In the next stage, we introduce two procedures – a quadratic assignment programming (QAP) formulation and a heuristic procedure.
Machine Cell Formation: QAP and Heuristic Approach
The QAP formulation and the heuristic procedure work together to assign process route families and machines to a pre-specified number of cells while maximizing total machine utilization.
The QAP approach solves the machine cell formation problem by simultaneously assigning process route families and machines to cells. By formulating it as a mathematical optimization problem, we can determine the best possible assignment that optimizes machine utilization. Experimental results on test problems indicate that the QAP formulation provides promising results.
Alternatively, we propose a heuristic procedure for machine cell formation, which takes a hierarchical approach. This procedure aims to iteratively improve the machine cell formation by refining the initial assignments. While not as optimal as the QAP formulation, the heuristic procedure provides a viable solution that is computationally efficient and yields similar results.
Enhancing Efficiency and Productivity
By addressing the generalized grouping problem in CMS with our proposed solutions, we can enhance efficiency and productivity in manufacturing operations. The ability to form process route families dynamically without pre-specifying the number of families allows for better resource allocation and adaptability to changing demands.
The QAP formulation and the heuristic procedure for machine cell formation provide options for optimizing machine utilization, thus maximizing overall productivity. These solutions enable manufacturers to streamline operations, reduce downtime, and improve throughput.
Conclusion
The generalized grouping problem in cellular manufacturing systems is crucial to address for optimizing efficiency and productivity. By formulating process route family formation as a network flow model and introducing the QAP formulation and the heuristic approach for machine cell formation, we propose innovative solutions to tackle this problem. These solutions offer manufacturers the flexibility and adaptability required in a rapidly changing manufacturing landscape, contributing to improved operational efficiency and productivity.
The paper presented, titled “Generalized Grouping Problem in Cellular Manufacturing Systems,” addresses a significant challenge in manufacturing systems where parts may have multiple process routes. The authors propose a solution to the problem by formulating it as a unit capacity minimum cost network flow model, taking inspiration from the widely used network flow algorithms.
The objective of this research is to minimize dissimilarity among the process routes within a family, based on the machines required. The proposed model offers an optimal solution to the process route family formation problem without the need to pre-specify the number of part families to be formed. This flexibility is an important feature, as it allows for adaptability in real-world manufacturing scenarios where the number of part families may vary.
The process route family formation is considered as the first stage in a hierarchical procedure. The second stage involves machine cell formation, where two procedures are proposed – a quadratic assignment programming (QAP) formulation and a heuristic procedure.
The QAP simultaneously assigns process route families and machines to a pre-specified number of cells, with the aim of maximizing total machine utilization. The heuristic procedure, on the other hand, takes a hierarchical approach to machine cell formation.
The paper provides computational results for several test problems, demonstrating that both the QAP formulation and the heuristic procedure yield the same results. This consistency in results suggests that the heuristic procedure can be a viable alternative to the more computationally intensive QAP formulation.
Overall, this research offers a valuable contribution to the field of cellular manufacturing systems. By formulating the generalized grouping problem as a network flow model and proposing efficient procedures for process route family formation and machine cell formation, the authors provide practical solutions that can improve manufacturing efficiency and optimize resource utilization.
Moving forward, it would be interesting to see further research on the application of these proposed methods in real manufacturing environments and the potential for integrating them with other optimization techniques. Additionally, exploring the scalability of the proposed procedures to handle larger and more complex manufacturing systems would be a valuable direction for future work. Read the original article
arXiv:2411.02851v1 Announce Type: new
Abstract: The goal of Multilingual Visual Answer Localization (MVAL) is to locate a video segment that answers a given multilingual question. Existing methods either focus solely on visual modality or integrate visual and subtitle modalities. However, these methods neglect the audio modality in videos, consequently leading to incomplete input information and poor performance in the MVAL task. In this paper, we propose a unified Audio-Visual-Textual Span Localization (AVTSL) method that incorporates audio modality to augment both visual and textual representations for the MVAL task. Specifically, we integrate features from three modalities and develop three predictors, each tailored to the unique contributions of the fused modalities: an audio-visual predictor, a visual predictor, and a textual predictor. Each predictor generates predictions based on its respective modality. To maintain consistency across the predicted results, we introduce an Audio-Visual-Textual Consistency module. This module utilizes a Dynamic Triangular Loss (DTL) function, allowing each modality’s predictor to dynamically learn from the others. This collaborative learning ensures that the model generates consistent and comprehensive answers. Extensive experiments show that our proposed method outperforms several state-of-the-art (SOTA) methods, which demonstrates the effectiveness of the audio modality.
