Data Engineering ZoomCamp offers free access to reading materials, video tutorials, assignments, homeworks, projects, and workshops.
Data Engineering ZoomCamp: An Overview
Recently, the Data Engineering ZoomCamp has been brought to our attention. It promises free access to a wealth of educational resources for aspiring data engineers. This includes reading materials, video tutorials, assignments, homeworks, projects, workshops, and possibly more.
Implications of The ZoomCamp
The opportunity that Data Engineering ZoomCamp presents is truly groundbreaking. It offers several implications on the future of data engineering education.
Democratization of Education: By offering free access, education becomes more accessible than ever before. As long as individuals have internet connectivity, they can access the necessary resources to learn about data engineering.
Flexible Learning: With video tutorials and reading materials readily available, individuals can learn at their own pace and schedule. This flexibility is essential, especially for individuals juggling between work and studies.
Hands-on Experience: The provision assignments and projects give learners the chance to apply the theory to practice, a key aspect of effective learning in any field.
Community Learning: Workshops enable learners to engage with others and learn together. There is the potential of fostering a community where learners can support each other in their journey.
Potential Future Developments
The era of digitised, accessible education opens up possibilities for future developments within the domain.
Expansion of Fields: Seeing the success of such ventures, it is likely that more disciplines will start offering online free resources in the years to come.
Innovations in Methodology: The adoption and popularity of this model could encourage further innovations in teaching and learning methodologies. This may include interactive online platforms, AI-powered tutors, learning analytics, among other possibilities.
Global Collaboration: Online platforms like the ZoomCamp have the potential to seamlessly integrate international perspectives and resources, fostering global collaboration.
Actionable Advice
For aspiring data engineers or those interested in the field, the ZoomCamp offers an invaluable opportunity. We propose the following actions:
Utilize Resources: Use all available resources comprehensively. Summerize reading materials, actively try to solve assignments and engage with multimedia resources like video tutorials.
Participate in Workshops: Make the most of workshops offered. These are opportunities for interaction and practical problem-solving.
Peer Interaction: Engage with peers and form study groups, enabling collective learning and problem-solving.
Continuous Learning: Continue learning beyond the camp. The future of the sector could see numerous advancements, making it crucial for individuals to stay updated with trends.
How to dramatically improve GPT and related apps such as Google search and internal search boxes, with simple techniques and no training
Enhancing GPT and Related Applications for Optimal Performance
Generalized Pre-training Transformer (GPT) and related applications, such as Google Search and internal search boxes, can be significantly improved through simple techniques that require no training. A deep dive into the future implications of this concept sets us on the path to explore possible advancements and their long-term impact in the tech industry.
Long-Term Implications
The utilization of simple methods for the enhancement of GPT and similar applications is a stepping stone towards a new technology era. These advancements have the potential to revolutionize the kind of results users receive from search engines such as Google.
Over time, this will result in more accurate results which, in turn, eases navigation of various platforms and improves overall user experience. Furthermore, these improvements will affect other sectors, such as data analysis, internet browsing, artificial intelligence development, and much more.
Possible Future Developments
The future is inevitably filled with improvements as technology continues to advance. With GPT and other related applications, the primary development pathway is focused on improved user experience.
Potentially, we could be looking at platforms that integrate user behaviour and preferences into search algorithms. This approach will then deliver highly personalized and relevant search results. Additionally, these applications might integrate more sophisticated natural language processing capabilities enhancing interaction for non tech-savvy users.
Actionable Advice
Invest in Research: Continue to probe around the potentials of GPT and its related applications for your business. The aim should be towards maximizing the use of these tools for an optimal user experience.
Create a Responsive System: Design your system to adapt seamlessly with continuous upgrades on GPT and other related applications.
Prioritize User Experience:Centering your digital development strategy on improving user experience should be paramount. Always ensure that your system stays user-friendly, regardless of the applications you use.
Better user experience is not just about wrapping up complex technology in a pretty user interface. It’s more about intuitively understanding the user’s needs and implementing technology in a way that those needs are met effectively and efficiently.
In conclusion, the future of GPT and related applications is promising. The adoption of simple techniques resulting in significant improvements sets the stage for an exciting technological journey ahead. Therefore, businesses and tech entities must focus on continuously researching and testing these upgrades in a bid to stay ahead of the industry’s ever-evolving curve.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Introduction
In the intricate world of data analysis, understanding and accurately interpreting confidence intervals is akin to mastering a crucial language. These statistical tools offer more than just a range of numbers; they provide a window into the reliability and precision of our estimates. Especially in R, a programming language celebrated for its robust statistical capabilities, mastering confidence intervals is essential for anyone looking to excel in data science.
