by jsendak | Jul 8, 2025 | DS Articles
Learn how to build your own agentic AI application with free tutorials, guides, courses, projects, example code, research papers, and more.
Implications and Future Developments for Building Agentic AI Applications
Currently, we are beginning to see a proliferation of discussions and resources around the topic of developing individual agentic AI applications. This rise in information signifies a growing interest in the technology and implies a great potential for its future development.
Long-term Implications
Looking ahead, the broad availability of tutorials, guides, courses, projects, research papers, and more implies a more levelled playing field, where not just technologically advanced companies but also independent developers and start-ups can contribute to the growth of AI.
With such an approach, faster innovations and improvement in AI technologies can be expected, paving the way for more sophisticated applications across various sectors, from healthcare to entertainment.
Moreover, this trend could lead to an increase in open-source AI projects, boosting collaborative efforts in the AI community.
Possible Future Developments
Given the increased interest in AI development, there are a number of possible future developments to consider. For one, we might see increased collaboration between AI developers across the world. This could lead to the creation of more efficient and effective AI systems that could surpass our present technologies.
Moreover, we might also see a surge in AI literacy, similar to computer literacy in the late 20th century, as more and more individuals learn about this technology and get involved with it.
Actionable Advice
- Stay Updated: With rising trends and rapid advancements in AI development, it is crucial to keep up to date with new learning resources, tutorials, research papers, and other relevant materials. This helps in staying competitive and informed about latest developments.
- Build a Network: Leverage the power of communities. Connect with other AI enthusiasts, join AI development groups, and engage in open-source projects. This not only improves your knowledge and skills but also helps in making valuable connections in the field.
- Invest Time in Learning: Take full advantage of the free online resources available. Participate in online courses, read AI research papers, and invest time in building projects. These activities not only aid in understanding the fundamental concepts of AI but also provide hands-on experience.
In conclusion, with AI development becoming increasingly accessible, the potential for advancement is limitless. It’s up to individuals and organizations alike to harness these opportunities for growth and innovation.
Read the original article

by jsendak | Feb 27, 2025 | DS Articles

We are excited to invite you to the Appsilon Tiny Shiny Hackathon, a four-hour online challenge where developers can showcase their creativity and technical skills by building applications that combine Shiny and AI.
ShinyConf 2025 is coming—are you ready? Join us for an exciting event filled with insights, innovation, and the latest in Shiny!
Whether you are a seasoned developer or just starting with Shiny, this is a great opportunity to push your limits, learn from others, and gain recognition in the Shiny community.
Why Join?
This hackathon is not just about coding. It is about innovation, collaboration, and learning. Here is what you can look forward to:
- Exclusive prizes for top submissions.
- A feature at ShinyConf 2025, putting your work in front of the global Shiny community.
- A one-on-one mentoring session with Appsilon’s Head of Technology, Marcin Dubel.
If you are passionate about building with Shiny and want to experiment with AI, this is your chance to put your skills to the test.
What to Expect
Taking place on Saturday, March 22, 2025, this hackathon runs for just four hours. You will receive access to a GitHub repository with the challenge description at the start, and from there, it is all about designing, developing, and submitting a working Shiny application.
You can participate solo or team up with a partner. Whether you choose R or Python, the goal is the same. Create an impressive Shiny app that meets the challenge criteria. AI tools like ChatGPT, Copilot, Cursor, and Shiny Assistant are not just allowed. They are encouraged.
How to Participate
- Register for the event.
- Make sure you have an active GitHub account.
- (Optional) Join the opening call to get important details.
- Once the hackathon begins, access the GitHub repository with the challenge.
- Fork the repository and start coding.
- Submit your pull request before the deadline with your completed app.
How We Will Evaluate Your Work
Submissions will be reviewed by the Hackathon Committee, made up of Appsilon experts. They will be looking at:
- How well your app meets the challenge objectives.
- Any additional features you build.
- UI design and user experience.
- Code clarity and maintainability.
Prizes and Recognition
Winning is not just about prizes. It is about getting your work in front of the right people. Here is what is at stake:
- Top winners will get a one-on-one mentoring session with Appsilon’s Head of Technology.
- Select participants will be invited to an exclusive roundtable discussion on AI in Shiny development.
- Top three winners will receive a yearly pro-level subscription to an AI tool of their choice.
- Top ten winners will each get a 25 dollar Amazon Gift Card.
Why You Should Join
This hackathon is a chance to learn, build, and connect. It is about testing ideas, getting feedback, and seeing what is possible when you blend Shiny with AI. Whether you are in it for the challenge, the networking, or the fun, this is an opportunity to grow as a developer while being part of something exciting.
