arXiv:2407.06524v1 Announce Type: cross
Abstract: Recent speech enhancement methods based on convolutional neural networks (CNNs) and transformer have been demonstrated to efficaciously capture time-frequency (T-F) information on spectrogram. However, the correlation of each channels of speech features is failed to explore. Theoretically, each channel map of speech features obtained by different convolution kernels contains information with different scales demonstrating strong correlations. To fill this gap, we propose a novel dual-branch architecture named channel-aware dual-branch conformer (CADB-Conformer), which effectively explores the long range time and frequency correlations among different channels, respectively, to extract channel relation aware time-frequency information. Ablation studies conducted on DNS-Challenge 2020 dataset demonstrate the importance of channel feature leveraging while showing the significance of channel relation aware T-F information for speech enhancement. Extensive experiments also show that the proposed model achieves superior performance than recent methods with an attractive computational costs.
Analysis: Speech Enhancement and Channel-Aware Dual-Branch Conformer
In this article, we discuss recent advancements in speech enhancement methods using convolutional neural networks (CNNs) and transformers. Specifically, the focus is on exploring the correlation between channels of speech features, which has previously been neglected in existing methods. The proposed solution, called Channel-Aware Dual-Branch Conformer (CADB-Conformer), aims to effectively capture long-range time and frequency correlations among different channels to extract channel relation aware time-frequency (T-F) information.
The research highlights the multi-disciplinary nature of the concepts discussed, as it combines techniques from machine learning (CNNs), natural language processing (transformers), and signal processing (speech enhancement). This interdisciplinary approach is crucial in addressing the challenges of analyzing and improving speech signals.
Relevance to Multimedia Information Systems
Speech enhancement plays a vital role in multimedia information systems, where the goal is to process and analyze various forms of multimedia data, including audio. By improving the quality of speech signals, multimedia information systems can provide better user experiences in applications such as voice assistants, audio conferencing, and video streaming. The CADB-Conformer model presented in the article contributes to the advancement of speech enhancement techniques, which is valuable for developing more robust and efficient multimedia information systems.
Influence on Animations, Artificial Reality, Augmented Reality, and Virtual Realities
The advancements in speech enhancement have implications for various multimedia technologies, including animations, artificial reality, augmented reality, and virtual realities. These technologies often involve interactions with users through voice commands or audio-based interfaces. By enhancing the quality of speech signals, CADB-Conformer can improve the accuracy and reliability of voice recognition systems used in animations, artificial reality simulations, augmented reality applications, and virtual reality experiences. This, in turn, enhances the overall immersive and interactive experience for users.
In conclusion, the article introduces the CADB-Conformer model, showcasing its effectiveness in capturing time-frequency information and exploring channel correlations for speech enhancement. The multi-disciplinary approach and its relevance to multimedia information systems, as well as its impact on animations, artificial reality, augmented reality, and virtual realities, make it a significant contribution to the field. Future research in this area could focus on integrating CADB-Conformer with real-time audio processing systems and evaluating its performance in various multimedia applications.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Within only a few years, SHAP (Shapley additive explanations) has emerged as the number 1 way to investigate black-box models. The basic idea is to decompose model predictions into additive contributions of the features in a fair way. Studying decompositions of many predictions allows to derive global properties of the model.
What happens if we apply SHAP algorithms to additive models? Why would this ever make sense?
In the spirit of our “Lost In Translation” series, we provide both high-quality Python and R code.
The models
Let’s build the models using a dataset with three highly correlated covariates and a (deterministic) response.
import numpy as np
import lightgbm as lgb
import shap
from sklearn.preprocessing import PolynomialFeatures
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
#===================================================================
# Make small data
#===================================================================
def make_data(n=100):
x1 = np.linspace(0.01, 1, n)
x2 = np.log(x1)
x3 = x1 > 0.7
X = np.column_stack((x1, x2, x3))
y = 1 + 0.2 * x1 + 0.5 * x2 + x3 + np.sin(2 * np.pi * x1)
return X, y
X, y = make_data()
#===================================================================
# Additive linear model and additive boosted trees
#===================================================================
# Linear model with polynomial terms
poly = PolynomialFeatures(degree=3, include_bias=False)
preprocessor = ColumnTransformer(
transformers=[
("poly0", poly, [0]),
("poly1", poly, [1]),
("other", "passthrough", [2]),
]
)
model_lm = Pipeline(
steps=[
("preprocessor", preprocessor),
("lm", LinearRegression()),
]
)
_ = model_lm.fit(X, y)
# Boosted trees with single-split trees
params = dict(
learning_rate=0.05,
objective="mse",
max_depth=1,
colsample_bynode=0.7,
)
model_lgb = lgb.train(
params=params,
train_set=lgb.Dataset(X, label=y),
num_boost_round=300,
)
SHAP
For both models, we use exact permutation SHAP and exact Kernel SHAP. Furthermore, the linear model is analyzed with “additive SHAP”, and the tree-based model with TreeSHAP.