Confidence intervals allow us to quantify the uncertainty in our estimations, offering a range within which we believe the true value of a parameter lies. Whether it’s the average, proportion, or another statistical measure, confidence intervals give a breadth to our conclusions, adding depth beyond a mere point estimate.
This article is designed to guide you through the nuances of confidence intervals. From their fundamental principles to their calculation and interpretation in R, we aim to provide a comprehensive understanding. By the end of this journey, you’ll not only grasp the theoretical aspects but also be adept at applying these concepts to real-world data, elevating your data analysis skills to new heights.
Let’s embark on this journey of discovery, where numbers tell stories, and estimates reveal truths, all through the lens of confidence intervals in R.
What are Confidence Intervals?
In the realm of statistics, confidence intervals are like navigators in the sea of data, guiding us through the uncertainty of estimates. They are not just mere ranges; they represent a profound concept in statistical inference.
The Concept Explained
Imagine you’re a scientist measuring the growth rate of a rare plant species. After collecting data from a sample of plants, you calculate the average growth rate. However, this average is just an estimate of the true growth rate of the entire population of this species. How can you express the uncertainty of this estimate? Here’s where confidence intervals come into play.
A confidence interval provides a range of values within which the true population parameter (like a mean or proportion) is likely to fall. For instance, if you calculate a 95% confidence interval for the average growth rate, you’re saying that if you were to take many samples and compute a confidence interval for each, about 95% of these intervals would contain the true average growth rate.
Understanding Through Analogy
Let’s use another analogy. Imagine trying to hit a target with a bow and arrow. Each arrow you shoot represents a sample estimate, and the target is the true population parameter. A confidence interval is akin to drawing a circle around the target, within which most of your arrows land. The size of this circle depends on how confident you want to be about your shots encompassing the target.
Key Components
There are two key components in a confidence interval:
Central Estimate: Usually the sample mean or proportion.
Margin of Error: This accounts for the potential error in the estimate and depends on the variability in the data and the sample size. It’s what stretches the point estimate into an interval.
Confidence Level
The confidence level, often set at 95%, is a critical aspect of confidence intervals. It’s a measure of how often the interval, calculated from repeated random sampling, would contain the true parameter. However, it’s crucial to note that this doesn’t mean there’s a 95% chance the true value lies within a specific interval from a single sample.
In the next section, we’ll demonstrate how to calculate confidence intervals in R using a practical example. This hands-on approach will solidify your understanding and show you the power of R in statistical analysis.
Calculating Confidence Intervals in R
To effectively illustrate the calculation of confidence intervals in R, we’ll use a real-world dataset that comes with R, making it easy for anyone to follow along. For this example, let’s use the mtcars dataset, which contains data about various aspects of automobile design and performance.
Getting to Know the Dataset
First, let’s explore the dataset:
library(datasets)
data("mtcars")
head(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
summary(mtcars)
mpg cyl disp hp drat wt qsec
Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0 Min. :2.760 Min. :1.513 Min. :14.50
1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89
Median :19.20 Median :6.000 Median :196.3 Median :123.0 Median :3.695 Median :3.325 Median :17.71
Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7 Mean :3.597 Mean :3.217 Mean :17.85
3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90
Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0 Max. :4.930 Max. :5.424 Max. :22.90
vs am gear carb
Min. :0.0000 Min. :0.0000 Min. :3.000 Min. :1.000
1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
Median :0.0000 Median :0.0000 Median :4.000 Median :2.000
Mean :0.4375 Mean :0.4062 Mean :3.688 Mean :2.812
3rd Qu.:1.0000 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
Max. :1.0000 Max. :1.0000 Max. :5.000 Max. :8.000
This familiarizes us with the structure and content of the dataset. For our example, we’ll focus on the mpg (miles per gallon) variable, representing fuel efficiency.
Calculating a Confidence Interval for the Mean
We’re interested in estimating the average fuel efficiency (mpg) for the cars in this dataset. Here’s how you calculate a 95% confidence interval for the mean mpg:
This code calculates the mean of mpg, the standard error of the mean (se_mpg), and then uses these to compute the confidence interval (ci_mpg). The qt function finds the critical value for the t-distribution, which is appropriate here due to the sample size and the fact we're estimating a mean.
