by jsendak | May 6, 2025 | DS Articles
[This article was first published on
Getting Genetics Done, and kindly contributed to
R-bloggers]. (You can report issue about the content on this page
here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Reposted from the original at https://blog.stephenturner.us/p/uv-part-3-python-in-r-with-reticulate.
Two demos using Python in R via reticulate+uv: (1) Hugging Face transformers for sentiment analysis, (2) pyBigWig to query a BigWig file and visualize with ggplot2.
—
This is part 3 of a series on uv. Other posts in this series:
-
uv, part 1: running scripts and tools
-
uv, part 2: building and publishing packages
-
This post
-
Coming soon…
I get the same question all the time from up and coming data scientists in training: “should I use Python or R?” My answer is always the same: it’s not Python versus R, it’s python and R — use whatever tool is best for the job. Last year I wrote a post with resources for learning Python as an R user.
“The best tool for the job” might require multilingual data science. I’m partial to R for data manipulation, visualization, and bioinformatics, but Python has a far bigger user base, and best to not reinvent the wheel if a well-tested and actively developed Python tool already exists.
If I’m doing 90% of my analysis in an R environment but I have some Python code that I want to use, reticulate makes it easy to use Python code within R (from a script, in a RMarkdown/Quarto document, or in packages). This helps you avoid switching contexts and exporting data between R and Python.
You can import a Python package, and call a Python function from that package inside your R environment. Here’s a simple demo using the listdir() function in the os package in the Python standard library.
library(reticulate)
os <- import("os")
os$listdir(".")
Posit recently released reticulate 1.41 which simplifies Python installation and package management by using uv on the back end. There’s one simple function: py_require() which allows you to declare Python requirements for your R session. Reticulate creates an ephemeral Python environment using uv. See the function reference for details.
Here’s a demo. I’ll walk through how to use Hugging Face models from Python directly in R using reticulate, allowing you to bring modern NLP to your tidyverse workflows with minimal hassle. The code I’m using is here as a GitHub gist.
See the code on GitHub
R has great tools for text wrangling and visualization (hello tidytext, stringr, and ggplot2), but imagine we want access to Hugging Face’s transformers library, which provides hundreds of pretrained models, simple pipeline APIs for things like sentiment analysis, named entity recognition, translation, or summarization. Let’s try running sentiment analysis with the Hugging Face transformers sentiment analysis pipeline.
First, load the reticulate library and use py_require() to declare that we’ll need PyTorch and the Hugging Face transformers library installed.
library(reticulate)
py_require("torch")
py_require("transformers")
Even after clearing my uv cache this installs in no time on my MacBook Pro.
Installed 23 packages in 411ms
Next, I’ll import the Python transformers library into my R environment, and create a object to use the sentiment analysis pipeline. You’ll get a message about the fact that you didn’t specify a model so it defaults to a DistilBERT model fine tuned on the Stanford Sentiment Treebank corpora.
transformers <- import("transformers")
analyzer <- transformers$pipeline("sentiment-analysis")
We can now use this function from a Python library as if it were an R function.
analyzer("It was the best of times")
The result is a nested list.
[[1]]
[[1]]$label
[1] "POSITIVE"
[[1]]$score
[1] 0.9995624
How about another?
analyzer("It was the worst of times")
Results:
[[1]]
[[1]]$label
[1] "NEGATIVE"
[[1]]$score
[1] 0.9997889
Let’s write an R function that gives us prettier output. This will take text and output a data frame indicating the overall sentiment and the score.
analyze_sentiment <- function(text) {
result <- analyzer(text)[[1]]
tibble(label = result$label, score = result$score)
}
Let’s try it out on a longer passage.
analyze_sentiment("it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair")
The results:
label score
1 NEGATIVE 0.5121167
Now, let’s create several text snippets:
mytexts <- c("I love using R and Python together!",
"This is the worst API I've ever worked with.",
"Results are fine, but the code is a mess",
"This package manager is super fast.")