Do the algorithms provide the same?
R
Python
system.time({ # 1s
shap_lm <- list(
add = shapviz(additive_shap(fit_lm, df)),
kern = kernelshap(fit_lm, X = df[xvars], bg_X = df),
perm = permshap(fit_lm, X = df[xvars], bg_X = df)
)
shap_lgb <- list(
tree = shapviz(fit_lgb, X),
kern = kernelshap(fit_lgb, X = X, bg_X = X),
perm = permshap(fit_lgb, X = X, bg_X = X)
)
})
# Consistent SHAP values for linear regression
all.equal(shap_lm$add$S, shap_lm$perm$S)
all.equal(shap_lm$kern$S, shap_lm$perm$S)
# Consistent SHAP values for boosted trees
all.equal(shap_lgb$lgb_tree$S, shap_lgb$lgb_perm$S)
all.equal(shap_lgb$lgb_kern$S, shap_lgb$lgb_perm$S)
# Linear coefficient of x3 equals slope of SHAP values
tail(coef(fit_lm), 1) # 0.682815
diff(range(shap_lm$kern$S[, "x3"])) # 0.682815
sv_dependence(shap_lm$add, xvars)sv_dependence(shap_lm$add, xvars, color_var = NULL)
shap_lm = {
"add": shap.Explainer(model_lm.predict, masker=X, algorithm="additive")(X),
"perm": shap.Explainer(model_lm.predict, masker=X, algorithm="exact")(X),
"kern": shap.KernelExplainer(model_lm.predict, data=X).shap_values(X),
}
shap_lgb = {
"tree": shap.Explainer(model_lgb)(X),
"perm": shap.Explainer(model_lgb.predict, masker=X, algorithm="exact")(X),
"kern": shap.KernelExplainer(model_lgb.predict, data=X).shap_values(X),
}
# Consistency for additive linear regression
eps = 1e-12
assert np.abs(shap_lm["add"].values - shap_lm["perm"].values).max() < eps
assert np.abs(shap_lm["perm"].values - shap_lm["kern"]).max() < eps
# Consistency for additive boosted trees
assert np.abs(shap_lgb["tree"].values - shap_lgb["perm"].values).max() < eps
assert np.abs(shap_lgb["perm"].values - shap_lgb["kern"]).max() < eps
# Linear effect of last feature in the fitted model
model_lm.named_steps["lm"].coef_[-1] # 1.112096
# Linear effect of last feature derived from SHAP values (ignore the sign)
shap_lm["perm"][:, 2].values.ptp() # 1.112096
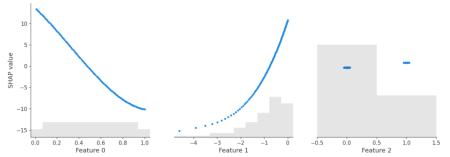
shap.plots.scatter(shap_lm["add"])
SHAP dependence plot of the additive linear model and the additive explainer (Python).
Yes – the three algorithms within model provide the same SHAP values. Furthermore, the SHAP values reconstruct the additive components of the features.
Didactically, this is very helpful when introducing SHAP as a method: Pick a white-box and a black-box model and compare their SHAP dependence plots. For the white-box model, you simply see the additive components, while the dependence plots of the black-box model show scatter due to interactions.
Remark: The exact equivalence between algorithms is lost, when
there are too many features for exact procedures (~10+ features), and/or when
the background data of Kernel/Permutation SHAP does not agree with the training data. This leads to slightly different estimates of the baseline value, which itself influences the calculation of SHAP values.
Final words
SHAP algorithms applied to additive models typically give identical results. Slight differences might occur because sampling versions of the algos are used, or a different baseline value is estimated.
The resulting SHAP values describe the additive components.
Didactically, it helps to see SHAP analyses of white-box and black-box models side by side.
Recent years have seen the rise of SHAP (Shapley Additive Explanations) as the preferred way to investigate black-box models. SHAP’s fundamental premise is to break down model predictions into additive contributions of features in a fair manner. The thorough break down of numerous predictions can uncover global properties of the model.
