by jsendak | Nov 4, 2024 | Computer Science
arXiv:2411.00304v1 Announce Type: cross
Abstract: In recent times, Vision-Language Models (VLMs) have been trained under two predominant paradigms. Generative training has enabled Multimodal Large Language Models (MLLMs) to tackle various complex tasks, yet issues such as hallucinations and weak object discrimination persist. Discriminative training, exemplified by models like CLIP, excels in zero-shot image-text classification and retrieval, yet struggles with complex scenarios requiring fine-grained semantic differentiation. This paper addresses these challenges by proposing a unified approach that integrates the strengths of both paradigms. Considering interleaved image-text sequences as the general format of input samples, we introduce a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM’s hidden state. This approach enhances the MLLM’s ability to capture global semantics and distinguish fine-grained semantics. By leveraging dynamic sequence alignment within the Dynamic Time Warping framework and integrating a novel kernel for fine-grained semantic differentiation, our method effectively balances generative and discriminative tasks. Extensive experiments demonstrate the effectiveness of our approach, achieving state-of-the-art results in multiple generative tasks, especially those requiring cognitive and discrimination abilities. Additionally, our method surpasses discriminative benchmarks in interleaved and fine-grained retrieval tasks. By employing a retrieval-augmented generation strategy, our approach further enhances performance in some generative tasks within one model, offering a promising direction for future research in vision-language modeling.
Integration of Generative and Discriminative Approaches in Vision-Language Models
Over the past few years, Vision-Language Models (VLMs) have made significant progress in understanding and generating text based on visual input. However, two predominant paradigms have emerged in training these models, each with its own limitations. Generative training has allowed Multimodal Large Language Models (MLLMs) to tackle various complex tasks, but issues like hallucinations and weak object discrimination still persist. On the other hand, discriminative training, exemplified by models like CLIP, performs well in zero-shot image-text classification and retrieval but struggles with more complex scenarios that require fine-grained semantic differentiation.
This paper proposes a unified approach that integrates the strengths of both paradigms to tackle these challenges. The authors consider interleaved image-text sequences as the general format of input samples and introduce a structure-induced training strategy that imposes semantic relationships between these input samples and the MLLM’s hidden state. By doing so, they enhance the model’s ability to capture global semantics and distinguish fine-grained semantics.
One interesting aspect of this approach is the use of dynamic sequence alignment within the Dynamic Time Warping framework. This helps align the image and text sequences, allowing for better understanding of the relationships between them. Additionally, the authors propose a novel kernel for fine-grained semantic differentiation, further enhancing the model’s discriminative abilities.
The multi-disciplinary nature of this work is evident in its connections to various fields. In the wider field of multimedia information systems, this work contributes by providing a more effective way of combining visual and textual information. By addressing the limitations of generative and discriminative models, the proposed approach opens up new possibilities for applications in animations, artificial reality, augmented reality, and virtual realities.
For example, in animations, this approach could improve the generation of text captions or dialogue based on visual scenes. It could also enhance the understanding of complex scenarios in virtual reality environments, allowing for more immersive experiences. Furthermore, in augmented reality applications, the integration of generative and discriminative approaches could enable better object recognition and understanding of the surrounding environment.
The experiments conducted by the authors demonstrate the effectiveness of their approach, achieving state-of-the-art results in multiple generative tasks, particularly those requiring cognitive and discrimination abilities. Additionally, their method surpasses discriminative benchmarks in interleaved and fine-grained retrieval tasks.
By employing a retrieval-augmented generation strategy, the authors further enhance the performance of generative tasks within one model, offering a promising direction for future research in vision-language modeling. This integration of retrieval and generation could lead to breakthroughs in areas such as interactive storytelling, where the model can generate text based on retrieved information from a large knowledge base.
In conclusion, the unified approach proposed in this paper addresses the challenges of generative and discriminative training in Vision-Language Models by integrating the strengths of both paradigms. The multi-disciplinary nature of this work allows it to have implications in the broader field of multimedia information systems and its related domains, such as animations, artificial reality, augmented reality, and virtual realities. The experiments presented demonstrate the effectiveness of the proposed approach, and the retrieval-augmented generation strategy opens up exciting possibilities for future research in vision-language modeling.