And using standard tidyverse tooling, we can create a table showing the sentiment classification and score for each of them:
library(dplyr)
library(tidyr)
tibble(text=mytexts) |>
mutate(sentiment = lapply(text, analyze_sentiment)) |>
unnest_wider(sentiment)
The result:
# A tibble: 4 × 3
text label score
<chr> <chr> <dbl>
1 I love using R and Python together! POSITIVE 1.00
2 This is the worst API I've ever worked with. NEGATIVE 1.00
3 Results are fine, but the code is a mess NEGATIVE 0.999
4 This package manager is super fast. POSITIVE 0.995
This example demonstrates using pyBigWig to query a BigWig file in R for downstream visualization with ggplot2. All the code is here as a GitHub Gist.
See the code on GitHub
First, let’s get this example BigWig file:
x <- "http://genome.ucsc.edu/goldenPath/help/examples/bigWigExample.bw"
download.file(x, destfile = "bigWigExample.bw", mode = "wb")
Now let’s load reticulate and use the pyBigWig library:
library(reticulate)
py_require("pyBigWig")
pybw <- import("pyBigWig")
Now let’s open that example file, look at the chromosomes and their lengths, then query values near the end of chromosome 21.
# Open a BigWig file
bw <- pybw$open("bigWigExample.bw")
# Get list of chromosomes
chroms <- bw$chroms()
print(chroms)
# Query values near the end of chromosome 21
chrom <- "chr21"
start <- chroms[[1]]-100000L
end <- start+1000L
# Get values (one per base)
values <- bw$values(chrom, start, end)
# Close the file
bw$close()
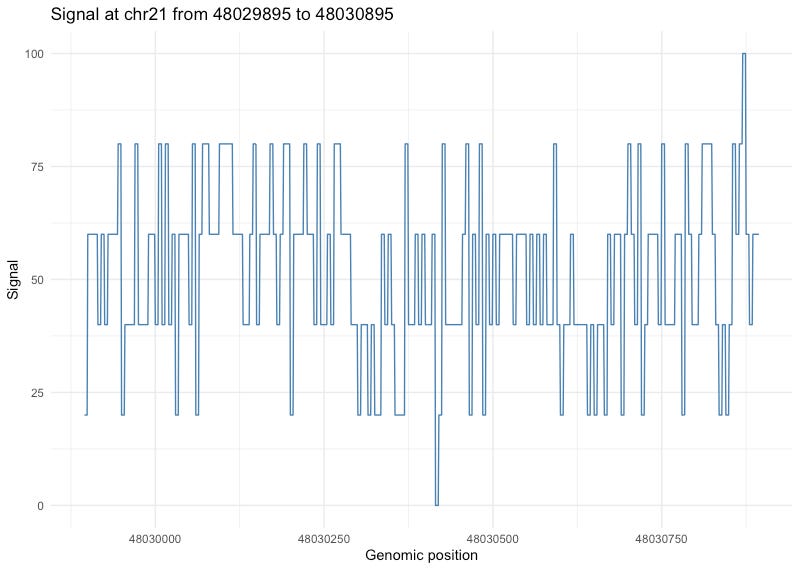
Finally, we can put the results into a data frame and plot it with ggplot2:
# Wrap into data frame
df <- data.frame(position = start:(end - 1),
signal = unlist(values))
# Plot the result
library(ggplot2)
ggplot(df, aes(x = position, y = signal)) +
geom_line(color = "steelblue") +
theme_minimal() +
labs(title = paste("Signal at", chrom, "from", start, "to", end),
x = "Genomic position",
y = "Signal")
Here’s the resulting plot:
Continue reading: Repost: uv, part 3: Python in R with reticulate
Python in R with Reticulate: A Game-Changer for Data Science
The question of whether to use Python or R has perennially plagued data scientists. But the advent of Reticulate, a package that allows for the use of Python within an R environment, offers a resolution. Stephen Turner, a leading voice in this sphere, correctly summarizes that this development shatters the Python versus R dichotomy and takes us into an era of Python and R. By leveraging the strengths of both languages, the Data Science field can unlock unprecedented potential.