Ready to build something amazing? Sign up today and prepare for an intense, rewarding, and inspiring experience.
The post appeared first on appsilon.com/blog/.
Continue reading: Sign Up for Appsilon’s Tiny Shiny Hackathon: Build, Compete, and Win!
Key Analysis and Implications of Appsilon’s Tiny Shiny Hackathon
The Appsilon Tiny Shiny Hackathon is a four-hour online challenge targeting developers across different skill levels. Developers are encouraged to showcase their creativity and technical abilities by building applications that combine the use of Shiny, a web application framework for R programming, and AI. This event is about coding, but also promotes innovation, collaboration, and learning.
Long-term implications
The hackathon by Appsilon not only provides the participants with an opportunity to improve their coding skills and explore new areas in AI and Shiny, but also allows them to gain recognition in the global Shiny community. By featuring the work of top submissions at ShinyConf 2025, Appsilon allows these developers to gain exposure to collaborations or job opportunities.
With AI forming an important element of these applications, this event seems to be in line with the growing trend of integrating AI in various operations. Participants will also get an opportunity to be familiar with AI tools extensively.
Possible future developments
Appsilon’s Tiny Shiny Hackathon seems to be highlighting the role of AI in developing Shiny applications. While it already suggests the use of AI tools like ChatGPT, Copilot, Cursor, and Shiny Assistant, the company might integrate more sophisticated AI tools in the future. Additionally, the selection of a winner based on criteria like code clarity and maintainability could signal the company’s focus on sustainable coding practices.
Actionable advice:
For Developers:
- Keep Improving Your Skills: Continuous learning is crucial in development. Always try to learn more about Shiny and AI. Practice coding and experiment with new projects in preparation for events like this.
- Follow Sustainable Coding Practices: As the selection criteria include attributes like code clarity and maintainability, it’s important to follow best coding practices.
For Appsilon:
- Offer More Learning Resources: To increase the number of participants in the hackathon, consider providing them with more learning resources on Shiny and AI. This will aid those without a prior background in both areas.
- Expand Tools Used for Hackathons: While the hackathon already promotes AI tools, consider introducing more state-of-the-art tools in the future.
Conclusion
The Appsilon Tiny Shiny Hackathon is a great initiative to foster creativity, learning and collaboration among developers. Given the event’s objective of combining Shiny with AI, it stands as a testament to the growing importance of integrating AI in our daily operations and future projects.
Read the original article
by jsendak | Dec 11, 2024 | DS Articles
Introduction
When working with data frames in R, finding rows containing maximum values is a common task in data analysis and manipulation. This comprehensive guide explores different methods to select rows with maximum values in specific columns, from base R approaches to modern dplyr solutions.
Understanding the Basics
Before diving into the methods, let’s understand what we’re trying to achieve. Selecting rows with maximum values is crucial for: – Finding top performers in a dataset – Identifying peak values in time series – Filtering records based on maximum criteria – Data summarization and reporting
Method 1: Using Base R with which.max()
The which.max() function is a fundamental base R approach that returns the index of the first maximum value in a vector.
# Basic syntax
# which.max(df$column)
# Example
data <- data.frame(
ID = c(1, 2, 3, 4),
Value = c(10, 25, 15, 20)
)
max_row <- data[which.max(data$Value), ]
print(max_row)
Advantages:
- Simple and straightforward
- Part of base R (no additional packages needed)
- Memory efficient for large datasets
Method 2: Traditional Subsetting Approach
This method uses R’s subsetting capabilities to find rows with maximum values:
# Syntax
# df[df$column == max(df$column), ]
# Example
max_rows <- data[data$Value == max(data$Value), ]
print(max_rows)
Method 3: Modern dplyr Approach with slice_max()
The dplyr package offers a more elegant solution with slice_max():
library(dplyr)
# Basic usage
# df %>%
# slice_max(column, n = 1)
# With grouping
data %>%
slice_max(Value, n = 1)
Handling Special Cases
Dealing with NA Values
# Remove NA values before finding max
df %>%
filter(!is.na(column)) %>%
slice_max(column, n = 1)
Multiple Maximum Values
# Keep all ties
df %>%
filter(column == max(column, na.rm = TRUE))
Best Practices
- Always handle NA values explicitly
- Document your code
- Consider using tidyverse for complex operations
- Test your code with edge cases
Your Turn!