The application of SHAP to Additive Models
The article proceeds to consider the application of SHAP algorithms to additive models, a concept which, on the face of it, presents an interesting paradox. Analyses are carried out using both high-quality Python and R code, examining model builds using a dataset featuring three significantly correlated covariates and a deterministic response.
Models Built
The authors build additive linear models and additive boosted trees using both R and Python. For both the models, distinct SHAP algorithms have been utilized; Ensuring that the linear model is dissected with additive SHAP and the tree-based model with TreeSHAP.
Are the Results Consistent?
An intriguing question is whether these algorithms would provide similar SHAP values. The answer presented in the paper is a resounding yes. It was demonstrated that individual algorithms yielded the exact SHAP values for each model type. In addition, the SHAP values successfully replicated the additive components of the features.
However, authors noted that there might be a loss in the exact equivalence between the algorithms when there are too many features for exact procedures, or when the background data of Kernel/Permutation SHAP does not agree with the training data. These factors may result in slightly different estimates of the baseline value, which themselves influence the calculation of SHAP values.
Application of SHAP Algorithms to Additive Models: The Implications
For SHAP algorithms applied to additive models, the results are generally identical. Only slight differences might show up if sampling versions of the algorithms are used or if a different baseline value is estimated. These SHAP values describe the additive components, proving the intrinsic value of SHAP as a teaching method. Comparing SHAP analyses of white-box and black-box models side by side serves to facilitate better understanding of this concept.
Suggestions and Ideas
Further Research: Since SHAP has been identified as a potential candidate to study black-box models, it makes sense to conduct additional research in this field and explore its wider implications.
Improving the Algorithms: It is noted that exact equivalence may be lost between algorithms in certain circumstances. Research should focus on remedying these loopholes to attain more accurate results.
Educational Applications: The study proves the didactic value of SHAP for understanding white-box and black-box models. This can form a crucial part of curriculum design in data science and viably be used as a teaching method.
Model Comparison: The paper suggests a direct comparison between the SHAP values of white-box and black-box models. This could be a crucial process in future model development and analyses, leading to more robust modelling methodologies.
Conclusion
The study of SHAP values in addictive models offers compelling insights into the investigation of black-box models. As researchers continue to explore this field, we can anticipate a wealth of advanced developments and improved capacities for analyzing complex data models.
arXiv:2406.18583v1 Announce Type: new Abstract: Lumina-T2X is a nascent family of Flow-based Large Diffusion Transformers that establishes a unified framework for transforming noise into various modalities, such as images and videos, conditioned on text instructions. Despite its promising capabilities, Lumina-T2X still encounters challenges including training instability, slow inference, and extrapolation artifacts. In this paper, we present Lumina-Next, an improved version of Lumina-T2X, showcasing stronger generation performance with increased training and inference efficiency. We begin with a comprehensive analysis of the Flag-DiT architecture and identify several suboptimal components, which we address by introducing the Next-DiT architecture with 3D RoPE and sandwich normalizations. To enable better resolution extrapolation, we thoroughly compare different context extrapolation methods applied to text-to-image generation with 3D RoPE, and propose Frequency- and Time-Aware Scaled RoPE tailored for diffusion transformers. Additionally, we introduced a sigmoid time discretization schedule to reduce sampling steps in solving the Flow ODE and the Context Drop method to merge redundant visual tokens for faster network evaluation, effectively boosting the overall sampling speed. Thanks to these improvements, Lumina-Next not only improves the quality and efficiency of basic text-to-image generation but also demonstrates superior resolution extrapolation capabilities and multilingual generation using decoder-based LLMs as the text encoder, all in a zero-shot manner. To further validate Lumina-Next as a versatile generative framework, we instantiate it on diverse tasks including visual recognition, multi-view, audio, music, and point cloud generation, showcasing strong performance across these domains. By releasing all codes and model weights, we aim to advance the development of next-generation generative AI capable of universal modeling.