What we can glean from current developments
Reticulate simplifies the use of Python within R using simple scripts, RMarkdown/Quarto documents, or packages. By enabling importation of Python packages and their functions within an R environment, Reticulate reduces the need for context-switching and excessive data exports between the two languages. This implies an increasing convergence in data science languages and tools, with data scientists being able to choose which tool best serves their needs irrespective of the programming language.
Long-term implications and future possibilities
Although the highlighted simplicity suggests promising prospects, there are potential future challenges that should be contemplated. For instance, mastering both Python and R to take advantage of the complementarity might be overwhelming for budding data scientists. There might also be integration complications as conflicts may arise due to the languages’ discrepancies. Nonetheless, the overarching implications are vast and exciting in the long term. Data Science might evolve into a more inclusive discipline, indifferent to a data scientist’s language of preference. The resultant flexibility could trigger more creativity and innovation, thereby transforming solution-building by making it more comprehensive and versatile.
Actionable Advice
For Educators:
- Encourage students to learn and appreciate both Python and R by highlighting the unique strengths of each and potentially complement these strengths using Reticulate.
- Adjust the syllabus to cover fundamentals of both languages and dive deeper into each based on the topic or task at hand.
For Practitioners and Industry Professionals:
- Take advantage of the Reticulate package to leverage Python’s extensive libraries and R’s intuitive data handling and visualization capabilities.
- Be open to learning aspects of the “other” language to expand your capabilities and enhance your versatility as a data professional.
For the Data Science Community:
- Promote more discussions on sharing best practices, winning combinations and synergy between the two languages.
- Working closely with the Reticulate development team to iron out potential hiccups and integrating this tool more deeply within the data science workflow.
Conclusion
With the ability to harness the power of R’s robust data manipulation and visualization along with Python’s extensive user base and vast library selection, the Reticulate package substantially expands the horizons of what can be accomplished within a single environment. Though it’s a significant step in data science evolution, collective efforts towards improvement and wider adaptation are crucial to fully realize its vast potential.
Read the original article
by jsendak | May 6, 2025 | AI
arXiv:2505.01441v1 Announce Type: new
Abstract: Large language models (LLMs) have achieved remarkable progress in complex reasoning tasks, yet they remain fundamentally limited by their reliance on static internal knowledge and text-only reasoning. Real-world problem solving often demands dynamic, multi-step reasoning, adaptive decision making, and the ability to interact with external tools and environments. In this work, we introduce ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers), a unified framework that tightly couples agentic reasoning, reinforcement learning, and tool integration for LLMs. ARTIST enables models to autonomously decide when, how, and which tools to invoke within multi-turn reasoning chains, leveraging outcome-based RL to learn robust strategies for tool use and environment interaction without requiring step-level supervision. Extensive experiments on mathematical reasoning and multi-turn function calling benchmarks show that ARTIST consistently outperforms state-of-the-art baselines, with up to 22% absolute improvement over base models and strong gains on the most challenging tasks. Detailed studies and metric analyses reveal that agentic RL training leads to deeper reasoning, more effective tool use, and higher-quality solutions. Our results establish agentic RL with tool integration as a powerful new frontier for robust, interpretable, and generalizable problem-solving in LLMs.
Expert Commentary: The Future of Language Models and Problem Solving
Large language models (LLMs) have made significant strides in complex reasoning tasks, but they are still constrained by their reliance on static internal knowledge and text-only reasoning. Real-world problem solving often requires dynamic, multi-step reasoning and the ability to interact with external tools and environments. In a groundbreaking new study, researchers have introduced ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers), a unified framework that combines agentic reasoning, reinforcement learning, and tool integration for LLMs.
This multi-disciplinary approach represents a significant advancement in the field of artificial intelligence, as it allows models to make autonomous decisions on when, how, and which tools to use within multi-turn reasoning chains. By incorporating outcome-based reinforcement learning, ARTIST learns robust strategies for tool use and environment interaction without the need for step-level supervision.
The extensive experiments conducted on mathematical reasoning and multi-turn function calling benchmarks show that ARTIST outperforms state-of-the-art baselines by up to 22%, demonstrating strong gains on even the most challenging tasks. Detailed studies and metric analyses indicate that agentic RL training leads to deeper reasoning, more effective tool utilization, and higher-quality solutions.