Understanding the Output
The output gives us two numbers, forming the lower and upper bounds of the confidence interval. It suggests that we are 95% confident that the true average mpg of cars in the population from which this sample was drawn falls within this range.
Visualizing the Confidence Interval
Visualization aids understanding. Let’s create a simple plot to show this confidence interval:
library(ggplot2)
ggplot(mtcars, aes(x = factor(1), y = mpg)) +
geom_point() +
geom_errorbar(aes(ymin = ci_mpg[1], ymax = ci_mpg[2]), width = 0.1) +
theme_minimal() +
labs(title = "95% Confidence Interval for Mean MPG",
x = "",
y = "Miles per Gallon (MPG)")
This code produces a plot with the mean mpg and error bars representing the confidence interval.
Next Steps
Now that we’ve demonstrated how to calculate and visualize a confidence interval in R, the next section will delve into interpreting these intervals correctly, a crucial step in data analysis.
Interpreting Confidence Intervals
Understanding how to interpret confidence intervals correctly is crucial in statistical analysis. This section will clarify some common misunderstandings and provide guidance on making meaningful inferences from confidence intervals.
Misconceptions about Confidence Intervals
One widespread misconception is that a 95% confidence interval contains 95% of the data. This is not accurate. A 95% confidence interval means that if we were to take many samples and compute a confidence interval for each, about 95% of these intervals would capture the true population parameter.
Another common misunderstanding is regarding what the interval includes. For instance, if a 95% confidence interval for a mean difference includes zero, it implies that there is no significant difference at the 5% significance level, not that there is no difference at all.
Correct Interpretation
Proper interpretation focuses on what the interval reveals about the population parameter. For example, with our previous mtcars dataset example, the confidence interval for average mpg gives us a range in which we are fairly confident the true average mpg of all cars (from which the sample is drawn) lies.
Context Matters
Always interpret confidence intervals in the context of your research question and the data. Consider the practical significance of the interval. For example, in a medical study, even a small difference might be significant, while in an industrial context, a larger difference might be needed to be meaningful.
Reflecting Uncertainty
Confidence intervals reflect the uncertainty in your estimate. A wider interval indicates more variability in the data or a smaller sample size, while a narrower interval suggests more precision.
In summary, confidence intervals are a powerful way to convey both the estimate and the uncertainty around that estimate. They provide a more informative picture than a simple point estimate and are essential for making informed decisions based on data.
Visual Representation and Best Practices
Effectively working with confidence intervals in R is not just about calculation and interpretation; it also involves proper visualization and adherence to best practices. This section will guide you through these aspects to enhance your data analysis skills.
Visualizing Confidence Intervals
Visual representation is key in making statistical data understandable and accessible. Here are a few tips for visualizing confidence intervals in R:
Use Error Bars: As demonstrated earlier with the mtcars dataset, error bars in plots can effectively represent the range of confidence intervals, providing a clear visual of the estimate's uncertainty.
Overlay on Plots: Add confidence intervals to scatter plots, bar charts, or line plots to provide context to the data points or summary statistics.
Keep it Simple: Ensure that your visualizations are not cluttered. The goal is to enhance understanding, not to overwhelm the viewer.
Best Practices in Calculation and Interpretation
To ensure accuracy and reliability in your use of confidence intervals, follow these best practices:
Check Assumptions: Make sure that the assumptions underlying the statistical test used to calculate the confidence interval are met. For example, normal distribution of data in case of using a t-test.
Understand the Context: Always interpret confidence intervals within the context of your specific research question or analysis. Consider what the interval means in practical terms.
Be Cautious with Wide Intervals: Wide intervals might indicate high variability or small sample sizes. Be cautious in drawing strong conclusions from such intervals.
Use Appropriate Confidence Levels: While 95% is a common choice, consider whether a different level (like 90% or 99%) might be more appropriate for your work.
Avoid Overinterpretation: Don’t overinterpret what your confidence interval tells you. It provides a range of plausible values but does not guarantee that the true value lies within it for any given sample.
Incorporating these visualization techniques and best practices into your work with confidence intervals in R will not only bolster the accuracy of your analyses but also enhance the clarity and impact of your findings. Confidence intervals are a fundamental tool in statistical inference, and mastering their use is key to becoming proficient in data analysis.