Expert Commentary: Incorporating Audio Modality for Multilingual Visual Answer Localization
The Multilingual Visual Answer Localization (MVAL) task aims to identify a specific segment of a video that answers a given multilingual question. While previous methods have primarily focused on visual and textual modalities, the role of audio modality in videos has often been neglected. This paper introduces the Audio-Visual-Textual Span Localization (AVTSL) method, which integrates audio modality alongside visual and textual representations to enhance the performance of the MVAL task.
The AVTSL method takes advantage of the multi-disciplinary nature of multimedia information systems, specifically in the context of animations, artificial reality, augmented reality, and virtual realities. By incorporating features from three modalities, the proposed method provides a comprehensive understanding of the video content and improves the accuracy of the localization task.
One of the key contributions of this paper is the development of three predictors, each tailored to a specific modality. The audio-visual predictor utilizes both visual and audio features, the visual predictor focuses solely on visual features, and the textual predictor leverages textual representations. This multi-modal approach allows each predictor to capture the unique contributions of their respective modalities, resulting in more accurate predictions.
To ensure consistency across the predicted results, the AVTSL method introduces an Audio-Visual-Textual Consistency module. This module incorporates a Dynamic Triangular Loss (DTL) function, enabling collaborative learning between the predictors. By dynamically learning from each other, the predictors generate consistent and comprehensive answers. This is particularly important in the MVAL task, where the integration of multiple modalities is essential for accurate localization.
Extensive experiments have been conducted to evaluate the performance of the proposed AVTSL method. The results demonstrate that the inclusion of the audio modality significantly improves the performance compared to several state-of-the-art methods. This highlights the importance of considering audio information in addition to visual and textual data for the MVAL task.
In conclusion, the AVTSL method presented in this paper showcases the potential of incorporating audio modality for enhancing the accuracy of the Multilingual Visual Answer Localization task. By leveraging features from multiple modalities and employing collaborative learning, this method provides more comprehensive and consistent answers. The multi-disciplinary nature of this approach aligns with the wider field of multimedia information systems and its applications in animations, artificial reality, augmented reality, and virtual realities.
arXiv:2411.01208v1 Announce Type: new Abstract: Reconstructing a continuous surface from a raw 3D point cloud is a challenging task. Recent methods usually train neural networks to overfit on single point clouds to infer signed distance functions (SDFs). However, neural networks tend to smooth local details due to the lack of ground truth signed distances or normals, which limits the performance of overfitting-based methods in reconstruction tasks. To resolve this issue, we propose a novel method, named MultiPull, to learn multi-scale implicit fields from raw point clouds by optimizing accurate SDFs from coarse to fine. We achieve this by mapping 3D query points into a set of frequency features, which makes it possible to leverage multi-level features during optimization. Meanwhile, we introduce optimization constraints from the perspective of spatial distance and normal consistency, which play a key role in point cloud reconstruction based on multi-scale optimization strategies. Our experiments on widely used object and scene benchmarks demonstrate that our method outperforms the state-of-the-art methods in surface reconstruction.
The article “Reconstructing Continuous Surfaces from Raw 3D Point Clouds: A Multi-Scale Optimization Approach” addresses the challenge of reconstructing a continuous surface from a raw 3D point cloud. Existing methods rely on training neural networks to overfit on single point clouds and infer signed distance functions (SDFs). However, this approach often leads to the smoothing of local details due to the lack of ground truth signed distances or normals, limiting the performance of overfitting-based methods in reconstruction tasks. To overcome this limitation, the authors propose a novel method called MultiPull, which learns multi-scale implicit fields from raw point clouds by optimizing accurate SDFs from coarse to fine. This is achieved by mapping 3D query points into a set of frequency features, enabling the utilization of multi-level features during optimization. Additionally, the authors introduce optimization constraints based on spatial distance and normal consistency, which are crucial for point cloud reconstruction using multi-scale optimization strategies. The experiments conducted on widely used object and scene benchmarks demonstrate that the proposed method outperforms state-of-the-art techniques in surface reconstruction.