Overall, these results establish agentic RL with tool integration as a powerful new frontier for robust, interpretable, and generalizable problem-solving in LLMs. This innovative framework not only pushes the boundaries of language models but also opens up new possibilities for AI systems to tackle complex real-world problems with agility and efficiency.
Read the original article
by jsendak | Apr 10, 2025 | DS Articles
In this article, we’ll explore what a transformer is, how it originated, why it became so successful that it powered one of the most groundbreaking AI advances, the large language model.
Comprehensive Analysis of Transformers in AI
Transforming the face of Artificial Intelligence (AI), ‘Transformers’ have been heralded as one of the significant advancements powering large language models. Stemming from humble origins, they rose to overwhelming success, heralding a new era for AI applications. This analysis delves into the nuances of transformers in AI, their origins, their journey from inception to recognition, and the consequences of their significant contribution in powering a groundbreaking AI advance – the large language model.
Origins of Transformers
The inception story of transformers traces back to a research paper, “Attention is All You Need”, published by Google Brain in 2017. The paper introduced the transformer model, a novel approach that assisted in solving sequence-to-sequence tasks more efficiently than its predecessors. The innovation proposed in the paper rested on the principle of ‘attention mechanism’, i.e., a method that identifies which parts of the input are vital to the output.
The Rise to Success
Transformers’ success didn’t happen overnight. Offering significant advancements over the previous recurrent neural networks (RNNs), transformers introduced the self-attention mechanism, which allows models to consider different words in a sentence regardless of their positions. It surpassed RNNs by eliminating the need for sequential data processing, thus enabling parallelization and improving efficiency. As a result, transformers have changed the landscape of machine translation and natural language processing (NLP).
Powering Large Language Models
Undeniably, transformers’ most significant feat is fueling the development of large language models, such as GPT-3 developed by OpenAI. These AI models can generate human-like text based on the prompts given, and the credit mainly goes to the transformer architecture. GPT-3 is a testament to the effectiveness of this model, showcasing its potential in various applications such as dialog systems, content generation, and translation among others.
Long-term Implications
The success of transformers in AI has far-reaching implications. From shaping the future of NLP to revolutionizing the workings of machine learning, transformers have revolutionized AI in numerous ways. They have paved the way for a more efficient and nuanced processing of language-based tasks, offering unprecedented accuracy and speed. However, they also present challenges such as increasing computational demands and potential misuse risks in scenarios where generated content can be misinterpreted or misused.
Potential Future Developments
As transformers continue to evolve, we can anticipate several advances. We might see improvements in memory efficiency and computational speed, new variations and adaptations of the transformer model, and applications in a broader range of fields such as healthcare, e-commerce, and entertainment.
Actionable Advice
- Invest in Research: Continued investment in research and development can assist in overcoming the challenges posed by transformers and help harness their potential in AI.
- Pursue Ethical AI: Given the possibility of misuse, it’s crucial to dedicate resources to ethical AI practices, ensuring the safe and beneficial use of such technologies.
- Explore New Applications: Look for opportunities to use transformers in sectors beyond NLP, especially where interpreting and processing complex data is required.
In conclusion, the emergence and success of transformers have dramatically shifted the AI landscape. By fueling advances like large language models, they have made a significant impact. However, their journey is still in progress, and there is vast potential for their application in the future.
Read the original article
by jsendak | Feb 7, 2025 | AI
arXiv:2502.03490v1 Announce Type: new
Abstract: Prior work has found that transformers have an inconsistent ability to learn to answer latent two-hop questions — questions of the form “Who is Bob’s mother’s boss?” We study why this is the case by examining how transformers’ capacity to learn datasets of two-hop questions and answers (two-hop QA) scales with their size, motivated by prior work on transformer knowledge capacity for simple factual memorization. We find that capacity scaling and generalization both support the hypothesis that latent two-hop QA requires transformers to learn each fact twice, while two-hop QA with chain of thought does not. We also show that with appropriate dataset parameters, it is possible to “trap” very small models in a regime where they memorize answers to two-hop questions independently, even though they would perform better if they could learn to answer them with function composition. Our findings show that measurement of capacity scaling can complement existing interpretability methods, though there are challenges in using it for this purpose.