Conclusion
We’ve journeyed through the landscape of confidence intervals, uncovering their significance and application in the realm of data analysis. From the basic understanding of what confidence intervals are to their calculation, interpretation, and visualization in R, this guide aimed to provide a comprehensive yet accessible pathway into the world of statistical estimation.
Confidence intervals are more than just a range of numbers; they are a critical tool in statistical inference, offering insights into the reliability and precision of our estimates. Properly calculated and interpreted, they empower us to make informed decisions and draw meaningful conclusions from our data.
Remember, the strength of confidence intervals lies not only in the numbers themselves but also in the story they tell about our data. They remind us of the inherent uncertainty in statistical analysis and guide us in communicating this uncertainty effectively.
As you apply these concepts in R to your own data analysis projects, embrace the nuances of confidence intervals. Let them illuminate your path to robust and reliable statistical conclusions. Continue to explore, practice, and refine your skills in R, and you’ll find confidence intervals becoming an indispensable part of your data analysis toolkit.
Confidence Intervals in R: An Essential Tool for Robust Statistical Analysis
In the contemporary world of big data, acquiring a comprehensive understanding of confidence intervals is critical. They grant us the ability to quantify ambiguity in our estimations, thereby significantly enhancing the precision and accuracy of our conclusions. In this article, we discuss the long-term implications and anticipate future developments associated with confidence intervals in R programming.
What are Confidence Intervals?
Confidence intervals are a critical statistical concept, acting as navigators in the data sea and guiding us through estimates’ uncertainty. They are more than just ranges; confidence intervals represent a profound concept in statistical inference. For instance, a 95% confidence interval means that if we were to take several samples and compute a confidence interval for each, about 95% of these intervals should contain the true population parameter.
The Significance of Confidence Intervals in R Programming
R is a programming language widely celebrated for its robust statistical capabilities. The calculation, interpretation, and visualization of confidence intervals in R can significantly bolster anyone’s data analysis skills. However, understanding what confidence intervals represent in real-world data applications is essential for elevating these data analysis skills to new heights.
The Interpretation and Misinterpretation of Confidence Intervals
It is vital to understand how to interpret confidence intervals correctly. A common misconception is that a 95% confidence interval contains 95% of the data, which is not accurate. Furthermore, if a 95% confidence interval for a mean difference includes zero, it implies that there is no significant difference at the 5% significance level, not that there is no difference at all.
The Future: Confidence Intervals in R
Evolving trends in data analysis indicate that R programming, along with its ability to efficiently calculate and interpret confidence intervals, will continue to be crucial. With Big Data becoming integral to numerous industries, including healthcare, marketing, and finance, the importance of understanding statistical inference cannot be overstated.
Confidence intervals reflect both the estimate and the uncertainty around that estimate. Hence, their proper computation and interpretation can significantly impact decision-making processes, especially in fields where even a minor interpretation error could lead to substantial consequences.
Actionable Advice
Incorporate confidence intervals into your data analysis projects. They not only enhance estimation reliability but also provide an effective way of expressing potential errors.
Visualizing confidence intervals can greatly improve comprehension. Techniques such as error bars and overlayed plots can make your inferences more understandable to a non-expert audience.
Exercise caution when interpreting wide intervals. Large intervals could indicate high variability or small sample sizes, which could influence your conclusions significantly.
Avoid overinterpretation!
Continuously refine your R programming skills. The world of data analysis is dynamic, and staying updated with evolving trends will undoubtedly further your career in this field.
In conclusion, confidence intervals are a powerful tool in statistical inference in R programming. They empower us to make informed decisions and draw meaningful conclusions from our data, guaranteeing the robustness of our investigations and the credibility of our proclamations.
Learn how AI can be used to design fair and efficient EV charging grids by optimizing their placement and pricing.
Analysis of the Use of AI in Designing Efficient EV Charging Grids
The implementation of Artificial Intelligence (AI) is revolutionizing many sectors, including the electric vehicle (EV) industry. AI is demonstrating immense potential in designing fair and efficient EV charging grids by optimizing not only their location but also their pricing – paving the way towards an eco-friendly future.
Long-term Implications
Looking into the future, the application of AI in EV charging grid design could be revolutionary. As the demand for electric vehicles continues to grow, it’s becoming crucial for charging networks to be appropriately distributed and priced. AI analysis can teach us how to efficiently design these crucial networks to offset grid load, prevent long wait times at charging stations, and offer optimal pricing for consumers.