Exploring MultiPull: A Novel Method for Point Cloud Reconstruction
Reconstructing a continuous surface from a raw 3D point cloud is a complex task that has gained attention in recent years. Traditional methods often struggle to capture fine details, resulting in smoothed surfaces. To address this limitation, researchers have turned to neural networks. However, these networks also tend to smooth local details due to the lack of ground truth information, hampering their performance in reconstruction tasks.
In light of this challenge, a team of researchers proposes a novel method named MultiPull to learn multi-scale implicit fields from raw point clouds. By optimizing accurate signed distance functions (SDFs) from coarse to fine, MultiPull aims to overcome the limitations of overfitting-based methods.
The Core Idea: Leveraging Multi-Scale Optimization
MultiPull introduces the concept of mapping 3D query points into a set of frequency features, enabling the use of multi-level features during the optimization process. This multi-scale approach allows for a more comprehensive reconstruction, capturing both local and global details of the surface.
To enhance the accuracy of the reconstruction, the researchers also integrate optimization constraints based on spatial distance and normal consistency. These constraints play a crucial role in refining the results by ensuring the spatial relationships between points are properly preserved and the surface normals are consistent.
Outperforming State-of-the-Art Methods
The effectiveness of the MultiPull method was evaluated using widely-used object and scene benchmarks. The results revealed that MultiPull consistently outperforms the state-of-the-art methods in surface reconstruction tasks.
By introducing a multi-scale optimization strategy and incorporating optimization constraints, MultiPull successfully addresses the issue of smoothness in reconstructed surfaces. The method demonstrates the potential for more accurate and detailed point cloud reconstructions, surpassing the current limitations of overfitting-based approaches.
With its innovative approach and promising results, MultiPull could potentially revolutionize point cloud reconstruction, advancing applications such as 3D modeling, virtual reality, and autonomous navigation.
Overall, the MultiPull method represents a significant step forward in the field of point cloud reconstruction. Its ability to preserve fine details while accurately capturing the overall surface structure opens up new avenues for research and application development. Further exploration and optimization of this method could lead to even more advanced and precise reconstructions in the future.
The paper titled “Reconstructing Continuous Surfaces from Raw 3D Point Clouds using MultiPull” addresses the challenging task of reconstructing a continuous surface from a raw 3D point cloud. This is a significant problem in computer vision and robotics, as accurate surface reconstruction is crucial for various applications such as object recognition, scene understanding, and robot manipulation.
The authors highlight the limitations of existing methods that train neural networks to overfit on single point clouds to infer signed distance functions (SDFs). While these methods have shown promising results, they tend to smooth out local details due to the lack of ground truth signed distances or normals. This smoothing effect limits the performance of overfitting-based methods in reconstruction tasks, where preserving fine-grained details is crucial.
To address this issue, the authors propose a novel method called MultiPull, which aims to learn multi-scale implicit fields from raw point clouds. The key idea behind MultiPull is to optimize accurate SDFs from coarse to fine by mapping 3D query points into a set of frequency features. This enables the utilization of multi-level features during the optimization process, allowing for better preservation of local details.
Additionally, the authors introduce optimization constraints from the perspective of spatial distance and normal consistency. These constraints play a crucial role in point cloud reconstruction based on multi-scale optimization strategies. By incorporating these constraints, the proposed method aims to improve the overall quality of the reconstructed surfaces.
The experiments conducted by the authors on widely used object and scene benchmarks demonstrate the effectiveness of their method. They compare the performance of MultiPull with state-of-the-art methods in surface reconstruction and show that MultiPull outperforms these methods. This suggests that the proposed method is capable of achieving more accurate and detailed surface reconstruction compared to existing techniques.