Read the original article
by jsendak | Oct 29, 2024 | DS Articles
From prompt engineering to model tuning and compression, explore five ways to make your language model improve its responses.
Towards Building Better Language Models: A Comprehensive Exploration and Analysis
Language models power a variety of applications right from search engines to chatbots, machine translation services, and many more. The quality of these applications hinges on how effective and robust the underlying language model is. This article explores five key areas that can significantly enhance language model responses.
The Areas of Focus
- Prompt Engineering
- Model Tuning
- Model Compression
- Utilizing Contextual Information
- Knowledge Integration
Long term implications
In the long run, these areas of focus could change the landscape of language models. With better prompts, machine learning could become more precise, leading to more accurate responses and less need for human intervention. This could save companies significant time and resources while improving customer satisfaction.
Model tuning can lead to advanced adjustments in the way language models process information. As the tuning process becomes more sophisticated, language models will likely be better at processing complex queries, understanding context, and producing accurate results.
Model compression could make high-performance language models accessible and affordable to a broader user base. This can democratize AI technology, making it viable for smaller businesses and developers.
Future developments
The increased understanding and manipulation of context within language models could lead to the development of models that can fully comprehend and respond to complex scenarios. The addition of more nuanced analysis of context can potentially make language models indistinguishable from human conversation.
“Knowledge integration is another frontier that has the potential to drive significant developments in language modeling. It involves integrating vast amounts of data from various sources, enabling language models to provide richer, more accurate responses.”
Actionable Advice
- Prompt Engineering – Devote significant resources to develop effective prompts. Experiment with different inputs and measure the outcomes for an optimal set. This will improve your model’s precision and efficiency.
- Model Tuning – Continuously adapt and fine-tune your models using real-world data to enhance their ability to understand complexity and context. This will increase their accuracy and the satisfaction of end users.
- Model Compression – Focus on compressing your models without compromising their performance. This will make your AI technology more accessible and affordable to a wider audience.
- Contextual Information – Make sure to involve and analyze context when training your language models. This will enable models to comprehend and respond to complex scenarios effectively.
- Knowledge Integration – Use as many reliable sources of information as possible. This will enable your language model to provide richer, more accurate responses.
Read the original article
by jsendak | Oct 25, 2024 | AI
arXiv:2410.17283v1 Announce Type: new
Abstract: Recently, the remarkable success of ChatGPT has sparked a renewed wave of interest in artificial intelligence (AI), and the advancements in visual language models (VLMs) have pushed this enthusiasm to new heights. Differring from previous AI approaches that generally formulated different tasks as discriminative models, VLMs frame tasks as generative models and align language with visual information, enabling the handling of more challenging problems. The remote sensing (RS) field, a highly practical domain, has also embraced this new trend and introduced several VLM-based RS methods that have demonstrated promising performance and enormous potential. In this paper, we first review the fundamental theories related to VLM, then summarize the datasets constructed for VLMs in remote sensing and the various tasks they addressed. Finally, we categorize the improvement methods into three main parts according to the core components of VLMs and provide a detailed introduction and comparison of these methods.
The Rise of Visual Language Models in Remote Sensing
Artificial intelligence (AI) has been a groundbreaking field, and recent advancements in visual language models (VLMs) have ignited a renewed enthusiasm in AI research. These VLMs differ from traditional AI approaches by formulating tasks as generative models rather than discriminative models, allowing for a more nuanced understanding of complex problems. In the field of remote sensing (RS), the integration of VLMs has shown immense potential and promising performance.
The Multi-disciplinary Nature of VLMs
One of the key factors driving the interest in VLMs is their multi-disciplinary nature. By aligning language with visual information, VLMs offer a bridge between computer vision and natural language processing, two traditionally separate domains. This integration opens up new avenues for exploration and enables the handling of more challenging problems in remote sensing.
Remote sensing, as a highly practical domain, deals with the analysis and interpretation of images captured from aerial or satellite platforms. The incorporation of VLMs in this field brings together expertise from computer vision, linguistics, and geospatial analysis. This interdisciplinary approach not only enhances the accuracy of remote sensing methods but also unlocks new possibilities for understanding and utilizing the vast amount of data collected through remote sensing technologies.