The article “Lumina-Next: A Unified Framework for Noise Transformation” introduces Lumina-Next, an improved version of Lumina-T2X, a family of Flow-based Large Diffusion Transformers. Lumina-Next addresses challenges faced by Lumina-T2X, such as training instability, slow inference, and extrapolation artifacts. The authors present the Next-DiT architecture with 3D RoPE and sandwich normalizations as an improved version of the Flag-DiT architecture. They also propose Frequency- and Time-Aware Scaled RoPE for better resolution extrapolation in text-to-image generation. The article further introduces a sigmoid time discretization schedule to reduce sampling steps and the Context Drop method for faster network evaluation. Lumina-Next not only enhances the quality and efficiency of text-to-image generation but also demonstrates superior resolution extrapolation capabilities and multilingual generation. The authors validate Lumina-Next by applying it to various tasks, including visual recognition, multi-view, audio, music, and point cloud generation, showcasing its strong performance across domains. The release of all codes and model weights aims to advance the development of next-generation generative AI.
Lumina-Next: Advancements in Transforming Noise into Various Modalities
The nascent family of Flow-based Large Diffusion Transformers, known as Lumina-T2X, has shown great potential in transforming noise into different modalities conditioned on text instructions. However, it still faces challenges in terms of training instability, slow inference, and extrapolation artifacts. In this paper, we present Lumina-Next, an improved version of Lumina-T2X that overcomes these challenges and offers enhanced generation performance with improved training and inference efficiency.
The Flag-DiT Architecture: Analyzing Suboptimal Components
As a starting point, we conducted a comprehensive analysis of the Flag-DiT architecture utilized in Lumina-T2X. Through this analysis, we identified several suboptimal components that were hindering the performance of the model. To address these issues, we introduced the Next-DiT architecture, which incorporates modifications such as 3D RoPE and sandwich normalizations.
Better Resolution Extrapolation with Frequency- and Time-Aware Scaled RoPE
One of the key challenges in text-to-image generation is achieving better resolution extrapolation. To tackle this challenge, we compared different context extrapolation methods in combination with text-to-image generation using 3D RoPE. Based on our comparisons, we proposed Frequency- and Time-Aware Scaled RoPE, a novel approach tailored for diffusion transformers. This method significantly enhances resolution extrapolation capabilities, allowing for more detailed and realistic image generation.
Improving Training Efficiency and Inference Speed
In addition to enhancing generation performance, Lumina-Next addresses the issues of training instability and slow inference. We introduced a sigmoid time discretization schedule to reduce sampling steps in solving the Flow ODE, resulting in faster training. Furthermore, we implemented the Context Drop method to merge redundant visual tokens, leading to faster network evaluation and improved overall sampling speed.
Beyond Text-to-Image Generation: Lumina-Next’s Versatility and Performance
Lumina-Next is not limited to basic text-to-image generation. We demonstrate its versatility and strong performance in various domains, including visual recognition, multi-view generation, audio generation, music generation, and point cloud generation. By applying Lumina-Next to these tasks, we showcase its capabilities and solidify its position as a versatile and powerful generative framework.
Advancing the Development of Next-Generation Generative AI
We believe in the importance of collaboration and knowledge sharing in the field of AI development. As a result, we are releasing all codes and model weights related to Lumina-Next, aiming to contribute to the advancement of next-generation generative AI and universal modeling. By providing access to these resources, we hope to inspire further innovation and exploration in the field.
In conclusion, Lumina-Next represents a significant step forward in the transformation of noise into various modalities. Its improvements in generation performance, training efficiency, inference speed, and versatility make it a promising framework for generative AI. We invite researchers and developers to explore Lumina-Next and contribute to the ongoing progress in this field.
The paper titled “Lumina-Next: Advancements in Flow-based Large Diffusion Transformers” introduces an improved version of the Lumina-T2X model, called Lumina-Next. Lumina-T2X is a family of Flow-based Large Diffusion Transformers that can transform noise into different modalities, such as images and videos, conditioned on text instructions. Although Lumina-T2X shows promising capabilities, it faces challenges like training instability, slow inference, and extrapolation artifacts.
To address these challenges, the authors propose Lumina-Next, which exhibits stronger generation performance while improving training and inference efficiency. They conduct a comprehensive analysis of the Flag-DiT architecture used in Lumina-T2X and identify suboptimal components. They introduce the Next-DiT architecture, which incorporates 3D RoPE (Rotational Positional Encoding) and sandwich normalizations to address these suboptimal components.
Furthermore, the authors focus on enhancing resolution extrapolation, which is the ability to generate high-resolution images from low-resolution prompts. They compare different context extrapolation methods, specifically applied to text-to-image generation with 3D RoPE. They propose Frequency- and Time-Aware Scaled RoPE, tailored for diffusion transformers, to enable better resolution extrapolation.