Transformers, a popular deep learning model, have been found to struggle with answering latent two-hop questions like “Who is Bob’s mother’s boss?” In this study, researchers aim to uncover the reason behind this inconsistency by examining how transformers’ capacity to learn two-hop question and answer (QA) datasets scales with their size. This investigation is influenced by previous research on transformer knowledge capacity for simple factual memorization.
The first key finding is that both capacity scaling and generalization support the hypothesis that latent two-hop QA necessitates transformers to learn each fact twice. On the other hand, two-hop QA with a chain of thought does not require this redundancy. This suggests that transformers face unique challenges when it comes to learning and answering two-hop questions.
Additionally, the researchers demonstrate that by manipulating dataset parameters, even very small models can be trapped in a state where they memorize answers to two-hop questions separately. This trapping prevents them from utilizing function composition, which would lead to better performance. This finding underscores the importance of dataset design in promoting effective learning and generalization.
Overall, this study highlights the multidisciplinary nature of the concepts explored. To understand the limitations and potential of transformers in tackling complex QA tasks, it is necessary to consider not only their architectural design and size but also the nature of the datasets they are trained on. These findings also showcase the utility of capacity scaling measurement as a complementary approach to enhance interpretability in transformer models. However, there are challenges associated with utilizing capacity scaling for this purpose, which should be carefully addressed in future research.
Read the original article
by jsendak | Jan 26, 2025 | AI
arXiv:2501.13200v1 Announce Type: cross Abstract: Multi-agent reinforcement learning (MARL) demonstrates significant progress in solving cooperative and competitive multi-agent problems in various environments. One of the principal challenges in MARL is the need for explicit prediction of the agents’ behavior to achieve cooperation. To resolve this issue, we propose the Shared Recurrent Memory Transformer (SRMT) which extends memory transformers to multi-agent settings by pooling and globally broadcasting individual working memories, enabling agents to exchange information implicitly and coordinate their actions. We evaluate SRMT on the Partially Observable Multi-Agent Pathfinding problem in a toy Bottleneck navigation task that requires agents to pass through a narrow corridor and on a POGEMA benchmark set of tasks. In the Bottleneck task, SRMT consistently outperforms a variety of reinforcement learning baselines, especially under sparse rewards, and generalizes effectively to longer corridors than those seen during training. On POGEMA maps, including Mazes, Random, and MovingAI, SRMT is competitive with recent MARL, hybrid, and planning-based algorithms. These results suggest that incorporating shared recurrent memory into the transformer-based architectures can enhance coordination in decentralized multi-agent systems. The source code for training and evaluation is available on GitHub: https://github.com/Aloriosa/srmt.
The article “Shared Recurrent Memory Transformer for Multi-Agent Reinforcement Learning” addresses the challenges of achieving cooperation in multi-agent reinforcement learning (MARL) systems. MARL has shown great progress in solving cooperative and competitive problems, but one of the main obstacles is the explicit prediction of agents’ behavior. To overcome this, the authors propose the Shared Recurrent Memory Transformer (SRMT), which extends memory transformers to enable agents to exchange information and coordinate their actions implicitly. The SRMT is evaluated on a Partially Observable Multi-Agent Pathfinding problem and a POGEMA benchmark set of tasks, demonstrating superior performance compared to other reinforcement learning baselines and competitive results on various map scenarios. The incorporation of shared recurrent memory into transformer-based architectures enhances coordination in decentralized multi-agent systems. The source code for training and evaluation is also provided on GitHub.
Enhancing Coordination in Multi-Agent Systems with Shared Recurrent Memory Transformer
Multi-agent reinforcement learning (MARL) has made significant strides in solving complex cooperative and competitive tasks in various environments. However, one of the key challenges in MARL revolves around explicitly predicting agents’ behavior to achieve efficient cooperation. To address this issue, a groundbreaking solution is proposed in the form of the Shared Recurrent Memory Transformer (SRMT). By extending memory transformers to multi-agent settings, SRMT enables agents to implicitly exchange information and coordinate their actions.