Dataset Construction for VLMs in Remote Sensing
In order to train and evaluate VLMs for remote sensing applications, various datasets have been constructed. These datasets are specifically designed to capture the unique characteristics and challenges of the remote sensing domain. They often consist of large-scale annotated images paired with corresponding textual descriptions to enable the learning of visual-linguistic relationships.
These datasets play a crucial role in advancing the field by providing standardized benchmarks for evaluating the performance of different VLM-based methods. By training VLMs on these datasets, researchers can leverage the power of deep learning to extract meaningful information from remote sensing imagery in a language-aware manner.
Improvement Methods for VLMs in Remote Sensing
Improvement methods for VLMs in remote sensing can be categorized into three main parts based on the core components of VLMs: language modeling, visual feature extraction, and fusion strategies. Each part plays a crucial role in enhancing the performance and capabilities of VLMs in remote sensing applications.
- Language Modeling: By refining language modeling techniques specific to remote sensing, researchers can improve the understanding and generation of textual descriptions for remote sensing imagery. This includes techniques such as fine-tuning pre-trained language models on remote sensing data, exploring novel architectures tailored to the domain, and leveraging contextual information from geospatial data.
- Visual Feature Extraction: Extracting informative visual features from remote sensing imagery is essential for training effective VLMs. Researchers have developed various deep learning architectures to extract hierarchical representations from imagery, capturing both low-level details and high-level semantics. Techniques such as convolutional neural networks (CNNs) and transformers have shown great potential in this regard.
- Fusion Strategies: Incorporating both visual and linguistic modalities effectively requires robust fusion strategies. Methods such as co-attention mechanisms and cross-modal transformers enable the alignment and integration of visual and textual information, allowing for a more comprehensive understanding of remote sensing imagery.
The Future of VLMs in Remote Sensing
The integration of visual language models in remote sensing holds immense potential for the field’s advancement. As researchers continue to explore and refine the methodologies, the future of VLMs in remote sensing is poised for significant breakthroughs.
One of the key areas of development is the expansion of the VLM-based RS methods to handle more complex tasks. Currently, VLMs have shown promise in tasks such as image captioning, land cover classification, and object detection in remote sensing imagery. However, with further advancements, we can expect VLMs to tackle even more challenging tasks, such as change detection, anomaly detection, and semantic segmentation.
Moreover, the integration of VLMs with other cutting-edge technologies such as graph neural networks and reinforcement learning could further enhance the capabilities of remote sensing analysis. By leveraging the strengths of these different approaches, researchers can devise more robust and accurate methods for extracting valuable insights from remote sensing data.
Overall, the rising trend of visual language models in remote sensing represents a convergence of disciplines and methodologies. This multi-disciplinary approach not only opens up new opportunities for addressing complex remote sensing problems but also fosters collaborations between different fields, leading to innovative solutions and advancements in the broader domain of artificial intelligence.
Read the original article
by jsendak | Jun 14, 2024 | DS Articles

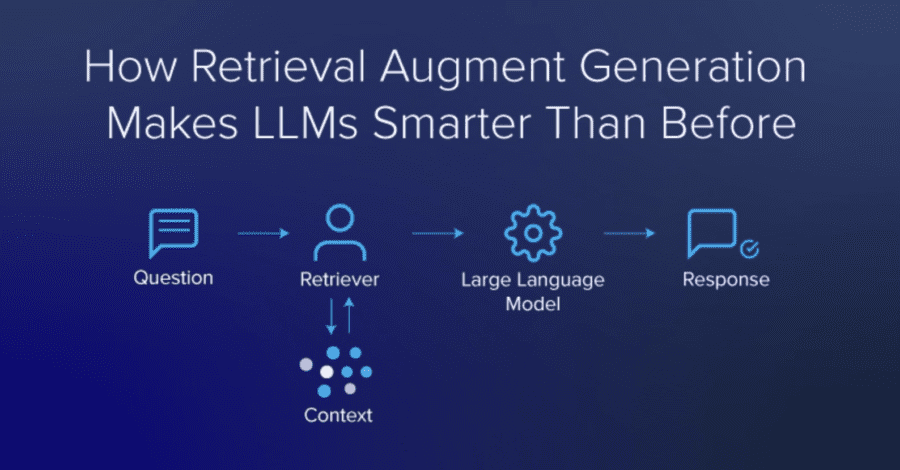
By feeding LLMs the necessary domain knowledge, prompts can be given context and yield better results. RAG can decrease hallucination along with several other advantages.