Try solving this problem:
# Create a sample dataset
set.seed(123)
sales_data <- data.frame(
store = c("A", "A", "B", "B", "C", "C"),
month = c("Jan", "Feb", "Jan", "Feb", "Jan", "Feb"),
sales = round(runif(6, 1000, 5000))
)
# Challenge: Find the store with the highest sales for each month
Click to see the solution
Solution:
library(dplyr)
sales_data %>%
group_by(month) %>%
slice_max(sales, n = 1) %>%
ungroup()
Quick Takeaways
which.max() is best for simple operations- Use
df[df$column == max(df$column), ] for base R solutions
slice_max() is ideal for modern, grouped operations- Always consider NA values and ties
- Choose the method based on your specific needs
FAQs
-
Q: How do I handle ties in maximum values? A: Use slice_max() with n = Inf or filter with == to keep all maximum values.
-
Q: What’s the fastest method for large datasets? A: Base R’s which.max() is typically fastest for simple operations.
-
Q: Can I find maximum values within groups? A: Yes, use group_by() with slice_max() in dplyr.
-
Q: How do I handle missing values? A: Use na.rm = TRUE or filter out NAs before finding maximum values.
-
Q: Can I find multiple top values? A: Use slice_max() with n > 1 or top_n() from dplyr.
Conclusion
Selecting rows with maximum values in R can be accomplished through various methods, each with its own advantages. Choose the approach that best fits your needs, considering factors like data size, complexity, and whether you’re working with groups.
Share and Engage!
Found this guide helpful? Share it with your fellow R programmers! Have questions or suggestions? Leave a comment below or contribute to the discussion on GitHub.
Continue reading: How to Select Row with Max Value in Specific Column in R: A Complete Guide
A Comprehensive Guide to Selecting Rows with Maximum Values in R: Long-term Implications and Future Developments
As More data becomes increasingly accessible and its importance becomes more entrenched in decision-making, the importance for effective data crunching skills becomes paramount. As such, effective use of data analysis packages like R’s ‘dplyr’ and ‘base R’ functions are anticipated to become critical tools for most data scientists and professionals working with data.
Key Methodological Highlights
- Base R approach with which.max(): This is straightforward and memory-efficient especially for large datasets. This function identifies the row with the maximum value.
- The subsetting approach: Another base R method that finds rows with maximum values using the subsetting capability in R.
- dplyr approach with slice_max(): This is a graceful and flexible method especially when dealing with grouped operations.
Implications and Future Predictions
The guide reflects the growing importance of data analysis in various sectors. As such, we can expect:
- Increased demand for R users: Given its versatile and comprehensive data handling capabilities, proficiency in R would be a valuable addition to any CV.
- Enhanced features and functionality: As more people use and contribute to the R community, we can anticipate future versions of R and R packages to sport improved functionality and perhaps even user Interface.
- More comprehensive online learning resources: As proficiency in R becomes more valuable, we can anticipate more widespread availability of learning resources, both free and paid.
Actionable Advice
For Aspiring R users and Data Scientists
Given the above, some actionable steps you can take:
- Learn R: If you haven’t already, considering starting your journey to learn R and its numerous packages for effective data manipulation.
- Navigate through potential problem scenarios: Practice handling potential problems such as handling ‘NA’ values and managing multiple maximum values.
- Join the R community: There are numerous online communities and forums where you can learn, like Stack Overflow and R-bloggers. Consider joining them.
For Educators and Employers
If you’re an educator or employer:
- Include R in your curriculum or job requirements: The importance of R and data manipulation skills is only set to increase. Ensuring students or potential employees have these skills would be a major advantage.
- Emphasize practical application: Encourage learners or employees to not just learn the theory but also practice on datasets, handling various scenarios and problem statements.
In conclusion, the ability to manipulate and handle data using R will gain in importance. Whether you are an existing user of R, or considering to learn, now is the perfect time to get started or brush up your skills. Master these tips and you’ll be well on your way to being proficient in using R for data handling.