Challenges in Multi-Agent Reinforcement Learning
Coordinating the actions of multiple agents in a decentralized environment poses several challenges. Traditional MARL approaches typically require predicting the behavior of other agents explicitly, which can be computationally intensive and restrict the scalability of the system. Moreover, effectively coordinating actions becomes particularly difficult when agents have limited visibility of their environment and receive sparse rewards.
To overcome these challenges, the SRMT framework capitalizes on the power of memory transformers and shared recurrent memory. By pooling and globally broadcasting individual working memories, agents can implicitly exchange information without the need for explicit prediction. This implicit information exchange greatly enhances coordination capabilities in decentralized multi-agent systems.
Evaluation and Performance
The authors evaluate the effectiveness of the SRMT framework in two settings: the Partially Observable Multi-Agent Pathfinding problem and a benchmark set of tasks known as POGEMA. In the Partially Observable Multi-Agent Pathfinding task, agents must navigate through a narrow corridor (referred to as the Bottleneck task). SRMT consistently outperforms various reinforcement learning baselines, especially under sparse rewards. It also demonstrates effective generalization to longer corridors, unseen during training.
When evaluated on the POGEMA maps, including Mazes, Random, and MovingAI, SRMT shows competitiveness with recent state-of-the-art MARL, hybrid, and planning-based algorithms. These results suggest that incorporating shared recurrent memory into transformer-based architectures offers a promising avenue for improving coordination in multi-agent systems.
Conclusion
The Shared Recurrent Memory Transformer (SRMT) presents a novel approach to address the coordination challenges in multi-agent systems. By enabling agents to implicitly exchange information and coordinate their actions, SRMT outperforms existing MARL and planning-based algorithms in various tasks, including navigating narrow corridors and tackling diverse benchmark sets. The results highlight the potential of incorporating shared recurrent memory in transformer-based architectures to enhance coordination and scalability in decentralized multi-agent environments.
For more information and access to the source code for training and evaluation, visit the project’s GitHub repository: https://github.com/Aloriosa/srmt.
The paper titled “Shared Recurrent Memory Transformer for Multi-Agent Reinforcement Learning” introduces a novel approach to address the challenge of achieving cooperation in multi-agent reinforcement learning (MARL) settings. The authors propose the Shared Recurrent Memory Transformer (SRMT), which extends memory transformers to enable agents to exchange information implicitly and coordinate their actions.
Cooperation is a fundamental aspect of MARL, as agents need to coordinate their behaviors to achieve optimal outcomes. Traditionally, explicit prediction of agents’ behavior has been required, which can be computationally expensive and limit scalability. The SRMT approach aims to overcome this limitation by pooling and globally broadcasting individual working memories, allowing agents to share information without explicit predictions.
To evaluate the effectiveness of SRMT, the authors conducted experiments on two different tasks. The first task is the Partially Observable Multi-Agent Pathfinding problem, specifically focusing on a toy Bottleneck navigation task. In this task, agents need to navigate through a narrow corridor. The results show that SRMT consistently outperforms various other reinforcement learning baselines, especially when rewards are sparse. Additionally, SRMT demonstrates effective generalization to longer corridors not seen during training.
The second task involves evaluating SRMT on a benchmark set of tasks known as POGEMA maps. These maps include different scenarios such as Mazes, Random, and MovingAI. The results indicate that SRMT performs competitively with recent MARL, hybrid, and planning-based algorithms on these tasks.
Overall, the findings of this paper suggest that incorporating shared recurrent memory into transformer-based architectures can significantly enhance coordination in decentralized multi-agent systems. The SRMT approach provides a promising solution to the challenge of achieving cooperation in MARL, showcasing improved performance and generalization capabilities.
It is worth noting that the availability of the source code for training and evaluation on GitHub is a valuable contribution to the research community. This allows researchers and practitioners to replicate the experiments and further build upon the proposed approach. Future work in this area could involve applying SRMT to more complex and realistic multi-agent scenarios, as well as exploring potential optimizations or variations of the SRMT architecture.
Read the original article