Overall, this paper presents a significant contribution to the field of surface reconstruction from raw 3D point clouds. By addressing the limitations of existing methods and introducing novel techniques, the authors have demonstrated the potential for improving the quality of reconstructed surfaces. Future research in this area could explore further improvements to the MultiPull method, such as incorporating additional constraints or exploring different optimization strategies, to achieve even better results in surface reconstruction tasks. Read the original article
arXiv:2410.23307v1 Announce Type: new
Abstract: Teleparallel description of gravity theories where the gravity is mediated through the tetrad field and consequent torsion provide an alternative route to explain the late time cosmic speed up issue. Generalization of the teleparallel gravity theory with different functional forms of the torsion scalar $T$ leads to $f(T)$ gravity. The role of scalar field played in addressing issues in cosmology and astrophysics has developed an interest in the inclusion of a scalar field along with an interaction potential in the action. Such a generalized gravity theory is dubbed as $f(T,phi)$ theory. We have explored such a gravity theory to reconstruct the interaction potential of the scalar field required for an extended matter bounce scenario. The cosmological implications of the reconstructed scalar field potential are studied considering two viable and well known functional forms of $f(T,phi)$. The energy conditions of these model are discussed to assess the viability of the cosmological models.
Recent research has explored the concept of teleparallel gravity theories as an alternative explanation for the late-time cosmic speed up issue. These theories involve the use of the tetrad field and consequent torsion to mediate gravity. A specific type of teleparallel gravity theory, known as $f(T)$ gravity, has been developed by generalizing the functional form of the torsion scalar $T$.
In this study, a further generalization of the teleparallel gravity theory is considered, incorporating a scalar field $phi$ and an interaction potential. This theory, known as $f(T,phi)$ theory, is explored to reconstruct the interaction potential of the scalar field that is required for an extended matter bounce scenario.
The reconstructed scalar field potentials are then analyzed in terms of their cosmological implications. Two viable and well-known functional forms of $f(T,phi)$ are considered, and the energy conditions of these models are discussed to assess their viability.
Roadmap for the future
1. Further exploration of $f(T)$ gravity
One potential future direction is to continue studying the properties and implications of $f(T)$ gravity theories. This could involve investigating different functional forms of the torsion scalar $T$ and analyzing their effects on the late-time cosmic speed up issue.
2. Investigation of additional scalar field potentials
Expanding on the current study, future research could explore alternative interaction potentials for the scalar field $phi$ in the $f(T,phi)$ theory. This could involve considering different functional forms and analyzing their impact on cosmological models.
3. Experimental confirmation
Another important step is to seek experimental confirmation or observational evidence for the predictions made by the $f(T,phi)$ theory. This could involve analyzing observational data, conducting laboratory experiments, or utilizing other experimental techniques to test the validity of the reconstructed scalar field potential.
4. Assessing the viability of cosmological models
Continued analysis of the energy conditions and other criteria for assessing the viability of cosmological models is crucial. Future research could focus on refining these assessments and applying them to a broader range of models to gain a better understanding of the viability of the $f(T,phi)$ theory.
Challenges and opportunities on the horizon
While the $f(T,phi)$ theory shows promise in addressing the late-time cosmic speed up issue and offering an alternative description of gravity, there are several challenges and opportunities to consider.
Theoretical challenges: Developing a deeper theoretical understanding of the $f(T,phi)$ theory and its implications is essential for further progress. This may involve confronting the theory with other fundamental principles and theories in physics to ensure its consistency.
Experimental challenges: Testing the predictions of the $f(T,phi)$ theory requires advanced experimental techniques and observational data. Experimentalists and observational astronomers will need to collaborate closely with theorists to design and carry out experiments that can confirm or refute the predictions of the theory.
Bridging the gap between theory and observation: Establishing a clear connection between the theoretical framework of the $f(T,phi)$ theory and observational data is essential for its acceptance within the scientific community. Efforts should be made to communicate the theory’s predictions in a way that observational astronomers can test and verify.
Interdisciplinary collaboration: The study of $f(T,phi)$ theory requires collaboration among researchers in different disciplines, including theoretical physics, cosmology, and observational astronomy. Encouraging interdisciplinary collaboration and communication is crucial for making progress in this field.
In conclusion, the $f(T,phi)$ theory offers a potential avenue for explaining the late-time cosmic speed up issue and provides an alternative description of gravity. Future research should focus on further exploring the theory, investigating alternative scalar field potentials, seeking experimental confirmation, and refining the assessments of cosmological models. However, several challenges, including theoretical and experimental hurdles, must be overcome to advance the understanding and acceptance of the $f(T,phi)$ theory.