Read the original article
by jsendak | Dec 7, 2024 | DS Articles
[This article was first published on
Blog, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
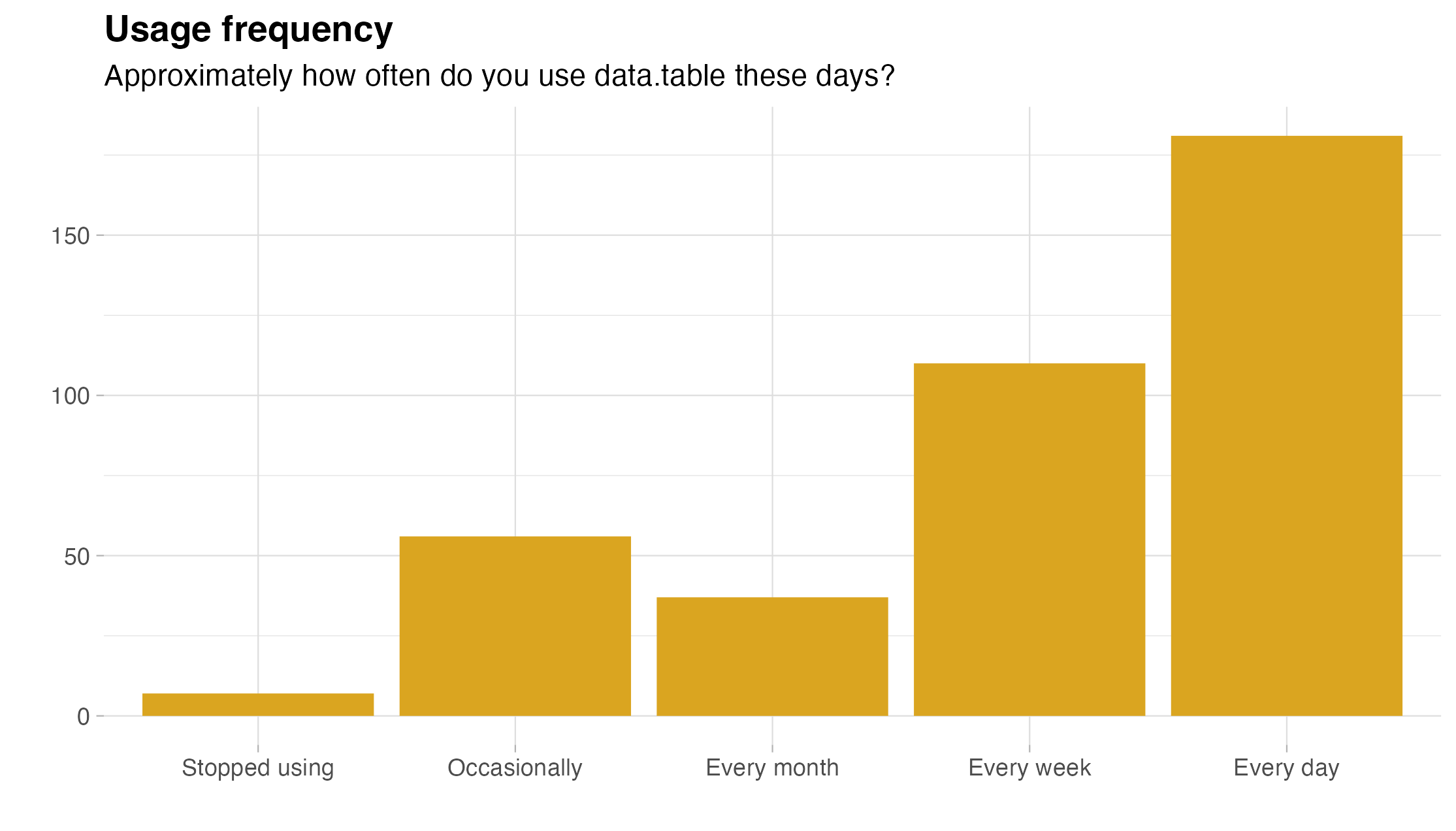
Happy December, R friends!
One of my favorite traditions in the R community is the Advent of Code, a series of puzzles released at midnight EST from December 1st through 25th, to be solved through programming in the language of your choosing. I usually do a few of them each year, and once tried to do every single one at the moment it released!

This year, I know I won’t be able to do it daily, but I’m going to do as many as I can using just data.table solutions.
I’ll allow myself to use other packages when there isn’t any data.table equivalent, but my solutions must be as data.table-y as possible.
I’m going to abuse the blog post structure and update this file throughout the week.
December 1st
Part One
d1 <- fread("day1_dat1.txt")
d1[, V1 := sort(V1)]
d1[, V2 := sort(V2)]
d1[, diff := abs(V1-V2)]
sum(d1$diff)
Part Two
d1[, similarity := sum(V1 == d1$V2)*V1, by = V1]
sum(d1$similarity)
December 2nd
Part One
d1 <- fread("day2_dat1.txt", fill = TRUE)
check_report <- function(vec) {
vec <- na.omit(vec)
has_neg <- vec < 0
has_pos <- vec > 0
inc_dec <- sum(has_neg) == length(vec) | sum(has_pos) == length(vec)
too_big <- max(abs(vec)) > 3
return(inc_dec & !too_big)
}
d1t <- transpose(d1)
deltas <- d1t[-nrow(d1t)] - d1t[2:nrow(d1t)]
res <- apply(deltas, 2, "check_report")
sum(res)
Part Two
test_reports <- function(dat) {
deltas <- dat[-nrow(dat)] - dat[2:nrow(dat)]
res <- apply(deltas, 2, "check_report")
res
}
res <- test_reports(d1t)
for (i in 1:nrow(d1t)) {
res <- res | test_reports(d1t[-i,])
}
sum(res)
Just for fun
I found the use of apply deeply unsatisfying, even though it was fast, so just for fun:
d1t <- transpose(d1)
deltas <- d1t[-nrow(d1t)] - d1t[2:nrow(d1t)]
is_not_pos <- deltas <= 0
is_not_neg <- deltas >= 0
is_big <- abs(deltas) > 3
res_inc <- colSums(is_not_neg | is_big, na.rm = TRUE)
res_dec <- colSums(is_not_pos | is_big, na.rm = TRUE)
sum(res_inc == 0) + sum(res_dec == 0)
Yay.