Implications and Future Developments of LLMs and RAG
Recent technological advancements brought about the intensive use of Language Modeling based on large-pretrained models (LLMs). By feeding these LLMs with the necessary domain knowledge, we can give context to prompts and thus incentivize better result yield. Additionally, with the introduction of the Retrieval-Augmented Generation (RAG), it’s possible to further minimize hallucination – the phenomenon where AI generates information that isn’t factually true or relevant. These provide the user with several considerable advantages.
Long-term Implications
The key implications are bound to profoundly influence the future of artificial intelligence, specifically the facets of machine learning, natural language processing, and automated systems:
- A Shift Towards More Accurate AI Outputs: With reduced hallucination, AI systems powered by LLMs and RAG could deliver more accurate and valid data outputs. This would generate dependency and trust in AI systems for high-stakes data-driven decision making.
- Enhanced Domain-Specific AI Interactions: By feeding LLMs necessary domain knowledge, AI interactions could become more domain-specific and context-aware. This will offer users personalized, relevant, and meaningful AI experiences.
- Smooth Automation: The union of LLMs and RAG could facilitate smoother automated systems across sectors like healthcare, finance, and customer service, providing more efficient and reliable operations.
Future Developments
The marriage of LLMs and RAG signals a promising future for artificial intelligence. Important developments could include:
- AI Evolution: As technology continues to evolve, these models might soon showcase advanced features that can handle complex context manipulation, further enhancing AI performance.
- New AI Algorithms: The success of RAG might pave the way for the creation of new algorithms to improve AI output and efficiency.
- Widespread Acceptance: With more reliability and accuracy, AI could gain more acceptance and widespread use across diverse industries for various applications.
Actionable Advice
Considering the potential benefits of integrating RAG with LLMs and the promising future developments, it’s advisable for organizations and individuals keen on leveraging AI to:
- Invest in Research: Invest in understanding the nuances of RAG and the operation of LLMs. This will allow a smooth transition towards these improved AI systems and keep abreast with the evolving AI technology.
- Align with Domain-Specific Needs: Identify the specific context or domain area where AI can be implemented. Provide the necessary domain knowledge to the LLMs to enhance the quality of AI interactions.
- Prepare for Automation: Start preparing for the transition to automation. Adopt an open mindset toward changes that can lead to improved efficiency and reliability.
Read the original article
by jsendak | Jun 9, 2024 | AI
The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and…
deployment. However, a recent study challenges this assumption and highlights the environmental impact and cost associated with training and deploying large language models. This article delves into the core themes of this study, exploring the limitations of scaling laws and the need for more sustainable and efficient approaches in the development of LLMs. It sheds light on the growing concerns regarding the carbon footprint and energy consumption of these models, prompting a call for reevaluating the trade-offs between model size, performance, and environmental impact. By examining the potential solutions and alternative strategies, this article aims to provide readers with a comprehensive overview of the ongoing debate surrounding the design and deployment of large language models in a resource-constrained world.
The Scaling Laws: A New Perspective on Large Language Models
Introduction
The scaling laws have become the de facto guidelines for designing large language models (LLMs). These laws, which were initially studied under the assumption of unlimited computing resources for both training and inference, have shaped the development and deployment of cutting-edge models like OpenAI’s GPT-3. However, as we strive to push the boundaries of language understanding and generation, it is crucial to reexamine these scaling laws in a new light, exploring innovative solutions and ideas to overcome limitations imposed by resource constraints.
Unveiling the Underlying Themes
When we analyze the underlying themes and concepts of the scaling laws, we find two key factors at play: compute and data. Compute refers to the computational resources required for training and inference, including the processing power and memory. Data, on the other hand, refers to the amount and quality of training data available for the model.
Compute: The existing scaling laws suggest that increasing the compute resources leads to improved performance in language models. However, given the practical limitations on computing resources, we need to explore alternative approaches to enhance model capabilities without an exponential increase in compute. One potential solution lies in optimizing compute utilization and efficiency. By designing more computationally efficient algorithms and architectures, we can achieve better performance without extravagant resource requirements. Additionally, we can leverage advancements in hardware technology, such as specialized accelerators, to boost computational efficiency and circumvent the limitations of traditional architectures.