Possible Future Developments
Intelligent Charging Stations: With the integration of AI, charging stations could potentially develop into intelligent hubs that optimize energy distribution based on real-time road traffic, weather conditions, and usage patterns.
Dynamic Pricing Models: AI could design dynamic pricing models that change energies prices according to fluctuating power demand and supply, ultimately helping to stabilize the power grid while ensuring operators still make a profit.
Data-driven Infrastructure Expansion: AI can provide insights into where additional charging stations should be placed by analysing data such as EV sales, driving patterns, and geographic information. This could lead to a more balanced and accessible infrastructure.
Actionable Advice
To benefit from these insights, industries related to electric vehicles and energy should consider the following steps:
Invest in AI Technology: To keep up with growing demands for electric vehicles, industries should consider investing in AI, a powerful tool that can help plan and execute an efficient EV charging network.
Collaborate with AI experts: Expert knowledge is crucial for leveraging AI’s potential. Industries should think about partnerships or hiring professionals who can help navigate the complexities of AI and ensure its effective deployment.
Policy Advocacy: To foster the growth of fair and efficient EV charging networks, it’s also important to advocate for policies at the local, state, and national level that support renewable energies, AI applications, and EV infrastructure.
Data Analysis: Collecting and analyzing data on EV usage, power grid capacities, and consumer behavior can offer invaluable insights for AI applications in this field. Therefore, investing in data analytics is also advisable.
Machine learning can be overwhelming with its variety of tasks. Most tasks can be solved with a few ML algorithms. You need to be aware of which algorithms to select, when to apply them, what parameters to take into consideration, and how to test them. This guide was crafted to provide you with a straightforward… Read More »Choosing the right machine learning algorithm for business success
Understanding Machine Learning for Business Success
One of the most interesting and potentially business-altering developments in recent technology is machine learning (ML). However, with it comes a vast array of tasks that can be overwhelming for a beginner. Knowing which ML algorithms to select, when and how to apply them, what parameters to take into consideration and how to test them is crucial. This analysis is designed not only to unpack the key points in this subject but also explore its long-term implications and possible future developments.
Key Insights from Machine Learning
Algorithm selection: Choosing the right algorithm for your business needs is paramount. Different algorithms serve different purposes and hence, the right one depends directly on the nature of your task and business requirements.
Application of the algorithm: Once you have chosen an appropriate algorithm, you need to know when and how to apply it. This largely depends on the specific problem you are trying to solve.
Consideration of parameters: Taking parameters into account is crucial in creating an effective algorithm. The success of your algorithm could depend on its ability to flexibly accommodate diverse parameters.
Testing: Even the most intricately designed algorithm is useless if not tested properly. Regular testing ensures that your algorithm performs optimally under real-life conditions.
Long-term Implications and Future Developments
Looking at the long-term, machine learning is projected to become an integral part of major industries – from healthcare and finance to retail and transportation. It promises enhanced efficiency and accuracy in decision making, customer service, product development, and so much more.
As technology continues to advance, we can expect ML algorithms to become more sophisticated and adaptable, able to handle larger and more complex datasets. This will subsequently lead to more precise predictions, better decision-making capabilities, and advanced automation across various business processes.
Actionable Advice
Invest in Learning: The landscape of machine learning is continuously evolving. Ensure that you’re staying updated with the latest in the field. Participate in relevant workshops, seminars, and courses.
Choose Wisely: Understand your business needs and choose the right algorithm accordingly. If unsure, consider consulting with an ML expert.
Test Regularly: Test your algorithms regularly to ensure their effectiveness. Use different datasets and scenarios for a comprehensive evaluation.
Be Patient: Implementing and mastering machine learning in your business doesn’t happen overnight. It requires time, effort, and a lot of fine-tuning. So, be patient and stay committed to the process.
In conclusion, it’s evident that leveraging machine learning offers significant potential for business success. However, it’s crucial to understand the complexity of ML, and to thoughtfully and continuously implement it in your business operations.
[This article was first published on modTools, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
It is well known, though often dismissed, that the areas of spatial units (cells, pixels) based on unprojected coordinates (longitude-latitude degrees, arc-minutes or arc-seconds) are wildly inconsistent across the globe. Towards the poles, as the longitude meridians approach each other, the actual ground width of the pixels sharply decreases. So, for non-tropical regions, the actual area covered by these pixels can be quite far from the nominal “approximately 1 km at the Equator” (or 10 km, etc.) which is often referred in biogeography and macroecology studies.