Continue reading: Advent of Code with data.table: Week One
Advent of Code: Leveraging data.table for Programming Puzzles
The Advent of Code, a series of increasingly complex programming puzzles typically solved in multiple programming languages, holds a prominent place in the R programming community’s festive traditions. The event extends from December 1st through to the 25th and provides users an intriguing platform to showcase their programming skills.
Long-term Implications
The long-term implications of using data.table and R to solve the Advent of Code puzzles are manifold. Firstly, data.table is a highly optimized data manipulation package in R which has a significant speed advantage. This advantage can enable programmers to solve larger-scale complex problems in a fraction of the time it might take using other R packages.
Moreover, the systematic approach to solving Advent of Code puzzles with data.table provides a real-world practical example of how efficient data manipulation techniques can be applied in programming using R. This practice serves as a learning tool, contributing to the improvement of technical programming skills among participants as well as observers.
Future Developments
As R and data.table continue to be optimized and enriched with new features, solving the Advent of Code puzzles with these resources will become increasingly efficient. Additionally, as more individuals participate in this event using R and its packages, more creative and effective solutions will be generated that can act as learning resources for others.
Actionable Advice
- Embrace Challenges: Participate in the Advent of Code event as it offers a platform to challenge yourself, solve problems using R, and learn from others.
- Use Optimized Packages: Utilize the data.table package where necessary for efficient data manipulation and querying. This method can significantly reduce the computation time required to solve complex problems.
- Share Your Solutions: Share your solutions publicly and provide explanations where possible to help others learn from your expertise and approach.
- Stay Updated: Constantly update your knowledge about the latest functions and features in R and its packages. Staying up-to-date allows you to incorporate these features in your solutions effectively.
Read the original article
by jsendak | Nov 29, 2024 | DS Articles
Black Friday is finally here, and so are huge savings for your machine learning journey!
Long-term Implications and Future Developments of Black Friday Machine Learning Discounts
Black Friday represents a significant opportunity for professionals and learners in the field of machine learning. The substantial discounts presented during this period heralds potentials for increased skill-acquisition, future developments, and long-term implications in the industry. But how exactly does this impact the field? Let’s take a close look.
The Impact on Skill-Acquisition
Black Friday deals on machine learning resources mean that more individuals can access premium courses, textbooks, and software tools at a reduced cost. This, in the long run, could translate to:
- Increased skill level: As more individuals are able to access these tools and resources, there’s likely to be an increase in the overall skill level in the machine learning industry. This could correspondingly lead to more innovations and advancements in the field.
- Availability of more experts: With more people learning and upgrading their machine learning skills, the number of experts available for industrial and academic purposes could also increase.
Future Developments in the Industry
Following the availability of more machine learning tools and skilled individuals, the future of the industry could witness:
- Expanded scope of machine learning applications across different industries because of the availability of skilled professionals.
- The development of new machine learning algorithms and models as a result of increased research and practice.
- Proliferation of machine learning startups, leading to more job opportunities and contributions to the economy.
Actionable Advice
In light of these possibilities, here’s what you can do to maximize these Black Friday machine learning deals:
- Invest in high-quality courses: Use this opportunity to enroll in high-end courses that might have been out of reach without the discounts.
- Purchase advanced machine learning tools: Get those cutting-edge machine learning software tools and applications now. Their prices may come at a premium during other parts of the year.
- Scale your learning: If you’re already a professional in the field, consider advanced courses or resources to deepen your expertise.
- Encourage others: You’re not the only one who could benefit from these deals. Encourage colleagues and friends interested in the field to pick up a course or two.
In conclusion, Black Friday deals on machine learning resources present a win-win for individuals and the industry at large. Let’s leverage this opportunity to make significant strides in our machine learning journey and simultaneously drive growth in the industry.
Read the original article