Data: The other crucial aspect is the availability and quality of training data. It is widely acknowledged that language models benefit from large and diverse datasets. However, for certain domains or languages with limited resources, obtaining a massive amount of quality data may be challenging. Addressing this challenge requires innovative techniques for data augmentation and synthesis. By leveraging techniques such as unsupervised pre-training and transfer learning, we can enhance the adaptability of the models, allowing them to generalize better even with smaller datasets. Additionally, exploring approaches like active learning and intelligent data selection can help in targeted data collection, further improving model performance within resource constraints.
Proposing Innovative Solutions
As we reevaluate the scaling laws and their application in LLM development, it is essential to propose innovative solutions and ideas that go beyond the traditional approach of unlimited computing resources. By incorporating the following approaches, we can overcome resource constraints and pave the way for more efficient and effective language models:
-
Hybrid Models: Instead of relying solely on a single massive model, we can explore hybrid models that combine the power of large pre-trained models with smaller, task-specific models. By using transfer learning to bootstrap the training of task-specific models from the pre-trained base models, we can achieve better results while maintaining resource efficiency.
-
Adaptive Resource Allocation: Rather than allocating fixed resources throughout the training and inference processes, we can develop adaptive resource allocation mechanisms. These mechanisms dynamically allocate resources based on the complexity and importance of different tasks or data samples. By intelligently prioritizing resources, we can ensure optimal performance and resource utilization even with limited resources.
-
Federated Learning: Leveraging the power of distributed computing, federated learning allows training models across multiple devices without compromising data privacy. By collaboratively aggregating knowledge from various devices and training models locally, we can overcome the constraints of centralized resource requirements while benefiting from diverse data sources.
In Conclusion
As we continue to push the boundaries of language understanding and generation, it is crucial to reevaluate the scaling laws under the constraints of limited computing resources. By exploring innovative solutions and ideas that optimize compute utilization, enhance data availability, and overcome resource constraints, we can unlock the full potential of large language models while ensuring practical and sustainable deployment. By embracing adaptive resource allocation, hybrid models, and federated learning, we can shape the future of language models in a way that benefits both developers and users, enabling the advancement of natural language processing in various domains.
“Innovative solutions and adaptive approaches can help us overcome resource limitations and unlock the full potential of large language models in an efficient and sustainable manner.”
inference. These scaling laws, which demonstrate the relationship between model size, computational resources, and performance, have been instrumental in pushing the boundaries of language modeling. However, the assumption of unlimited computing resources is far from realistic in practical scenarios, and it poses significant challenges for implementing and deploying large language models efficiently.
To overcome these limitations, researchers and engineers have been exploring ways to optimize the training and inference processes of LLMs. One promising approach is model parallelism, where the model is divided across multiple devices or machines, allowing for parallel computation. This technique enables training larger models within the constraints of available resources by distributing the computational load.
Another strategy is to improve the efficiency of inference, as this is often a critical bottleneck for deploying LLMs in real-world applications. Techniques such as quantization, which reduces the precision of model parameters, and knowledge distillation, which transfers knowledge from a large model to a smaller one, have shown promising results in reducing the computational requirements for inference without significant loss in performance.
Moreover, researchers are also investigating alternative model architectures that are more resource-efficient. For instance, sparse models exploit the fact that not all parameters in a model are equally important, allowing for significant parameter reduction. These approaches aim to strike a balance between model size and performance, enabling the creation of more practical and deployable LLMs.
Looking ahead, it is crucial to continue research and development efforts to address the challenges associated with limited computing resources. This includes exploring novel techniques for efficient training and inference, as well as investigating hardware and software optimizations tailored specifically for LLMs. Additionally, collaboration between academia and industry will play a vital role in driving advancements in this field, as it requires expertise from both domains to tackle the complexities of scaling language models effectively.
Overall, while the scaling laws have provided valuable insights into the design of large language models, their applicability in resource-constrained scenarios is limited. By focusing on optimizing training and inference processes, exploring alternative model architectures, and fostering collaboration, it is possible to pave the way for the next generation of language models that are not only powerful but also efficient and practical.
Read the original article