The function below combines several tools from the ‘terra’ R package to compute the (mean or centroid) pixel area for a given unprojected raster map. By default, it also produces a map illustrating the latitudinal variation in the pixel areas.
pixelArea <- function(r, # SpatRaster
type = "mean", # can also be "centroid"
unit = "m", # can also be "km"
mask = TRUE, # to consider only areas of non-NA pixels
map = TRUE) {
# version 1.2 (23 Jan 2024)
stopifnot(inherits(r, "SpatRaster"),
type %in% c("mean", "centroid"))
r_size <- terra::cellSize(r, unit = unit, mask = mask)
if (map) terra::plot(r_size, main = paste0("Pixel area (", unit, "2)"))
areas <- terra::values(r_size, mat = FALSE, dataframe = FALSE, na.rm = FALSE) # na.rm must be FALSE for areas[centr_pix] to be correct
if (type == "mean") {
cat(paste0("Mean pixel area (", unit, "2):n"))
return(mean(areas, na.rm = TRUE))
}
if (type == "centroid") {
r_pol <- terra::as.polygons(r * 0, aggregate = TRUE)
centr <- terra::centroids(r_pol)
if (map) {
if (!mask) terra::plot(r_pol, lwd = 0.2, add = TRUE)
terra::plot(centr, pch = 4, col = "blue", add = TRUE)
}
centr_pix <- terra::cellFromXY(r, terra::crds(centr))
cat(paste0("Centroid pixel area (", unit, "2):n"))
return(areas[centr_pix])
}
}
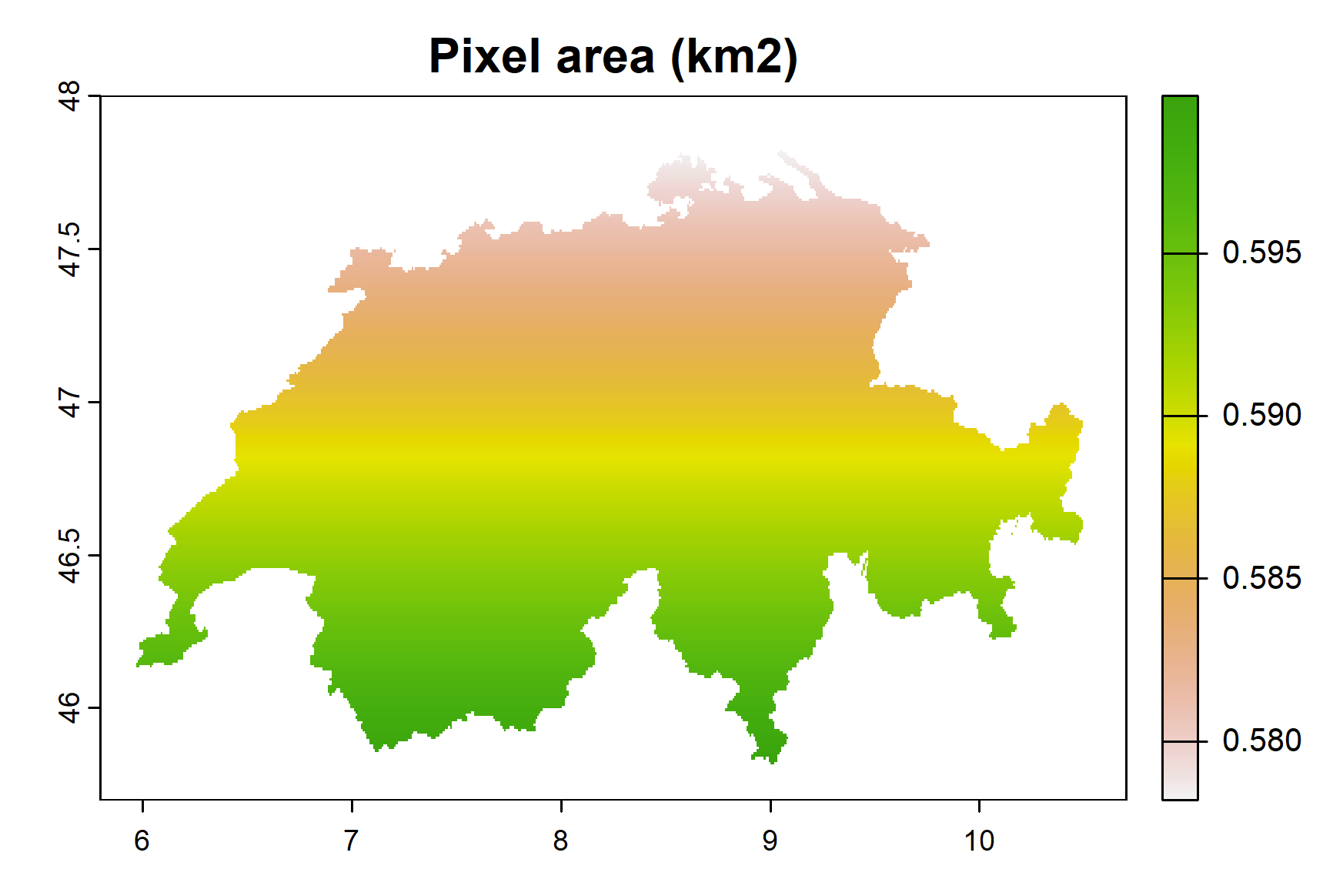
Here’s a usage example for a central European country:
elev_switz <- geodata::elevation_30s("Switzerland", path = tempdir())
terra::plot(elev_switz)
terra::res(elev_switz)
# 0.008333333 degree resolution
# i.e. half arc-minute, or 30 arc-seconds (1/60/2)
# "approx. 1 km at the Equator"
pixelArea(elev_switz, unit = "km")
# Mean pixel area (km2):
# [1] 0.5892033
As you can see, pixel area here is quite different from 1 squared km, and Switzerland isn’t even one of the northernmost countries. So, when using unprojected rasters (e.g. WorldClim, CHELSA climate, Bio-ORACLE, MARSPEC and so many others) in your analysis, consider choosing the spatial resolution that most closely matches the resolution that you want in your studyregion, rather than the resolution at the Equator when this is actually far away. This was done e.g. in this paper (see Supplementary Files – ExtendedMethods.docx).
You can read more details about geographic areas in the help file of the terra::expanse() function. Feedback welcome!
To leave a comment for the author, please follow the link and comment on their blog: modTools.
Considerations and Implications of Inconsistent Pixel Area in Unprojected Maps