Additionally, the authors introduce a sigmoid time discretization schedule to reduce the number of sampling steps required to solve the Flow ODE (Ordinary Differential Equation). They also propose the Context Drop method, which merges redundant visual tokens, leading to faster network evaluation and an overall boost in sampling speed.
The improvements made in Lumina-Next not only enhance the quality and efficiency of basic text-to-image generation but also demonstrate superior resolution extrapolation capabilities and multilingual generation. The authors achieve multilingual generation by using decoder-based Language Models (LLMs) as the text encoder, enabling Lumina-Next to generate images based on text instructions in multiple languages, all in a zero-shot manner.
To showcase the versatility of Lumina-Next as a generative framework, the authors instantiate it on diverse tasks, including visual recognition, multi-view generation, audio generation, music generation, and point cloud generation. The results across these domains demonstrate strong performance, highlighting the broad applicability of Lumina-Next.
In an effort to advance the development of next-generation generative AI, the authors release all codes and model weights associated with Lumina-Next. This open-source approach aims to foster collaboration and further advancements in the field of universal modeling.
Overall, Lumina-Next presents significant advancements over its predecessor, addressing key challenges and improving the quality, efficiency, and versatility of generative AI. Its improved generation performance, resolution extrapolation capabilities, and multilingual generation make it a promising framework for various applications, while the release of codes and model weights encourages further research and development in the field. Read the original article
arXiv:2406.09315v1 Announce Type: new Abstract: In this paper, we show how Transformers can be interpreted as dense Expectation-Maximization algorithms performed on Bayesian Nets. Based on the above interpretation, we propose a new model design paradigm, namely Vertical LoRA (VLoRA), which reduces the parameter count dramatically while preserving performance. In VLoRA, a model consists of layers, each of which recursively learns an increment based on the previous layer. We then apply LoRA decomposition to the increments. VLoRA works on the base model, which is orthogonal to LoRA, meaning they can be used together. We do experiments on various tasks and models. The results show that 1) with VLoRA, the Transformer model parameter count can be reduced dramatically and 2) the performance of the original model is preserved. The source code is available at url{https://github.com/neverUseThisName/vlora}
The article “Transformers as Dense Expectation-Maximization Algorithms: Introducing Vertical LoRA” introduces a novel interpretation of Transformers as dense Expectation-Maximization algorithms performed on Bayesian Nets. This interpretation leads to the proposal of a new model design paradigm called Vertical LoRA (VLoRA), which significantly reduces the parameter count while maintaining performance. VLoRA utilizes layers that recursively learn an increment based on the previous layer and applies LoRA decomposition to these increments. The base model of VLoRA is orthogonal to LoRA, allowing them to be used together. The article presents experimental results on various tasks and models, demonstrating that VLoRA successfully reduces the parameter count of the Transformer model while preserving its performance. The source code for VLoRA is also provided for further exploration.
In a new research paper titled “Interpreting Transformers as Expectation-Maximization Algorithms on Bayesian Nets,” a team of scientists presents a groundbreaking perspective on Transformers. By viewing Transformers as dense Expectation-Maximization algorithms performed on Bayesian Nets, the researchers propose a novel model design paradigm called Vertical LoRA (VLoRA). This paradigm offers a significant reduction in parameter count while maintaining performance.
VLoRA introduces a layer-based approach, where each layer learns recursively based on the previous layer. To further optimize the model, the researchers apply LoRA decomposition to the increments. It’s important to note that VLoRA operates on the base model, which is separate from LoRA and can be utilized in conjunction with it.
To validate their proposal, the researchers conducted experiments on various tasks and models. The results revealed two critical findings. Firstly, by implementing VLoRA, they achieved a remarkable reduction in the parameter count of the Transformer model. This reduction in parameters is substantial and holds great potential for memory-efficient implementations. Secondly, the performance of the original model remained intact, demonstrating the effectiveness of VLoRA in generating compact yet powerful models.
If you are interested in exploring the details of VLoRA and implementing it in your own projects, the source code is readily available on GitHub: https://github.com/neverUseThisName/vlora.
This research opens up exciting avenues for future advancements in natural language processing and machine learning. By reimagining Transformers through the lens of dense Expectation-Maximization algorithms on Bayesian Nets, the possibilities for more efficient and effective models are vast. With VLoRA, the field can explore innovative solutions that improve resource allocation and performance optimization.
Conclusion
The researchers’ interpretation of Transformers as dense Expectation-Maximization algorithms performed on Bayesian Nets offers a fresh perspective on the widely used model. Their proposal of Vertical LoRA (VLoRA) as a new model design paradigm presents tremendous potential for reducing parameter count without compromising performance. The experiments conducted on various tasks and models underscore the effectiveness of VLoRA in achieving significant parameter count reduction while maintaining original model performance. Researchers and practitioners alike can now dive into the open-source code available on GitHub and explore the exciting possibilities that VLoRA brings to the table. The future of machine learning and natural language processing just got a whole lot more fascinating.
The paper “Interpreting Transformers as Expectation-Maximization Algorithms on Bayesian Nets and the Introduction of Vertical LoRA (VLoRA)” introduces an innovative model design paradigm called VLoRA that aims to reduce the parameter count of Transformer models while maintaining performance. The authors propose that Transformers can be interpreted as dense Expectation-Maximization (EM) algorithms implemented on Bayesian Nets.
The key idea behind VLoRA is to decompose the model into layers, where each layer recursively learns an increment based on the previous layer. This decomposition is then combined with LoRA decomposition, a technique that has been used in previous work. The authors highlight that VLoRA and LoRA are orthogonal, meaning they can be used in conjunction with each other.
To validate their approach, the authors conducted experiments on various tasks and models. The results demonstrate two important findings. Firstly, by applying VLoRA, the parameter count of the Transformer model can be drastically reduced without sacrificing performance. This reduction in parameters is a significant advantage as it can lead to improved efficiency and scalability in real-world applications. Secondly, the performance of the original model is maintained, indicating that VLoRA does not compromise the model’s ability to learn and generalize.
The availability of the source code on GitHub provides an opportunity for researchers and practitioners to replicate and build upon the proposed methodology. This transparency and reproducibility are crucial for the advancement of the field.
In terms of future directions, it would be interesting to see further analysis and comparisons of VLoRA with existing methods for reducing parameter count in Transformer models. Additionally, investigating the impact of different layer configurations and their effects on performance and parameter reduction could provide valuable insights. Furthermore, extending the evaluation to more diverse tasks and datasets would help assess the generalizability and robustness of VLoRA. Overall, the introduction of VLoRA opens up new possibilities for optimizing the efficiency of Transformer models and presents a promising avenue for future research in this domain. Read the original article
Find out how to fine-tune BERT for sentiment analysis with Hugging Face Transformers. No unnecessary nonsense, just what you need.
Understanding BERT for Sentiment Analysis
In our increasingly digital age, language understanding models such as BERT (Bidirectional Encoder Representations from Transformers) have emerged as game-changers in the realm of natural language processing. A core component of such an understanding involves sentiment analysis, which is crucial in assisting businesses gauge public opinion, measure customer satisfaction, and drive product/service improvements. Nonetheless, fine-tuning such a language model can be complex. Thankfully, Hugging Face Transformers simplify this process. As the title suggests, this article focusses on teaching you how to fine-tune BERT for sentiment analysis with Hugging Face Transformers, without any unnecessary complications.
Long-Term Implications and Future Developments
Embracing technology such as BERT facilitated by Hugging Face Transformers for sentiment analysis carries long-term implications. With accurate sentiment analysis, businesses can enhance customer experience by understanding their needs better and tailoring their approach to meet these needs. In sectors such as politics, sentiment analysis tools like BERT combined with transformers can indicate changing public opinion. This could help in effective policy-making, shaping electoral strategies etc.
As for future developments, we can expect BERT and similar models to become more accurate and nuanced in understanding language semantics. With enhancements in AI and machine learning capabilities, these tools could even start understanding complex human emotions, sarcasm, and irony, making sentiment analysis more reliable and detailed.
Actionable Advice
Invest in understanding BERT: To capitalize on the future possibilities of sentiment analysis, invest in gaining a comprehensive understanding of BERT and how it can be fine-tuned with transformers. This knowledge would be invaluable in predicting and responding constructively to customer sentiment and market trends.
Adopt best practices for sentiment analysis: Strongly consider integrating sentiment analysis into your data analytics repertoire if you haven’t done so already. In addition, ensure balance in your data, handle negations correctly, and utilize the right tools to achieve accurate analysis.
Stay updated on advancements: The field of AI and machine learning is rapidly evolving, implying that BERT and other sentiment analysis tools will continue to improve. Stay at the forefront of these developments to secure a competitive advantage in your industry.
“Knowledge is power. Especially so in a world where data is aplenty and language understanding tools like BERT are becoming critical for businesses.”