The primary proposition in the article is the inconsistency of pixel area in geographic studies and models based on unprojected coordinates, such as longitude and latitude degrees, or arc-seconds and arc-minutes. This issue becomes more pronounced towards the poles as longitude meridians converge. Consequently, the actual ground coverage by each pixel decreases sharply, creating a significant difference between the nominal pixel area, usually referred to as “approximately 1 km at the Equator”, and the actual pixel area.
R’s ‘terra’ Package as a Solution
A potential solution to this problem, as proposed in the article, entails using specific tools from R’s ‘terra’ package. Users can calculate the average or centroid pixel area of an unprojected raster map, emphasizing the variations in pixel areas across latitude. This adjustment can lead to a more accurate representation of spatial data, particularly in non-tropical regions where the discrepancy is most noticeable.
Long-term Implications
In the long run, acknowledging and addressing this inconsistency could lead to significantly improved accuracy in macroecological and biogeographical studies. These enhanced insights could inform more effective conservation strategies and predictive modelling initiatives.
Future Developments
Given the rapid advancements in technology and geospatial analysis tools, it’s reasonable to expect further progress in addressing issues related to unprojected raster maps. Enhanced algorithms for calculating pixel area could lead to even more precise spatial representations. Also, it’s possible that machine learning technologies could be developed to automatically adjust for these discrepancies during data processing.
Actionable Advice
Adjust Pixel Calculation: If your work involves unprojected raster maps, especially involving non-tropical latitudes, consider incorporating tools that calculate the actual pixel area rather than relying on the nominal approximation.
Keep Updated: Stay informed about updates and improvements to geospatial analysis tools and consider integrating them into your work when they become available.
Collaborate: Consider collaborating with technologists focused on machine learning and AI. Their expertise could support the development of automated systems that can address pixel area inconsistencies.
Understanding and addressing the inconsistency of pixel area in raster maps based on unprojected coordinates is crucial in garnering accurate insights in macroecological and biogeographical studies. It is beneficial to leverage geospatial analysis tools which calculate the actual pixel area, and stay abreast with further developments in this field.